 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUPB at SemEval-2021 Task 8: Extracting Semantic Information on Measurements as Multi-Turn Question Answering
Paper and Code
Apr 09, 2021

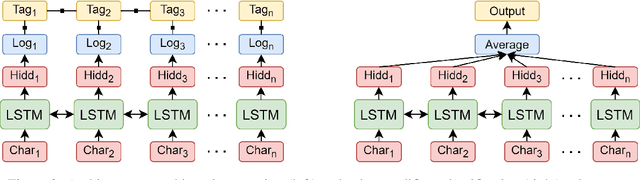

Extracting semantic information on measurements and counts is an important topic in terms of analyzing scientific discourses. The 8th task of SemEval-2021: Counts and Measurements (MeasEval) aimed to boost research in this direction by providing a new dataset on which participants train their models to extract meaningful information on measurements from scientific texts. The competition is composed of five subtasks that build on top of each other: (1) quantity span identification, (2) unit extraction from the identified quantities and their value modifier classification, (3) span identification for measured entities and measured properties, (4) qualifier span identification, and (5) relation extraction between the identified quantities, measured entities, measured properties, and qualifiers. We approached these challenges by first identifying the quantities, extracting their units of measurement, classifying them with corresponding modifiers, and afterwards using them to jointly solve the last three subtasks in a multi-turn question answering manner. Our best performing model obtained an overlapping F1-score of 36.91% on the test set.