 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUPB @ ACTI: Detecting Conspiracies using fine tuned Sentence Transformers
Sep 28, 2023Conspiracy theories have become a prominent and concerning aspect of online discourse, posing challenges to information integrity and societal trust. As such, we address conspiracy theory detection as proposed by the ACTI @ EVALITA 2023 shared task. The combination of pre-trained sentence Transformer models and data augmentation techniques enabled us to secure first place in the final leaderboard of both sub-tasks. Our methodology attained F1 scores of 85.71% in the binary classification and 91.23% for the fine-grained conspiracy topic classification, surpassing other competing systems.
UPB at SemEval-2022 Task 5: Enhancing UNITER with Image Sentiment and Graph Convolutional Networks for Multimedia Automatic Misogyny Identification
May 29, 2022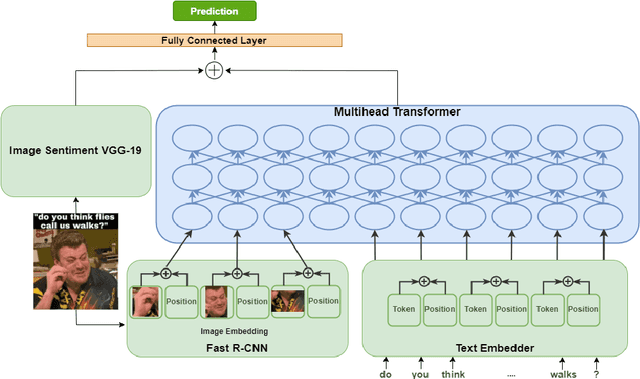
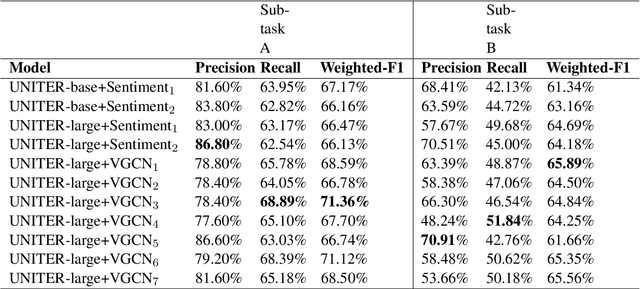
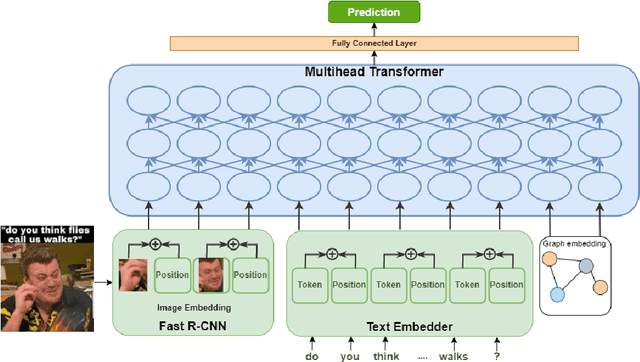
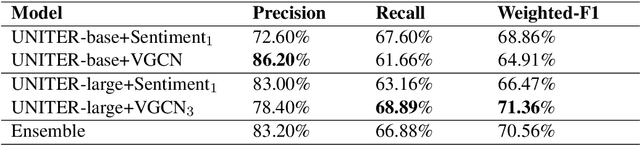
In recent times, the detection of hate-speech, offensive, or abusive language in online media has become an important topic in NLP research due to the exponential growth of social media and the propagation of such messages, as well as their impact. Misogyny detection, even though it plays an important part in hate-speech detection, has not received the same attention. In this paper, we describe our classification systems submitted to the SemEval-2022 Task 5: MAMI - Multimedia Automatic Misogyny Identification. The shared task aimed to identify misogynous content in a multi-modal setting by analysing meme images together with their textual captions. To this end, we propose two models based on the pre-trained UNITER model, one enhanced with an image sentiment classifier, whereas the second leverages a Vocabulary Graph Convolutional Network (VGCN). Additionally, we explore an ensemble using the aforementioned models. Our best model reaches an F1-score of 71.4% in Sub-task A and 67.3% for Sub-task B positioning our team in the upper third of the leaderboard. We release the code and experiments for our models on GitHub
UPB at SemEval-2021 Task 5: Virtual Adversarial Training for Toxic Spans Detection
Apr 17, 2021
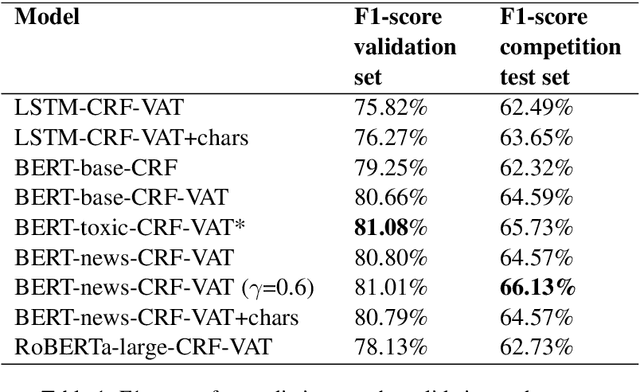
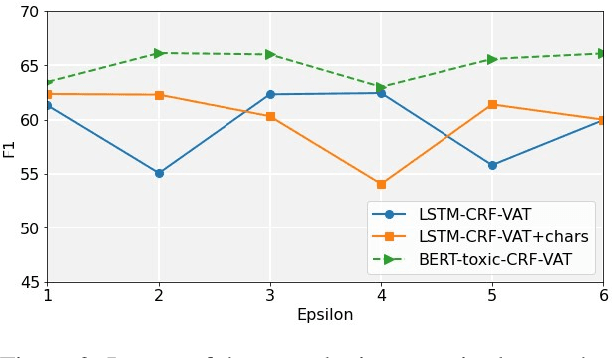

The real-world impact of polarization and toxicity in the online sphere marked the end of 2020 and the beginning of this year in a negative way. Semeval-2021, Task 5 - Toxic Spans Detection is based on a novel annotation of a subset of the Jigsaw Unintended Bias dataset and is the first language toxicity detection task dedicated to identifying the toxicity-level spans. For this task, participants had to automatically detect character spans in short comments that render the message as toxic. Our model considers applying Virtual Adversarial Training in a semi-supervised setting during the fine-tuning process of several Transformer-based models (i.e., BERT and RoBERTa), in combination with Conditional Random Fields. Our approach leads to performance improvements and more robust models, enabling us to achieve an F1-score of 65.73% in the official submission and an F1-score of 66.13% after further tuning during post-evaluation.
UPB at SemEval-2020 Task 11: Propaganda Detection with Domain-Specific Trained BERT
Sep 11, 2020

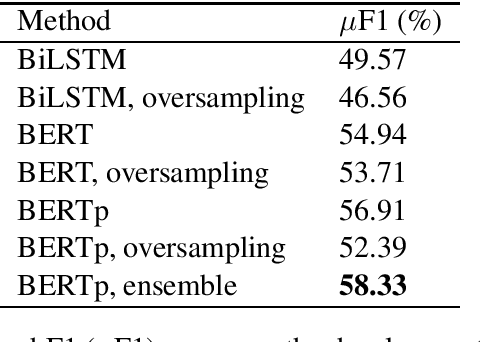
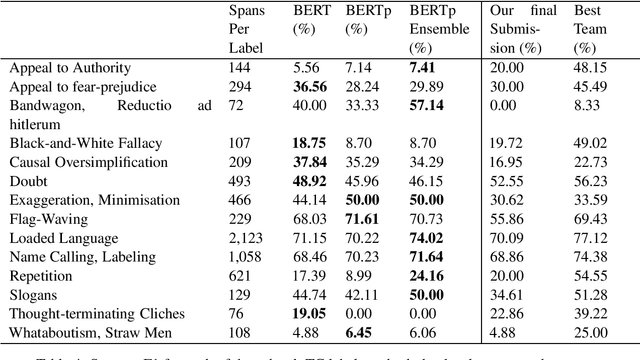
Manipulative and misleading news have become a commodity for some online news outlets and these news have gained a significant impact on the global mindset of people. Propaganda is a frequently employed manipulation method having as goal to influence readers by spreading ideas meant to distort or manipulate their opinions. This paper describes our participation in the SemEval-2020, Task 11: Detection of Propaganda Techniques in News Articles competition. Our approach considers specializing a pre-trained BERT model on propagandistic and hyperpartisan news articles, enabling it to create more adequate representations for the two subtasks, namely propaganda Span Identification (SI) and propaganda Technique Classification (TC). Our proposed system achieved a F1-score of 46.060% in subtask SI, ranking 5th in the leaderboard from 36 teams and a micro-averaged F1 score of 54.302% for subtask TC, ranking 19th from 32 teams.