 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning Actions and Walking to LLM-Generated Textual Descriptions
Apr 18, 2024



Large Language Models (LLMs) have demonstrated remarkable capabilities in various domains, including data augmentation and synthetic data generation. This work explores the use of LLMs to generate rich textual descriptions for motion sequences, encompassing both actions and walking patterns. We leverage the expressive power of LLMs to align motion representations with high-level linguistic cues, addressing two distinct tasks: action recognition and retrieval of walking sequences based on appearance attributes. For action recognition, we employ LLMs to generate textual descriptions of actions in the BABEL-60 dataset, facilitating the alignment of motion sequences with linguistic representations. In the domain of gait analysis, we investigate the impact of appearance attributes on walking patterns by generating textual descriptions of motion sequences from the DenseGait dataset using LLMs. These descriptions capture subtle variations in walking styles influenced by factors such as clothing choices and footwear. Our approach demonstrates the potential of LLMs in augmenting structured motion attributes and aligning multi-modal representations. The findings contribute to the advancement of comprehensive motion understanding and open up new avenues for leveraging LLMs in multi-modal alignment and data augmentation for motion analysis. We make the code publicly available at https://github.com/Radu1999/WalkAndText
Generative Adversarial Training for Text-to-Speech Synthesis Based on Raw Phonetic Input and Explicit Prosody Modelling
Oct 14, 2023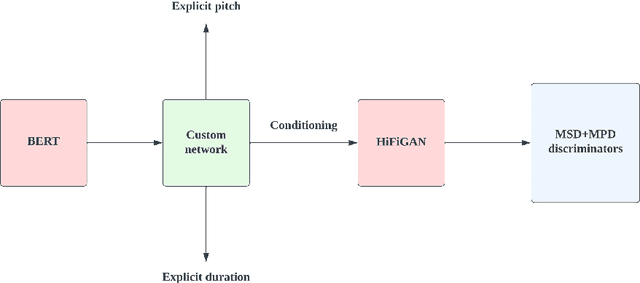
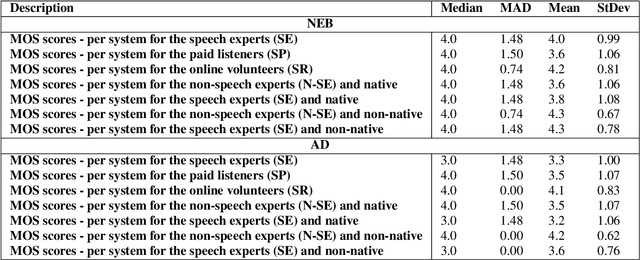
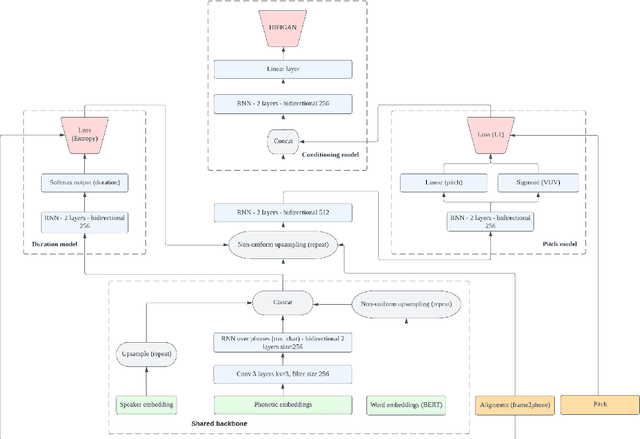
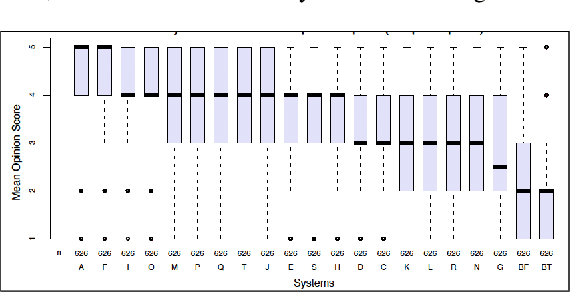
We describe an end-to-end speech synthesis system that uses generative adversarial training. We train our Vocoder for raw phoneme-to-audio conversion, using explicit phonetic, pitch and duration modeling. We experiment with several pre-trained models for contextualized and decontextualized word embeddings and we introduce a new method for highly expressive character voice matching, based on discreet style tokens.