 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGait Recognition from Highly Compressed Videos
Apr 18, 2024Surveillance footage represents a valuable resource and opportunities for conducting gait analysis. However, the typical low quality and high noise levels in such footage can severely impact the accuracy of pose estimation algorithms, which are foundational for reliable gait analysis. Existing literature suggests a direct correlation between the efficacy of pose estimation and the subsequent gait analysis results. A common mitigation strategy involves fine-tuning pose estimation models on noisy data to improve robustness. However, this approach may degrade the downstream model's performance on the original high-quality data, leading to a trade-off that is undesirable in practice. We propose a processing pipeline that incorporates a task-targeted artifact correction model specifically designed to pre-process and enhance surveillance footage before pose estimation. Our artifact correction model is optimized to work alongside a state-of-the-art pose estimation network, HRNet, without requiring repeated fine-tuning of the pose estimation model. Furthermore, we propose a simple and robust method for obtaining low quality videos that are annotated with poses in an automatic manner with the purpose of training the artifact correction model. We systematically evaluate the performance of our artifact correction model against a range of noisy surveillance data and demonstrate that our approach not only achieves improved pose estimation on low-quality surveillance footage, but also preserves the integrity of the pose estimation on high resolution footage. Our experiments show a clear enhancement in gait analysis performance, supporting the viability of the proposed method as a superior alternative to direct fine-tuning strategies. Our contributions pave the way for more reliable gait analysis using surveillance data in real-world applications, regardless of data quality.
Aligning Actions and Walking to LLM-Generated Textual Descriptions
Apr 18, 2024



Large Language Models (LLMs) have demonstrated remarkable capabilities in various domains, including data augmentation and synthetic data generation. This work explores the use of LLMs to generate rich textual descriptions for motion sequences, encompassing both actions and walking patterns. We leverage the expressive power of LLMs to align motion representations with high-level linguistic cues, addressing two distinct tasks: action recognition and retrieval of walking sequences based on appearance attributes. For action recognition, we employ LLMs to generate textual descriptions of actions in the BABEL-60 dataset, facilitating the alignment of motion sequences with linguistic representations. In the domain of gait analysis, we investigate the impact of appearance attributes on walking patterns by generating textual descriptions of motion sequences from the DenseGait dataset using LLMs. These descriptions capture subtle variations in walking styles influenced by factors such as clothing choices and footwear. Our approach demonstrates the potential of LLMs in augmenting structured motion attributes and aligning multi-modal representations. The findings contribute to the advancement of comprehensive motion understanding and open up new avenues for leveraging LLMs in multi-modal alignment and data augmentation for motion analysis. We make the code publicly available at https://github.com/Radu1999/WalkAndText
GaitPT: Skeletons Are All You Need For Gait Recognition
Aug 21, 2023The analysis of patterns of walking is an important area of research that has numerous applications in security, healthcare, sports and human-computer interaction. Lately, walking patterns have been regarded as a unique fingerprinting method for automatic person identification at a distance. In this work, we propose a novel gait recognition architecture called Gait Pyramid Transformer (GaitPT) that leverages pose estimation skeletons to capture unique walking patterns, without relying on appearance information. GaitPT adopts a hierarchical transformer architecture that effectively extracts both spatial and temporal features of movement in an anatomically consistent manner, guided by the structure of the human skeleton. Our results show that GaitPT achieves state-of-the-art performance compared to other skeleton-based gait recognition works, in both controlled and in-the-wild scenarios. GaitPT obtains 82.6% average accuracy on CASIA-B, surpassing other works by a margin of 6%. Moreover, it obtains 52.16% Rank-1 accuracy on GREW, outperforming both skeleton-based and appearance-based approaches.
From Face to Gait: Weakly-Supervised Learning of Gender Information from Walking Patterns
Oct 31, 2021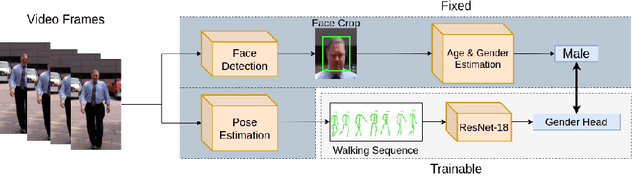

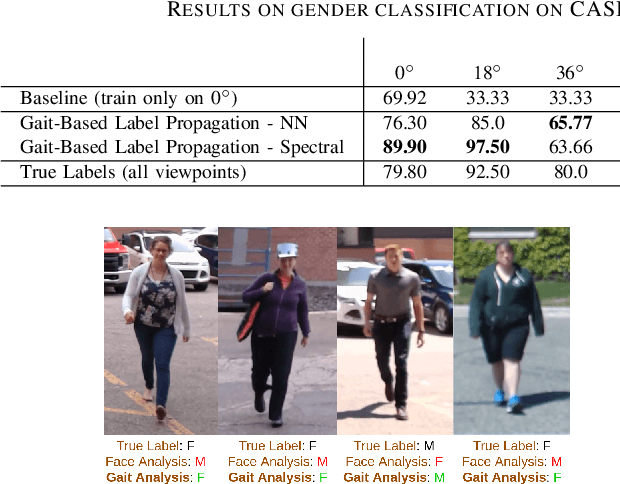

Obtaining demographics information from video is valuable for a range of real-world applications. While approaches that leverage facial features for gender inference are very successful in restrained environments, they do not work in most real-world scenarios when the subject is not facing the camera, has the face obstructed or the face is not clear due to distance from the camera or poor resolution. We propose a weakly-supervised method for learning gender information of people based on their manner of walking. We make use of state-of-the art facial analysis models to automatically annotate front-view walking sequences and generalise to unseen angles by leveraging gait-based label propagation. Our results show on par or higher performance with facial analysis models with an F1 score of 91% and the ability to successfully generalise to scenarios in which facial analysis is unfeasible due to subjects not facing the camera or having the face obstructed.