 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Face to Gait: Weakly-Supervised Learning of Gender Information from Walking Patterns
Oct 31, 2021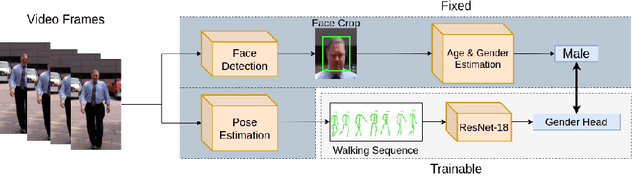

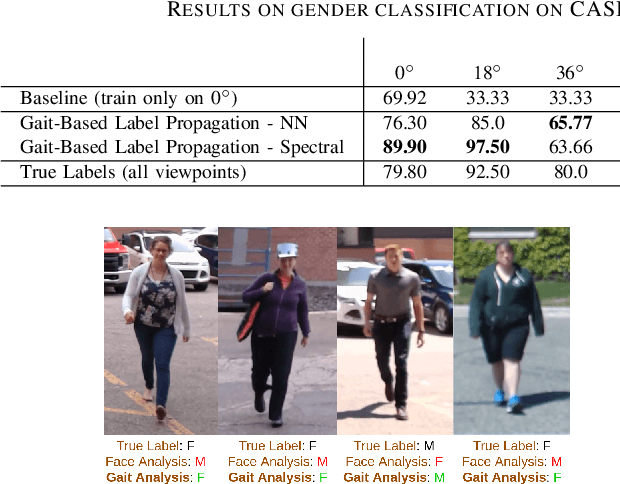

Obtaining demographics information from video is valuable for a range of real-world applications. While approaches that leverage facial features for gender inference are very successful in restrained environments, they do not work in most real-world scenarios when the subject is not facing the camera, has the face obstructed or the face is not clear due to distance from the camera or poor resolution. We propose a weakly-supervised method for learning gender information of people based on their manner of walking. We make use of state-of-the art facial analysis models to automatically annotate front-view walking sequences and generalise to unseen angles by leveraging gait-based label propagation. Our results show on par or higher performance with facial analysis models with an F1 score of 91% and the ability to successfully generalise to scenarios in which facial analysis is unfeasible due to subjects not facing the camera or having the face obstructed.
CamLoc: Pedestrian Location Detection from Pose Estimation on Resource-constrained Smart-cameras
Dec 28, 2018
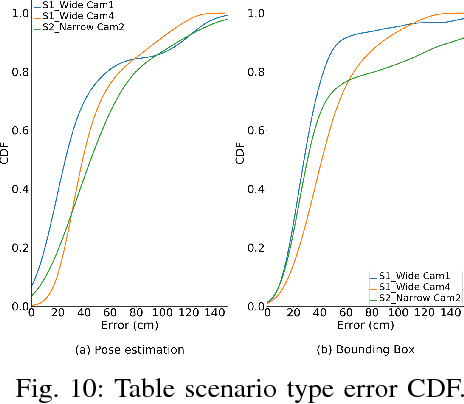

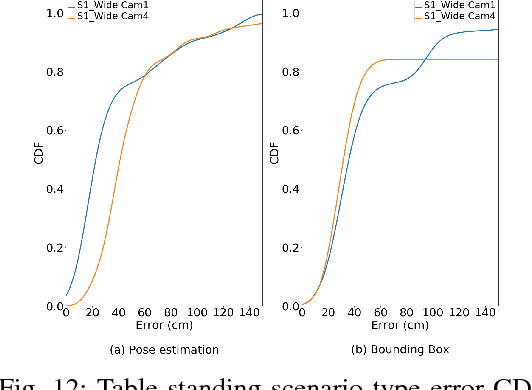
Recent advancements in energy-efficient hardware technology is driving the exponential growth we are experiencing in the Internet of Things (IoT) space, with more pervasive computations being performed near to data generation sources. A range of intelligent devices and applications performing local detection is emerging (activity recognition, fitness monitoring, etc.) bringing with them obvious advantages such as reducing detection latency for improved interaction with devices and safeguarding user data by not leaving the device. Video processing holds utility for many emerging applications and data labelling in the IoT space. However, performing this video processing with deep neural networks at the edge of the Internet is not trivial. In this paper we show that pedestrian location estimation using deep neural networks is achievable on fixed cameras with limited compute resources. Our approach uses pose estimation from key body points detection to extend pedestrian skeleton when whole body not in image (occluded by obstacles or partially outside of frame), which achieves better location estimation performance (infrence time and memory footprint) compared to fitting a bounding box over pedestrian and scaling. We collect a sizable dataset comprising of over 2100 frames in videos from one and two surveillance cameras pointing from different angles at the scene, and annotate each frame with the exact position of person in image, in 42 different scenarios of activity and occlusion. We compare our pose estimation based location detection with a popular detection algorithm, YOLOv2, for overlapping bounding-box generation, our solution achieving faster inference time (15x speedup) at half the memory footprint, within resource capabilities on embedded devices, which demonstrate that CamLoc is an efficient solution for location estimation in videos on smart-cameras.