 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning with Workload Reduction through Partial Training of Client Models and Entropy-Based Data Selection
Dec 30, 2024With the rapid expansion of edge devices, such as IoT devices, where crucial data needed for machine learning applications is generated, it becomes essential to promote their participation in privacy-preserving Federated Learning (FL) systems. The best way to achieve this desiderate is by reducing their training workload to match their constrained computational resources. While prior FL research has address the workload constrains by introducing lightweight models on the edge, limited attention has been given to optimizing on-device training efficiency through reducing the amount of data need during training. In this work, we propose FedFT-EDS, a novel approach that combines Fine-Tuning of partial client models with Entropy-based Data Selection to reduce training workloads on edge devices. By actively selecting the most informative local instances for learning, FedFT-EDS reduces training data significantly in FL and demonstrates that not all user data is equally beneficial for FL on all rounds. Our experiments on CIFAR-10 and CIFAR-100 show that FedFT-EDS uses only 50% user data while improving the global model performance compared to baseline methods, FedAvg and FedProx. Importantly, FedFT-EDS improves client learning efficiency by up to 3 times, using one third of training time on clients to achieve an equivalent performance to the baselines. This work highlights the importance of data selection in FL and presents a promising pathway to scalable and efficient Federate Learning.
Closing the Gap between Client and Global Model Performance in Heterogeneous Federated Learning
Nov 13, 2022



The heterogeneity of hardware and data is a well-known and studied problem in the community of Federated Learning (FL) as running under heterogeneous settings. Recently, custom-size client models trained with Knowledge Distillation (KD) has emerged as a viable strategy for tackling the heterogeneity challenge. However, previous efforts in this direction are aimed at client model tuning rather than their impact onto the knowledge aggregation of the global model. Despite performance of global models being the primary objective of FL systems, under heterogeneous settings client models have received more attention. Here, we provide more insights into how the chosen approach for training custom client models has an impact on the global model, which is essential for any FL application. We show the global model can fully leverage the strength of KD with heterogeneous data. Driven by empirical observations, we further propose a new approach that combines KD and Learning without Forgetting (LwoF) to produce improved personalised models. We bring heterogeneous FL on pair with the mighty FedAvg of homogeneous FL, in realistic deployment scenarios with dropping clients.
Data Selection for Efficient Model Update in Federated Learning
Nov 05, 2021
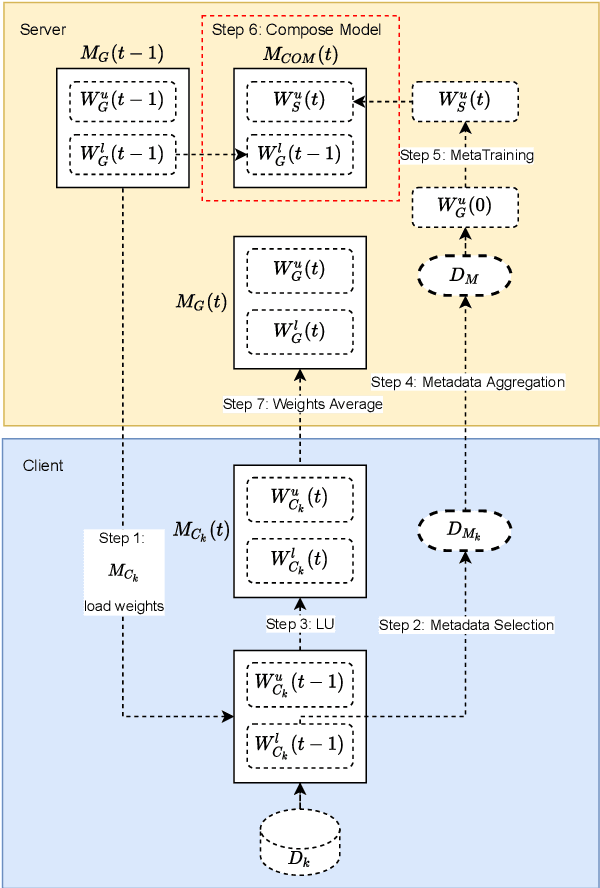

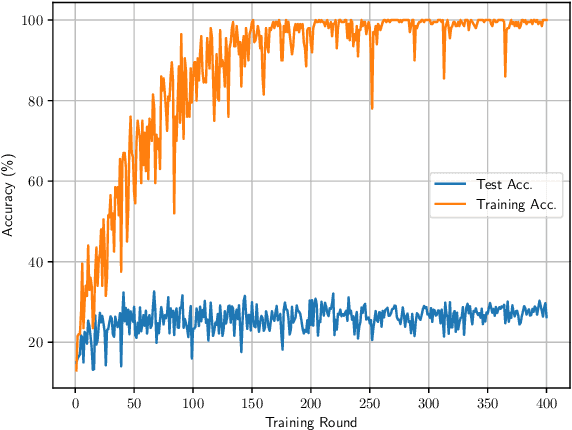
The Federated Learning workflow of training a centralized model with distributed data is growing in popularity. However, until recently, this was the realm of contributing clients with similar computing capabilities. The fast expanding IoT space and data being generated and processed at the edge are encouraging more effort into expanding federated learning to include heterogeneous systems. Previous approaches distribute smaller models to clients for distilling the characteristic of local data. But the problem of training with vast amounts of local data on the client side still remains. We propose to reduce the amount of local data that is needed to train a global model. We do this by splitting the model into a lower part for generic feature extraction and an upper part that is more sensitive to the characteristics of the local data. We reduce the amount of data needed to train the upper part by clustering the local data and selecting only the most representative samples to use for training. Our experiments show that less than 1% of the local data can transfer the characteristics of the client data to the global model with our slit network approach. These preliminary results are encouraging continuing towards federated learning with reduced amount of data on devices with limited computing resources, but which hold critical information to contribute to the global model.
Optimising the Performance of Convolutional Neural Networks across Computing Systems using Transfer Learning
Oct 20, 2020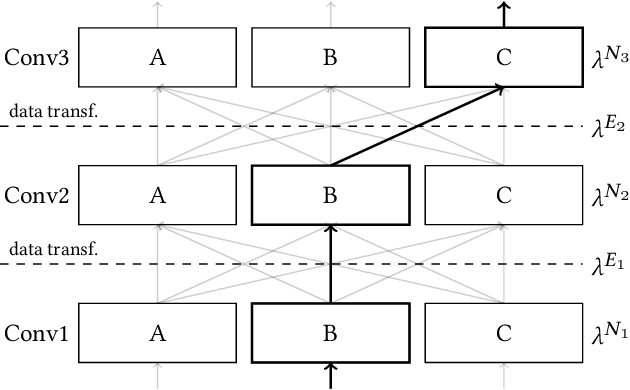
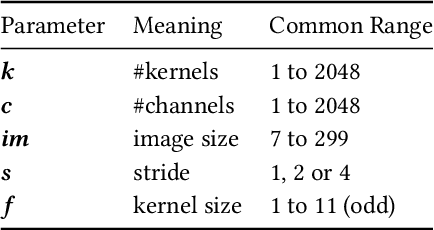
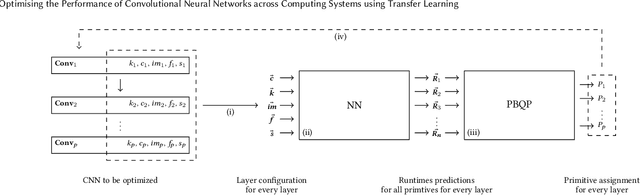

The choice of convolutional routines (primitives) to implement neural networks has a tremendous impact on their inference performance (execution speed) on a given hardware platform. To optimise a neural network by primitive selection, the optimal primitive is identified for each layer of the network. This process requires a lengthy profiling stage, iterating over all the available primitives for each layer configuration, to measure their execution time on the target platform. Because each primitive exploits the hardware in different ways, new profiling is needed to obtain the best performance when moving to another platform. In this work, we propose to replace this prohibitively expensive profiling stage with a machine learning based approach of performance modeling. Our approach speeds up the optimisation time drastically. After training, our performance model can estimate the performance of convolutional primitives in any layer configuration. The time to optimise the execution of large neural networks via primitive selection is reduced from hours to just seconds. Our performance model is easily transferable to other target platforms. We demonstrate this by training a performance model on an Intel platform and performing transfer learning to AMD and ARM processor devices with minimal profiled samples.
TASO: Time and Space Optimization for Memory-Constrained DNN Inference
May 21, 2020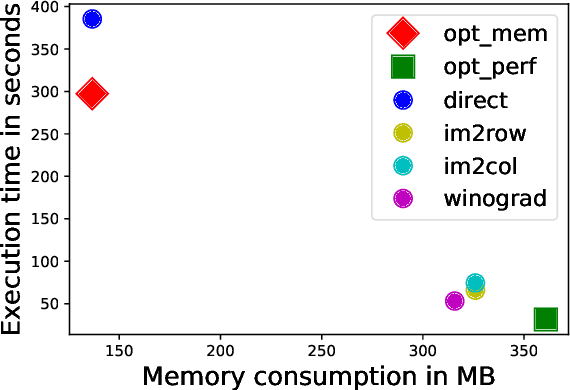
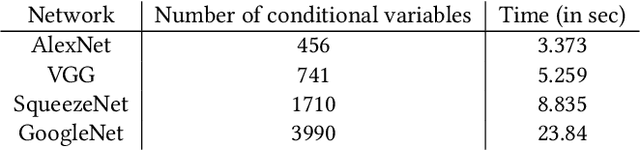

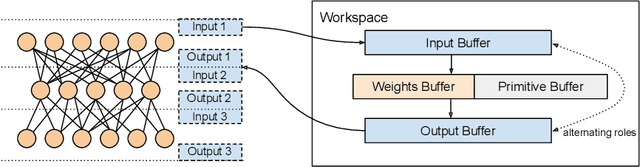
Convolutional neural networks (CNNs) are used in many embedded applications, from industrial robotics and automation systems to biometric identification on mobile devices. State-of-the-art classification is typically achieved by large networks, which are prohibitively expensive to run on mobile and embedded devices with tightly constrained memory and energy budgets. We propose an approach for ahead-of-time domain specific optimization of CNN models, based on an integer linear programming (ILP) for selecting primitive operations to implement convolutional layers. We optimize the trade-off between execution time and memory consumption by: 1) attempting to minimize execution time across the whole network by selecting data layouts and primitive operations to implement each layer; and 2) allocating an appropriate workspace that reflects the upper bound of memory footprint per layer. These two optimization strategies can be used to run any CNN on any platform with a C compiler. Our evaluation with a range of popular ImageNet neural architectures (GoogleNet, AlexNet, VGG, ResNet and SqueezeNet) on the ARM Cortex-A15 yields speedups of 8x compared to a greedy algorithm based primitive selection, reduces memory requirement by 2.2x while sacrificing only 15% of inference time compared to a solver that considers inference time only. In addition, our optimization approach exposes a range of optimal points for different configurations across the Pareto frontier of memory and latency trade-off, which can be used under arbitrary system constraints.
Performance Aware Convolutional Neural Network Channel Pruning for Embedded GPUs
Feb 20, 2020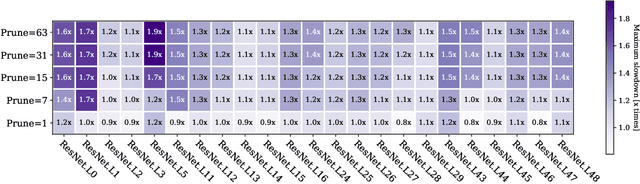

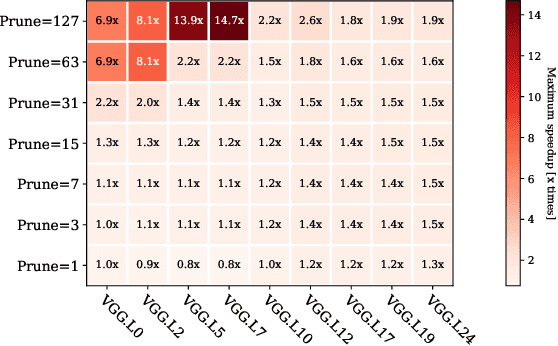

Convolutional Neural Networks (CNN) are becoming a common presence in many applications and services, due to their superior recognition accuracy. They are increasingly being used on mobile devices, many times just by porting large models designed for server space, although several model compression techniques have been considered. One model compression technique intended to reduce computations is channel pruning. Mobile and embedded systems now have GPUs which are ideal for the parallel computations of neural networks and for their lower energy cost per operation. Specialized libraries perform these neural network computations through highly optimized routines. As we find in our experiments, these libraries are optimized for the most common network shapes, making uninstructed channel pruning inefficient. We evaluate higher level libraries, which analyze the input characteristics of a convolutional layer, based on which they produce optimized OpenCL (Arm Compute Library and TVM) and CUDA (cuDNN) code. However, in reality, these characteristics and subsequent choices intended for optimization can have the opposite effect. We show that a reduction in the number of convolutional channels, pruning 12% of the initial size, is in some cases detrimental to performance, leading to 2x slowdown. On the other hand, we also find examples where performance-aware pruning achieves the intended results, with performance speedups of 3x with cuDNN and above 10x with Arm Compute Library and TVM. Our findings expose the need for hardware-instructed neural network pruning.
CamLoc: Pedestrian Location Detection from Pose Estimation on Resource-constrained Smart-cameras
Dec 28, 2018
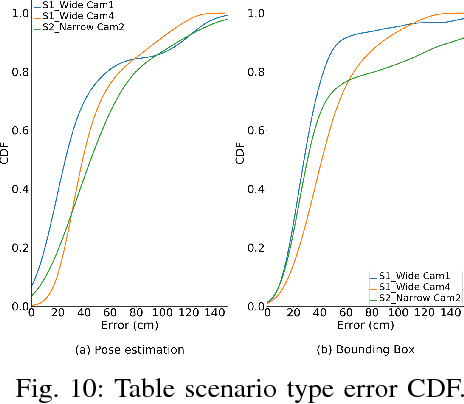

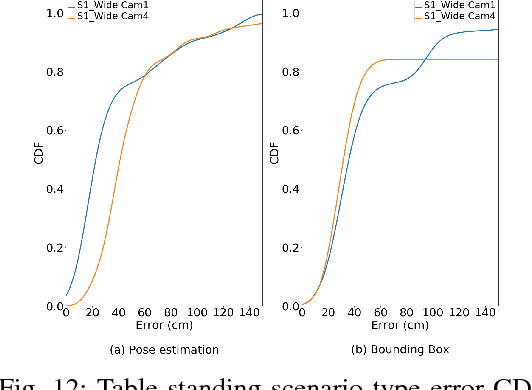
Recent advancements in energy-efficient hardware technology is driving the exponential growth we are experiencing in the Internet of Things (IoT) space, with more pervasive computations being performed near to data generation sources. A range of intelligent devices and applications performing local detection is emerging (activity recognition, fitness monitoring, etc.) bringing with them obvious advantages such as reducing detection latency for improved interaction with devices and safeguarding user data by not leaving the device. Video processing holds utility for many emerging applications and data labelling in the IoT space. However, performing this video processing with deep neural networks at the edge of the Internet is not trivial. In this paper we show that pedestrian location estimation using deep neural networks is achievable on fixed cameras with limited compute resources. Our approach uses pose estimation from key body points detection to extend pedestrian skeleton when whole body not in image (occluded by obstacles or partially outside of frame), which achieves better location estimation performance (infrence time and memory footprint) compared to fitting a bounding box over pedestrian and scaling. We collect a sizable dataset comprising of over 2100 frames in videos from one and two surveillance cameras pointing from different angles at the scene, and annotate each frame with the exact position of person in image, in 42 different scenarios of activity and occlusion. We compare our pose estimation based location detection with a popular detection algorithm, YOLOv2, for overlapping bounding-box generation, our solution achieving faster inference time (15x speedup) at half the memory footprint, within resource capabilities on embedded devices, which demonstrate that CamLoc is an efficient solution for location estimation in videos on smart-cameras.
HAKD: Hardware Aware Knowledge Distillation
Oct 24, 2018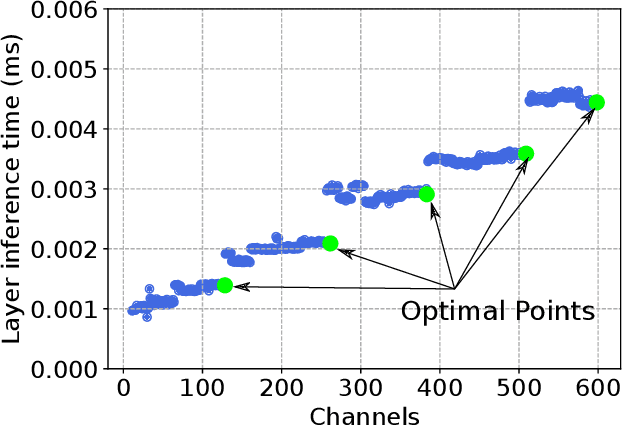

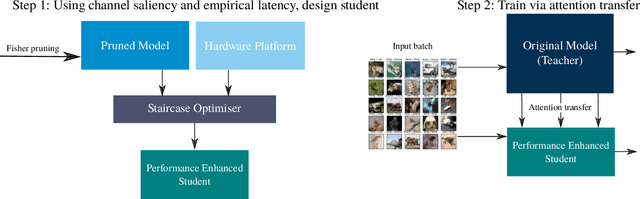
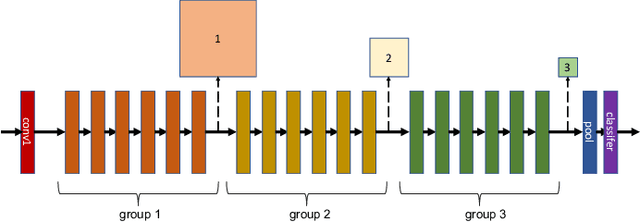
Despite recent developments, deploying deep neural networks on resource constrained general purpose hardware remains a significant challenge. There has been much work in developing methods for reshaping neural networks, usually with a focus on minimising total parameter count. These methods are typically developed in a hardware-agnostic manner and do not exploit hardware behaviour. In this paper we propose a new approach, Hardware Aware Knowledge Distillation (HAKD) which uses empirical observations of hardware behaviour to design efficient student networks which are then trained with knowledge distillation. This allows the trade-off between accuracy and performance to be managed explicitly. We have applied this approach across three platforms and evaluated it on two networks, MobileNet and DenseNet, on CIFAR-10. We show that HAKD outperforms Deep Compression and Fisher pruning in terms of size, accuracy and performance.
Characterising Across-Stack Optimisations for Deep Convolutional Neural Networks
Sep 19, 2018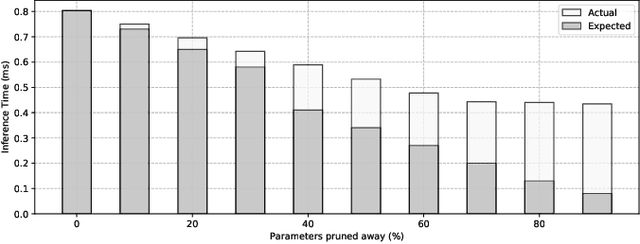

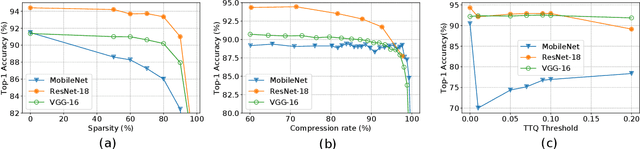

Convolutional Neural Networks (CNNs) are extremely computationally demanding, presenting a large barrier to their deployment on resource-constrained devices. Since such systems are where some of their most useful applications lie (e.g. obstacle detection for mobile robots, vision-based medical assistive technology), significant bodies of work from both machine learning and systems communities have attempted to provide optimisations that will make CNNs available to edge devices. In this paper we unify the two viewpoints in a Deep Learning Inference Stack and take an across-stack approach by implementing and evaluating the most common neural network compression techniques (weight pruning, channel pruning, and quantisation) and optimising their parallel execution with a range of programming approaches (OpenMP, OpenCL) and hardware architectures (CPU, GPU). We provide comprehensive Pareto curves to instruct trade-offs under constraints of accuracy, execution time, and memory space.