 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterising Across-Stack Optimisations for Deep Convolutional Neural Networks
Paper and Code
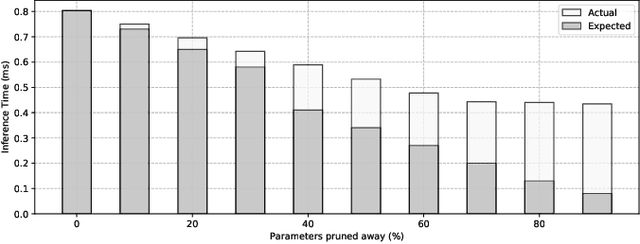

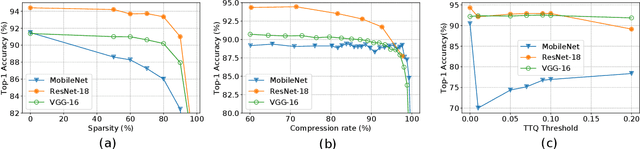

Convolutional Neural Networks (CNNs) are extremely computationally demanding, presenting a large barrier to their deployment on resource-constrained devices. Since such systems are where some of their most useful applications lie (e.g. obstacle detection for mobile robots, vision-based medical assistive technology), significant bodies of work from both machine learning and systems communities have attempted to provide optimisations that will make CNNs available to edge devices. In this paper we unify the two viewpoints in a Deep Learning Inference Stack and take an across-stack approach by implementing and evaluating the most common neural network compression techniques (weight pruning, channel pruning, and quantisation) and optimising their parallel execution with a range of programming approaches (OpenMP, OpenCL) and hardware architectures (CPU, GPU). We provide comprehensive Pareto curves to instruct trade-offs under constraints of accuracy, execution time, and memory space.