 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Selection for Efficient Model Update in Federated Learning
Paper and Code
Nov 05, 2021
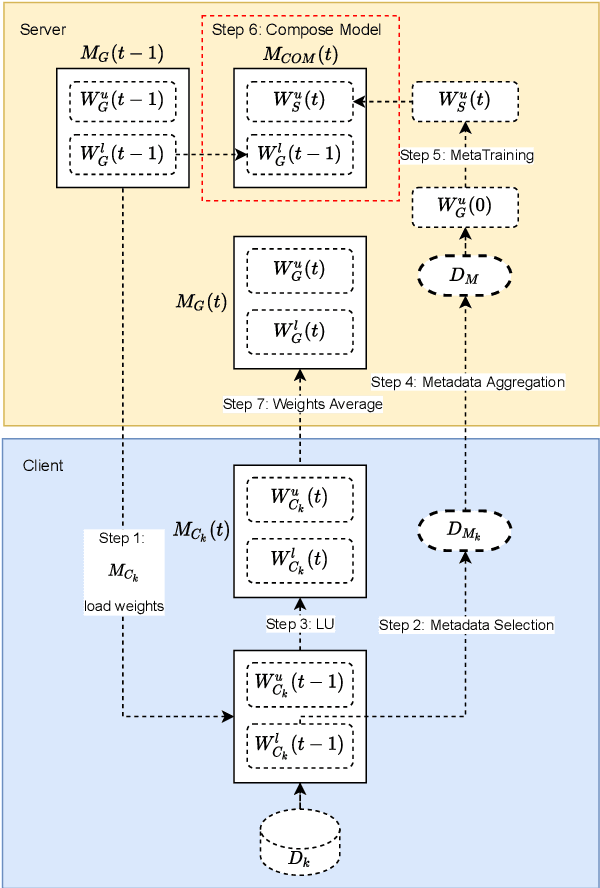

The Federated Learning workflow of training a centralized model with distributed data is growing in popularity. However, until recently, this was the realm of contributing clients with similar computing capabilities. The fast expanding IoT space and data being generated and processed at the edge are encouraging more effort into expanding federated learning to include heterogeneous systems. Previous approaches distribute smaller models to clients for distilling the characteristic of local data. But the problem of training with vast amounts of local data on the client side still remains. We propose to reduce the amount of local data that is needed to train a global model. We do this by splitting the model into a lower part for generic feature extraction and an upper part that is more sensitive to the characteristics of the local data. We reduce the amount of data needed to train the upper part by clustering the local data and selecting only the most representative samples to use for training. Our experiments show that less than 1% of the local data can transfer the characteristics of the client data to the global model with our slit network approach. These preliminary results are encouraging continuing towards federated learning with reduced amount of data on devices with limited computing resources, but which hold critical information to contribute to the global model.