 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePestMA: LLM-based Multi-Agent System for Informed Pest Management
Apr 14, 2025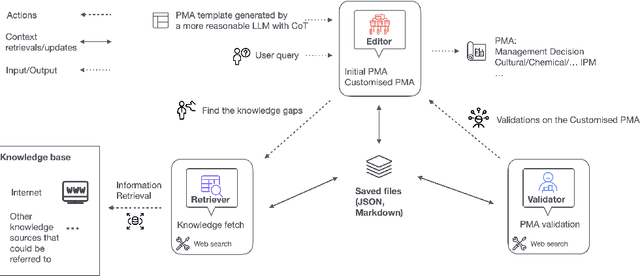



Effective pest management is complex due to the need for accurate, context-specific decisions. Recent advancements in large language models (LLMs) open new possibilities for addressing these challenges by providing sophisticated, adaptive knowledge acquisition and reasoning. However, existing LLM-based pest management approaches often rely on a single-agent paradigm, which can limit their capacity to incorporate diverse external information, engage in systematic validation, and address complex, threshold-driven decisions. To overcome these limitations, we introduce PestMA, an LLM-based multi-agent system (MAS) designed to generate reliable and evidence-based pest management advice. Building on an editorial paradigm, PestMA features three specialized agents, an Editor for synthesizing pest management recommendations, a Retriever for gathering relevant external data, and a Validator for ensuring correctness. Evaluations on real-world pest scenarios demonstrate that PestMA achieves an initial accuracy of 86.8% for pest management decisions, which increases to 92.6% after validation. These results underscore the value of collaborative agent-based workflows in refining and validating decisions, highlighting the potential of LLM-based multi-agent systems to automate and enhance pest management processes.
Federated Learning with Workload Reduction through Partial Training of Client Models and Entropy-Based Data Selection
Dec 30, 2024With the rapid expansion of edge devices, such as IoT devices, where crucial data needed for machine learning applications is generated, it becomes essential to promote their participation in privacy-preserving Federated Learning (FL) systems. The best way to achieve this desiderate is by reducing their training workload to match their constrained computational resources. While prior FL research has address the workload constrains by introducing lightweight models on the edge, limited attention has been given to optimizing on-device training efficiency through reducing the amount of data need during training. In this work, we propose FedFT-EDS, a novel approach that combines Fine-Tuning of partial client models with Entropy-based Data Selection to reduce training workloads on edge devices. By actively selecting the most informative local instances for learning, FedFT-EDS reduces training data significantly in FL and demonstrates that not all user data is equally beneficial for FL on all rounds. Our experiments on CIFAR-10 and CIFAR-100 show that FedFT-EDS uses only 50% user data while improving the global model performance compared to baseline methods, FedAvg and FedProx. Importantly, FedFT-EDS improves client learning efficiency by up to 3 times, using one third of training time on clients to achieve an equivalent performance to the baselines. This work highlights the importance of data selection in FL and presents a promising pathway to scalable and efficient Federate Learning.
Closing the Gap between Client and Global Model Performance in Heterogeneous Federated Learning
Nov 13, 2022



The heterogeneity of hardware and data is a well-known and studied problem in the community of Federated Learning (FL) as running under heterogeneous settings. Recently, custom-size client models trained with Knowledge Distillation (KD) has emerged as a viable strategy for tackling the heterogeneity challenge. However, previous efforts in this direction are aimed at client model tuning rather than their impact onto the knowledge aggregation of the global model. Despite performance of global models being the primary objective of FL systems, under heterogeneous settings client models have received more attention. Here, we provide more insights into how the chosen approach for training custom client models has an impact on the global model, which is essential for any FL application. We show the global model can fully leverage the strength of KD with heterogeneous data. Driven by empirical observations, we further propose a new approach that combines KD and Learning without Forgetting (LwoF) to produce improved personalised models. We bring heterogeneous FL on pair with the mighty FedAvg of homogeneous FL, in realistic deployment scenarios with dropping clients.
Data Selection for Efficient Model Update in Federated Learning
Nov 05, 2021
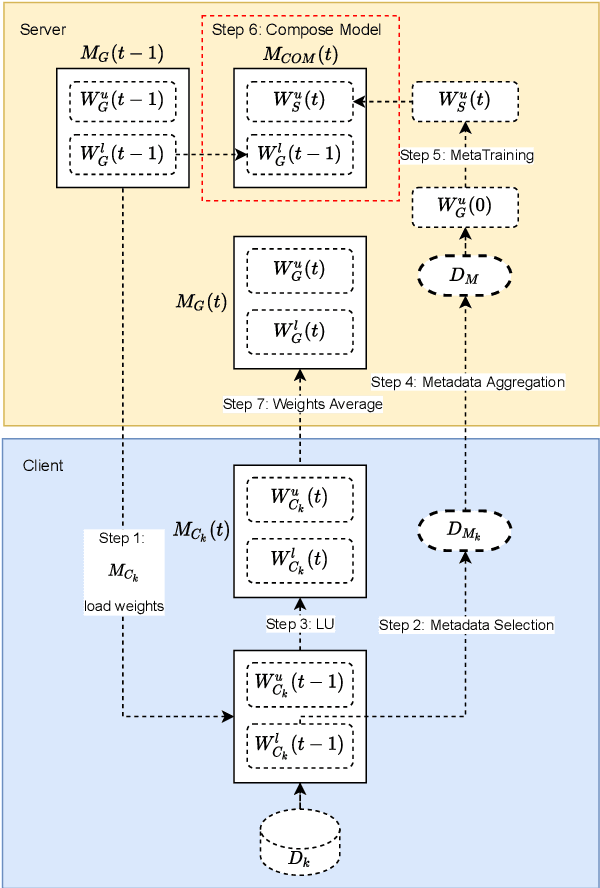

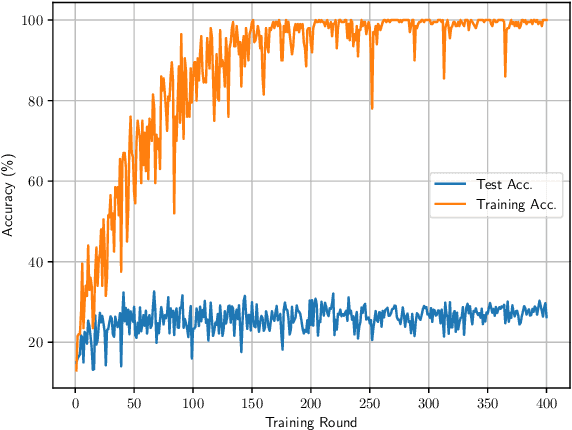
The Federated Learning workflow of training a centralized model with distributed data is growing in popularity. However, until recently, this was the realm of contributing clients with similar computing capabilities. The fast expanding IoT space and data being generated and processed at the edge are encouraging more effort into expanding federated learning to include heterogeneous systems. Previous approaches distribute smaller models to clients for distilling the characteristic of local data. But the problem of training with vast amounts of local data on the client side still remains. We propose to reduce the amount of local data that is needed to train a global model. We do this by splitting the model into a lower part for generic feature extraction and an upper part that is more sensitive to the characteristics of the local data. We reduce the amount of data needed to train the upper part by clustering the local data and selecting only the most representative samples to use for training. Our experiments show that less than 1% of the local data can transfer the characteristics of the client data to the global model with our slit network approach. These preliminary results are encouraging continuing towards federated learning with reduced amount of data on devices with limited computing resources, but which hold critical information to contribute to the global model.