 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePestMA: LLM-based Multi-Agent System for Informed Pest Management
Apr 14, 2025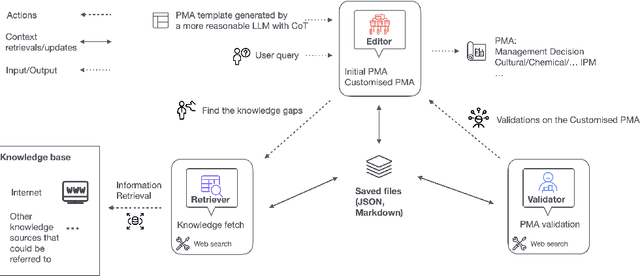



Effective pest management is complex due to the need for accurate, context-specific decisions. Recent advancements in large language models (LLMs) open new possibilities for addressing these challenges by providing sophisticated, adaptive knowledge acquisition and reasoning. However, existing LLM-based pest management approaches often rely on a single-agent paradigm, which can limit their capacity to incorporate diverse external information, engage in systematic validation, and address complex, threshold-driven decisions. To overcome these limitations, we introduce PestMA, an LLM-based multi-agent system (MAS) designed to generate reliable and evidence-based pest management advice. Building on an editorial paradigm, PestMA features three specialized agents, an Editor for synthesizing pest management recommendations, a Retriever for gathering relevant external data, and a Validator for ensuring correctness. Evaluations on real-world pest scenarios demonstrate that PestMA achieves an initial accuracy of 86.8% for pest management decisions, which increases to 92.6% after validation. These results underscore the value of collaborative agent-based workflows in refining and validating decisions, highlighting the potential of LLM-based multi-agent systems to automate and enhance pest management processes.
Exploring the Feasibility of Deep Learning Models for Long-term Disease Prediction: A Case Study for Wheat Yellow Rust in England
Jan 26, 2025Wheat yellow rust, caused by the fungus Puccinia striiformis, is a critical disease affecting wheat crops across Britain, leading to significant yield losses and economic consequences. Given the rapid environmental changes and the evolving virulence of pathogens, there is a growing need for innovative approaches to predict and manage such diseases over the long term. This study explores the feasibility of using deep learning models to predict outbreaks of wheat yellow rust in British fields, offering a proactive approach to disease management. We construct a yellow rust dataset with historial weather information and disease indicator acrossing multiple regions in England. We employ two poweful deep learning models, including fully connected neural networks and long short-term memory to develop predictive models capable of recognizing patterns and predicting future disease outbreaks.The models are trained and validated in a randomly sliced datasets. The performance of these models with different predictive time steps are evaluated based on their accuracy, precision, recall, and F1-score. Preliminary results indicate that deep learning models can effectively capture the complex interactions between multiple factors influencing disease dynamics, demonstrating a promising capacity to forecast wheat yellow rust with considerable accuracy. Specifically, the fully-connected neural network achieved 83.65% accuracy in a disease prediction task with 6 month predictive time step setup. These findings highlight the potential of deep learning to transform disease management strategies, enabling earlier and more precise interventions. Our study provides a methodological framework for employing deep learning in agricultural settings but also opens avenues for future research to enhance the robustness and applicability of predictive models in combating crop diseases globally.
Federated Learning with Workload Reduction through Partial Training of Client Models and Entropy-Based Data Selection
Dec 30, 2024With the rapid expansion of edge devices, such as IoT devices, where crucial data needed for machine learning applications is generated, it becomes essential to promote their participation in privacy-preserving Federated Learning (FL) systems. The best way to achieve this desiderate is by reducing their training workload to match their constrained computational resources. While prior FL research has address the workload constrains by introducing lightweight models on the edge, limited attention has been given to optimizing on-device training efficiency through reducing the amount of data need during training. In this work, we propose FedFT-EDS, a novel approach that combines Fine-Tuning of partial client models with Entropy-based Data Selection to reduce training workloads on edge devices. By actively selecting the most informative local instances for learning, FedFT-EDS reduces training data significantly in FL and demonstrates that not all user data is equally beneficial for FL on all rounds. Our experiments on CIFAR-10 and CIFAR-100 show that FedFT-EDS uses only 50% user data while improving the global model performance compared to baseline methods, FedAvg and FedProx. Importantly, FedFT-EDS improves client learning efficiency by up to 3 times, using one third of training time on clients to achieve an equivalent performance to the baselines. This work highlights the importance of data selection in FL and presents a promising pathway to scalable and efficient Federate Learning.
Quantifying Nematodes through Images: Datasets, Models, and Baselines of Deep Learning
Apr 30, 2024Every year, plant parasitic nematodes, one of the major groups of plant pathogens, cause a significant loss of crops worldwide. To mitigate crop yield losses caused by nematodes, an efficient nematode monitoring method is essential for plant and crop disease management. In other respects, efficient nematode detection contributes to medical research and drug discovery, as nematodes are model organisms. With the rapid development of computer technology, computer vision techniques provide a feasible solution for quantifying nematodes or nematode infections. In this paper, we survey and categorise the studies and available datasets on nematode detection through deep-learning models. To stimulate progress in related research, this survey presents the potential state-of-the-art object detection models, training techniques, optimisation techniques, and evaluation metrics for deep learning beginners. Moreover, seven state-of-the-art object detection models are validated on three public datasets and the AgriNema dataset for plant parasitic nematodes to construct a baseline for nematode detection.
GPT-4 as Evaluator: Evaluating Large Language Models on Pest Management in Agriculture
Mar 18, 2024

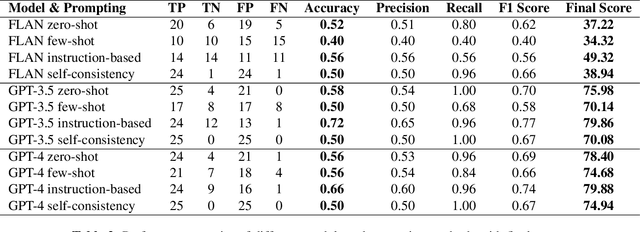
In the rapidly evolving field of artificial intelligence (AI), the application of large language models (LLMs) in agriculture, particularly in pest management, remains nascent. We aimed to prove the feasibility by evaluating the content of the pest management advice generated by LLMs, including the Generative Pre-trained Transformer (GPT) series from OpenAI and the FLAN series from Google. Considering the context-specific properties of agricultural advice, automatically measuring or quantifying the quality of text generated by LLMs becomes a significant challenge. We proposed an innovative approach, using GPT-4 as an evaluator, to score the generated content on Coherence, Logical Consistency, Fluency, Relevance, Comprehensibility, and Exhaustiveness. Additionally, we integrated an expert system based on crop threshold data as a baseline to obtain scores for Factual Accuracy on whether pests found in crop fields should take management action. Each model's score was weighted by percentage to obtain a final score. The results showed that GPT-3.4 and GPT-4 outperform the FLAN models in most evaluation categories. Furthermore, the use of instruction-based prompting containing domain-specific knowledge proved the feasibility of LLMs as an effective tool in agriculture, with an accuracy rate of 72%, demonstrating LLMs' effectiveness in providing pest management suggestions.
Spatio-Temporal Similarity Measure based Multi-Task Learning for Predicting Alzheimer's Disease Progression using MRI Data
Nov 06, 2023



Identifying and utilising various biomarkers for tracking Alzheimer's disease (AD) progression have received many recent attentions and enable helping clinicians make the prompt decisions. Traditional progression models focus on extracting morphological biomarkers in regions of interest (ROIs) from MRI/PET images, such as regional average cortical thickness and regional volume. They are effective but ignore the relationships between brain ROIs over time, which would lead to synergistic deterioration. For exploring the synergistic deteriorating relationship between these biomarkers, in this paper, we propose a novel spatio-temporal similarity measure based multi-task learning approach for effectively predicting AD progression and sensitively capturing the critical relationships between biomarkers. Specifically, we firstly define a temporal measure for estimating the magnitude and velocity of biomarker change over time, which indicate a changing trend(temporal). Converting this trend into the vector, we then compare this variability between biomarkers in a unified vector space(spatial). The experimental results show that compared with directly ROI based learning, our proposed method is more effective in predicting disease progression. Our method also enables performing longitudinal stability selection to identify the changing relationships between biomarkers, which play a key role in disease progression. We prove that the synergistic deteriorating biomarkers between cortical volumes or surface areas have a significant effect on the cognitive prediction.
Embedding-based Retrieval with LLM for Effective Agriculture Information Extracting from Unstructured Data
Aug 06, 2023Pest identification is a crucial aspect of pest control in agriculture. However, most farmers are not capable of accurately identifying pests in the field, and there is a limited number of structured data sources available for rapid querying. In this work, we explored using domain-agnostic general pre-trained large language model(LLM) to extract structured data from agricultural documents with minimal or no human intervention. We propose a methodology that involves text retrieval and filtering using embedding-based retrieval, followed by LLM question-answering to automatically extract entities and attributes from the documents, and transform them into structured data. In comparison to existing methods, our approach achieves consistently better accuracy in the benchmark while maintaining efficiency.
Closing the Gap between Client and Global Model Performance in Heterogeneous Federated Learning
Nov 13, 2022



The heterogeneity of hardware and data is a well-known and studied problem in the community of Federated Learning (FL) as running under heterogeneous settings. Recently, custom-size client models trained with Knowledge Distillation (KD) has emerged as a viable strategy for tackling the heterogeneity challenge. However, previous efforts in this direction are aimed at client model tuning rather than their impact onto the knowledge aggregation of the global model. Despite performance of global models being the primary objective of FL systems, under heterogeneous settings client models have received more attention. Here, we provide more insights into how the chosen approach for training custom client models has an impact on the global model, which is essential for any FL application. We show the global model can fully leverage the strength of KD with heterogeneous data. Driven by empirical observations, we further propose a new approach that combines KD and Learning without Forgetting (LwoF) to produce improved personalised models. We bring heterogeneous FL on pair with the mighty FedAvg of homogeneous FL, in realistic deployment scenarios with dropping clients.
MFL_COVID19: Quantifying Country-based Factors affecting Case Fatality Rate in Early Phase of COVID-19 Epidemic via Regularised Multi-task Feature Learning
Sep 06, 2020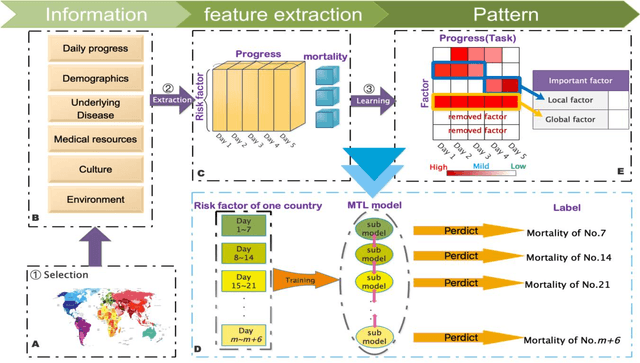

Recent outbreak of COVID-19 has led a rapid global spread around the world. Many countries have implemented timely intensive suppression to minimize the infections, but resulted in high case fatality rate (CFR) due to critical demand of health resources. Other country-based factors such as sociocultural issues, ageing population etc., has also influenced practical effectiveness of taking interventions to improve morality in early phase. To better understand the relationship of these factors across different countries with COVID-19 CFR is of primary importance to prepare for potentially second wave of COVID-19 infections. In the paper, we propose a novel regularized multi-task learning based factor analysis approach for quantifying country-based factors affecting CFR in early phase of COVID-19 epidemic. We formulate the prediction of CFR progression as a ML regression problem with observed CFR and other countries-based factors. In this formulation, all CFR related factors were categorized into 6 sectors with 27 indicators. We proposed a hybrid feature selection method combining filter, wrapper and tree-based models to calibrate initial factors for a preliminary feature interaction. Then we adopted two typical single task model (Ridge and Lasso regression) and one state-of-the-art MTFL method (fused sparse group lasso) in our formulation. The fused sparse group Lasso (FSGL) method allows the simultaneous selection of a common set of country-based factors for multiple time points of COVID-19 epidemic and also enables incorporating temporal smoothness of each factor over the whole early phase period. Finally, we proposed one novel temporal voting feature selection scheme to balance the weight instability of multiple factors in our MTFL model.