 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPT-4 as Evaluator: Evaluating Large Language Models on Pest Management in Agriculture
Mar 18, 2024

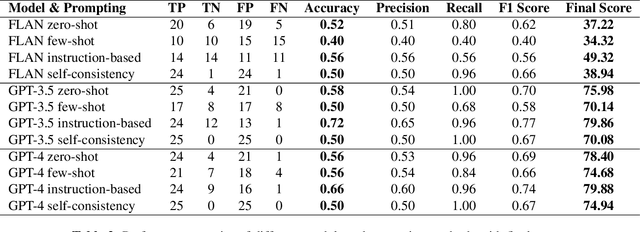
In the rapidly evolving field of artificial intelligence (AI), the application of large language models (LLMs) in agriculture, particularly in pest management, remains nascent. We aimed to prove the feasibility by evaluating the content of the pest management advice generated by LLMs, including the Generative Pre-trained Transformer (GPT) series from OpenAI and the FLAN series from Google. Considering the context-specific properties of agricultural advice, automatically measuring or quantifying the quality of text generated by LLMs becomes a significant challenge. We proposed an innovative approach, using GPT-4 as an evaluator, to score the generated content on Coherence, Logical Consistency, Fluency, Relevance, Comprehensibility, and Exhaustiveness. Additionally, we integrated an expert system based on crop threshold data as a baseline to obtain scores for Factual Accuracy on whether pests found in crop fields should take management action. Each model's score was weighted by percentage to obtain a final score. The results showed that GPT-3.4 and GPT-4 outperform the FLAN models in most evaluation categories. Furthermore, the use of instruction-based prompting containing domain-specific knowledge proved the feasibility of LLMs as an effective tool in agriculture, with an accuracy rate of 72%, demonstrating LLMs' effectiveness in providing pest management suggestions.