 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Weight Redundancy in CNNs: Beyond Pruning and Quantization
Jun 22, 2020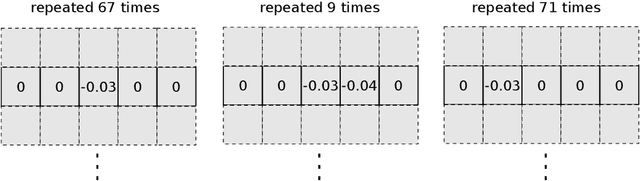
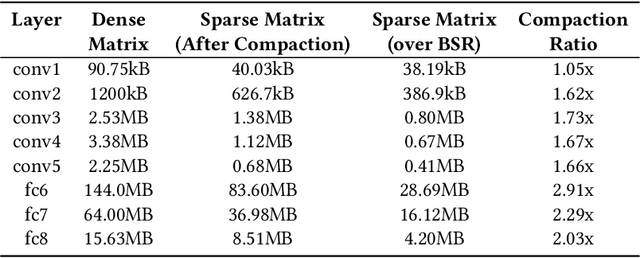
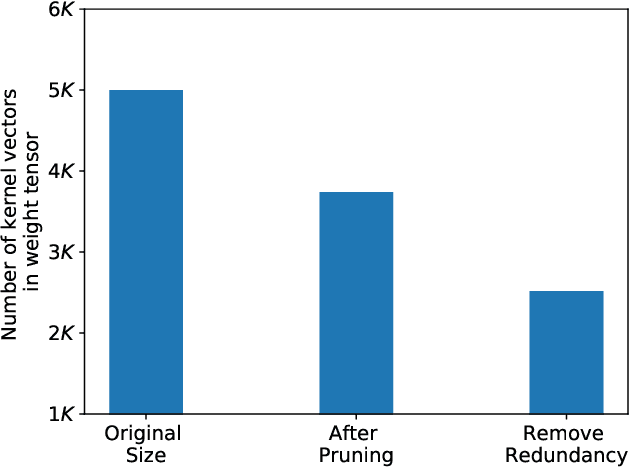
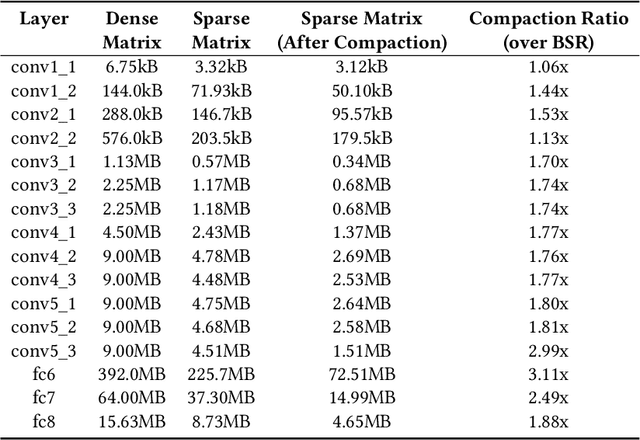
Pruning and quantization are proven methods for improving the performance and storage efficiency of convolutional neural networks (CNNs). Pruning removes near-zero weights in tensors and masks weak connections between neurons in neighbouring layers. Quantization reduces the precision of weights by replacing them with numerically similar values that require less storage. In this paper, we identify another form of redundancy in CNN weight tensors, in the form of repeated patterns of similar values. We observe that pruning and quantization both tend to drastically increase the number of repeated patterns in the weight tensors. We investigate several compression schemes to take advantage of this structure in CNN weight data, including multiple forms of Huffman coding, and other approaches inspired by block sparse matrix formats. We evaluate our approach on several well-known CNNs and find that we can achieve compaction ratios of 1.4x to 3.1x in addition to the saving from pruning and quantization.
TASO: Time and Space Optimization for Memory-Constrained DNN Inference
May 21, 2020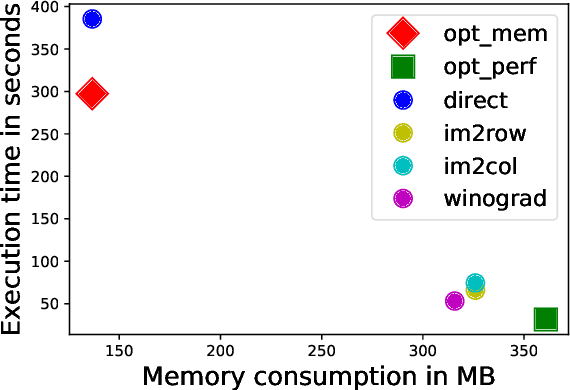

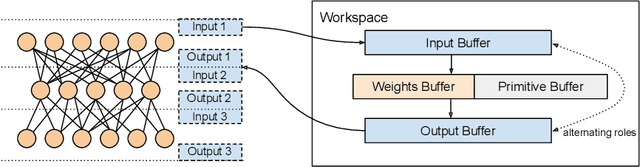
Convolutional neural networks (CNNs) are used in many embedded applications, from industrial robotics and automation systems to biometric identification on mobile devices. State-of-the-art classification is typically achieved by large networks, which are prohibitively expensive to run on mobile and embedded devices with tightly constrained memory and energy budgets. We propose an approach for ahead-of-time domain specific optimization of CNN models, based on an integer linear programming (ILP) for selecting primitive operations to implement convolutional layers. We optimize the trade-off between execution time and memory consumption by: 1) attempting to minimize execution time across the whole network by selecting data layouts and primitive operations to implement each layer; and 2) allocating an appropriate workspace that reflects the upper bound of memory footprint per layer. These two optimization strategies can be used to run any CNN on any platform with a C compiler. Our evaluation with a range of popular ImageNet neural architectures (GoogleNet, AlexNet, VGG, ResNet and SqueezeNet) on the ARM Cortex-A15 yields speedups of 8x compared to a greedy algorithm based primitive selection, reduces memory requirement by 2.2x while sacrificing only 15% of inference time compared to a solver that considers inference time only. In addition, our optimization approach exposes a range of optimal points for different configurations across the Pareto frontier of memory and latency trade-off, which can be used under arbitrary system constraints.
Performance Aware Convolutional Neural Network Channel Pruning for Embedded GPUs
Feb 20, 2020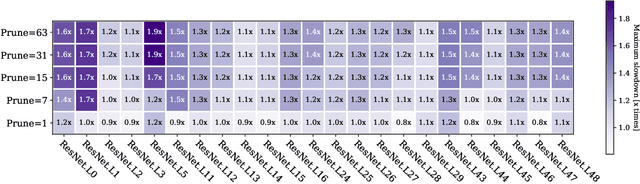

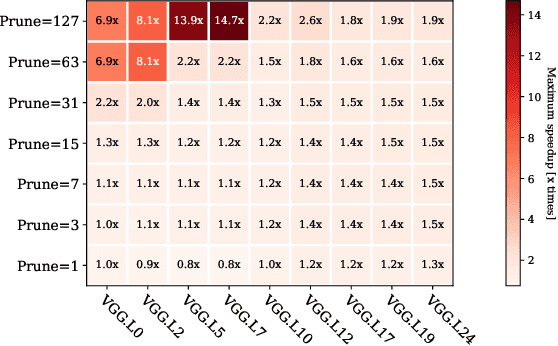

Convolutional Neural Networks (CNN) are becoming a common presence in many applications and services, due to their superior recognition accuracy. They are increasingly being used on mobile devices, many times just by porting large models designed for server space, although several model compression techniques have been considered. One model compression technique intended to reduce computations is channel pruning. Mobile and embedded systems now have GPUs which are ideal for the parallel computations of neural networks and for their lower energy cost per operation. Specialized libraries perform these neural network computations through highly optimized routines. As we find in our experiments, these libraries are optimized for the most common network shapes, making uninstructed channel pruning inefficient. We evaluate higher level libraries, which analyze the input characteristics of a convolutional layer, based on which they produce optimized OpenCL (Arm Compute Library and TVM) and CUDA (cuDNN) code. However, in reality, these characteristics and subsequent choices intended for optimization can have the opposite effect. We show that a reduction in the number of convolutional channels, pruning 12% of the initial size, is in some cases detrimental to performance, leading to 2x slowdown. On the other hand, we also find examples where performance-aware pruning achieves the intended results, with performance speedups of 3x with cuDNN and above 10x with Arm Compute Library and TVM. Our findings expose the need for hardware-instructed neural network pruning.