 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHAKD: Hardware Aware Knowledge Distillation
Paper and Code
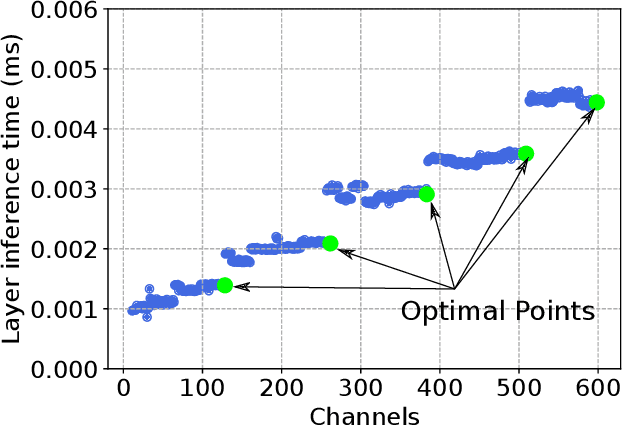

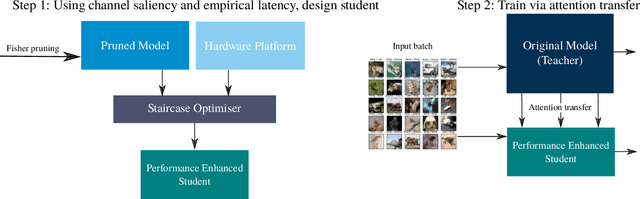
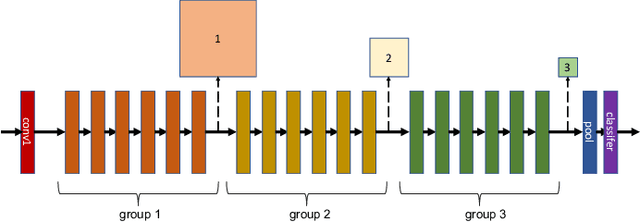
Despite recent developments, deploying deep neural networks on resource constrained general purpose hardware remains a significant challenge. There has been much work in developing methods for reshaping neural networks, usually with a focus on minimising total parameter count. These methods are typically developed in a hardware-agnostic manner and do not exploit hardware behaviour. In this paper we propose a new approach, Hardware Aware Knowledge Distillation (HAKD) which uses empirical observations of hardware behaviour to design efficient student networks which are then trained with knowledge distillation. This allows the trade-off between accuracy and performance to be managed explicitly. We have applied this approach across three platforms and evaluated it on two networks, MobileNet and DenseNet, on CIFAR-10. We show that HAKD outperforms Deep Compression and Fisher pruning in terms of size, accuracy and performance.