 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Adversarial Training for Text-to-Speech Synthesis Based on Raw Phonetic Input and Explicit Prosody Modelling
Oct 14, 2023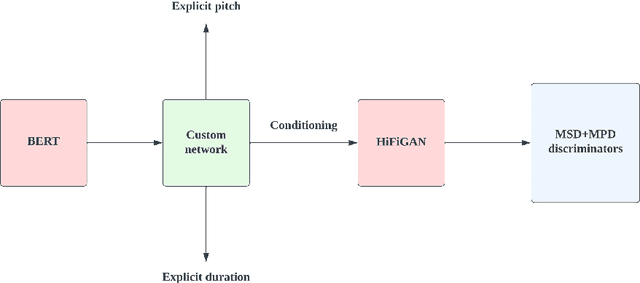
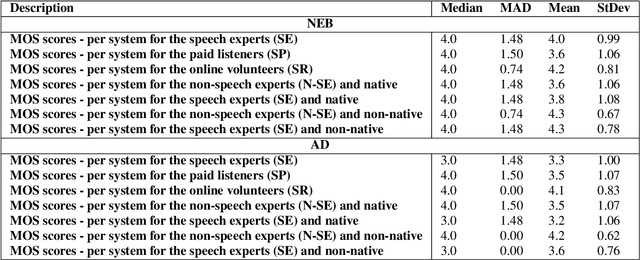
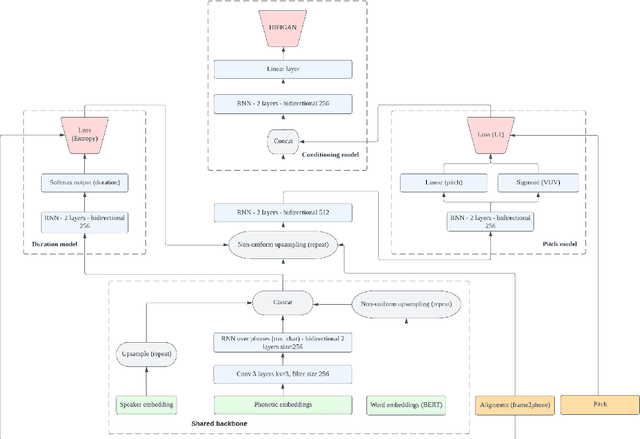
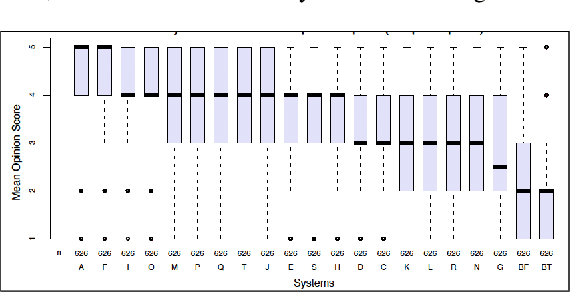
We describe an end-to-end speech synthesis system that uses generative adversarial training. We train our Vocoder for raw phoneme-to-audio conversion, using explicit phonetic, pitch and duration modeling. We experiment with several pre-trained models for contextualized and decontextualized word embeddings and we introduce a new method for highly expressive character voice matching, based on discreet style tokens.
The birth of Romanian BERT
Sep 18, 2020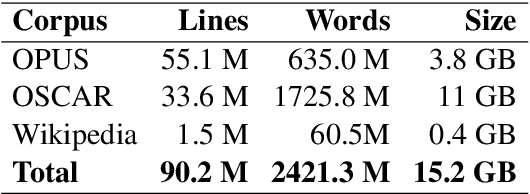



Large-scale pretrained language models have become ubiquitous in Natural Language Processing. However, most of these models are available either in high-resource languages, in particular English, or as multilingual models that compromise performance on individual languages for coverage. This paper introduces Romanian BERT, the first purely Romanian transformer-based language model, pretrained on a large text corpus. We discuss corpus composition and cleaning, the model training process, as well as an extensive evaluation of the model on various Romanian datasets. We open source not only the model itself, but also a repository that contains information on how to obtain the corpus, fine-tune and use this model in production (with practical examples), and how to fully replicate the evaluation process.
Introducing RONEC -- the Romanian Named Entity Corpus
Sep 03, 2019
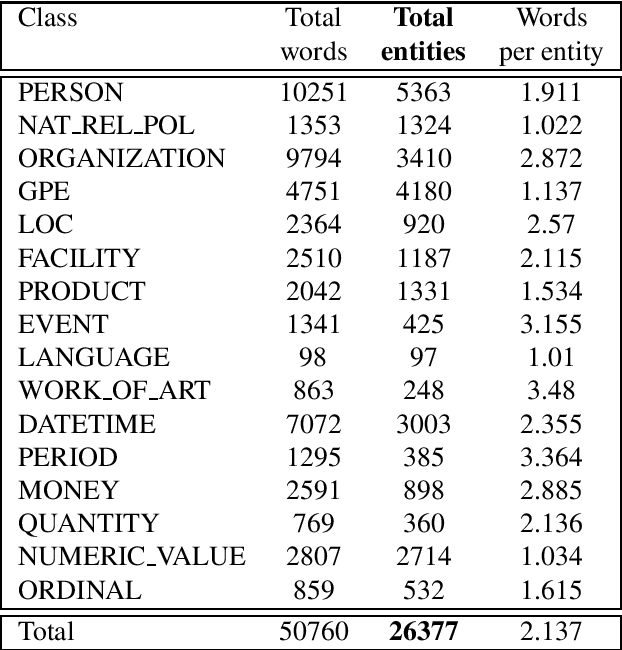
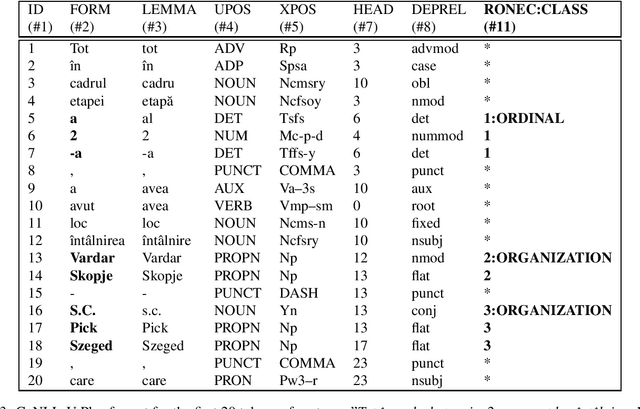
We present RONEC - the Named Entity Corpus for the Romanian language. The corpus contains over 26000 entities in ~5000 annotated sentences, belonging to 16 distinct classes. The sentences have been extracted from a copy-right free newspaper, covering several styles. This corpus represents the first initiative in the Romanian language space specifically targeted for named entity recognition. It is available in BRAT and CoNLL-U Plus formats, and it is free to use and extend at github.com/dumitrescustefan/ronec .
Tools and resources for Romanian text-to-speech and speech-to-text applications
Feb 15, 2018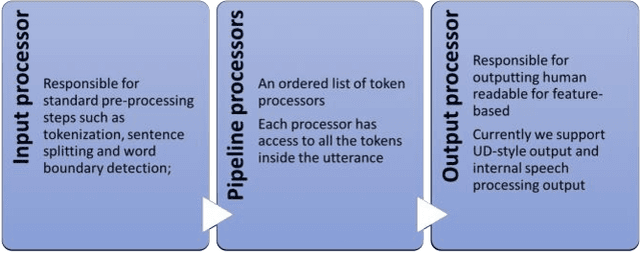
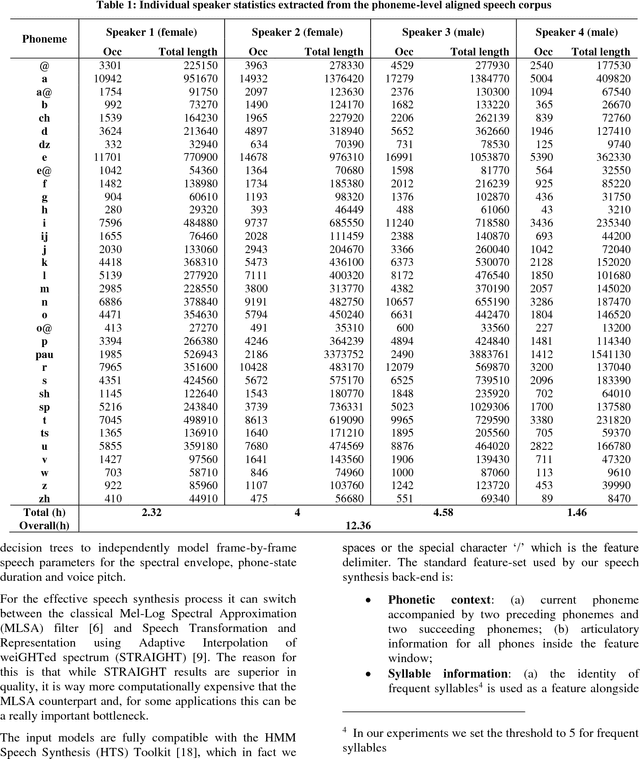
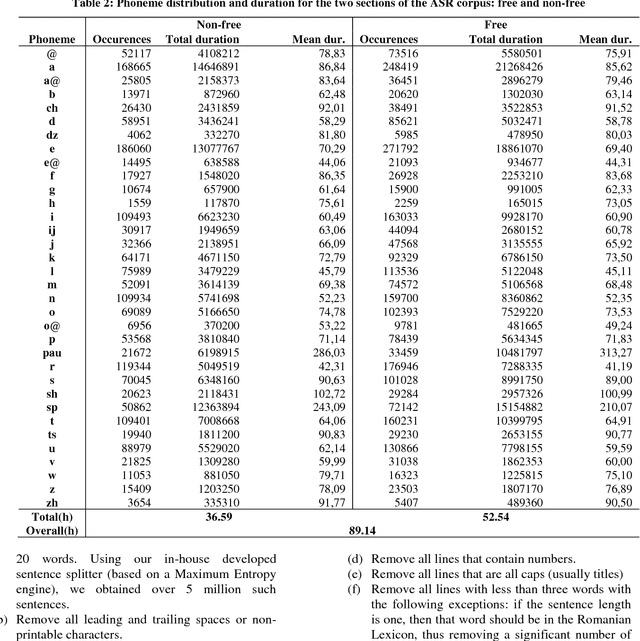
In this paper we introduce a set of resources and tools aimed at providing support for natural language processing, text-to-speech synthesis and speech recognition for Romanian. While the tools are general purpose and can be used for any language (we successfully trained our system for more than 50 languages and participated in the Universal Dependencies Shared Task), the resources are only relevant for Romanian language processing.