Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Adversarial Training for Text-to-Speech Synthesis Based on Raw Phonetic Input and Explicit Prosody Modelling
Paper and Code
Oct 14, 2023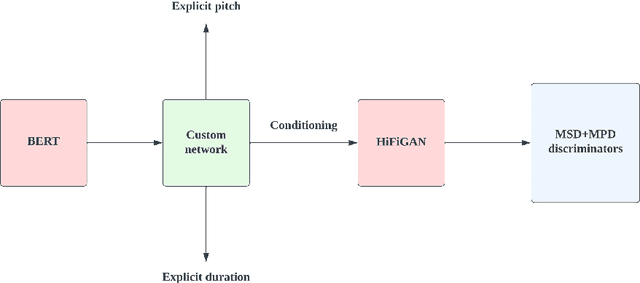
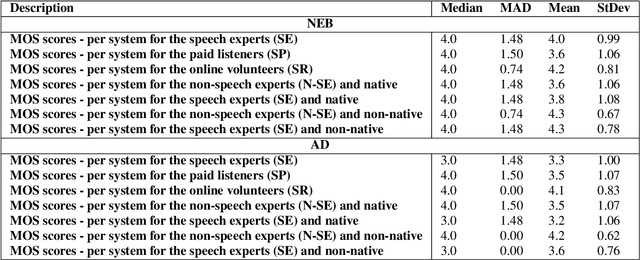
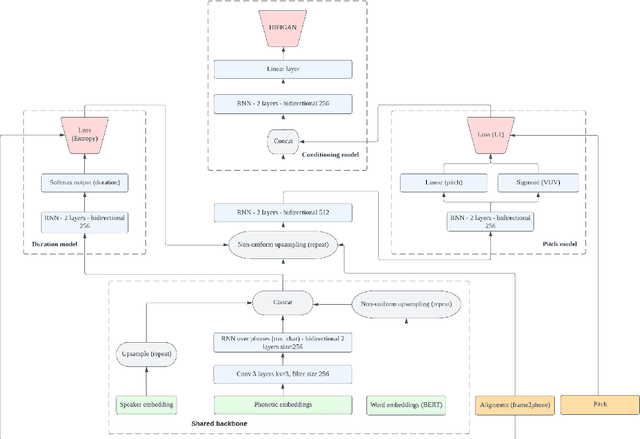
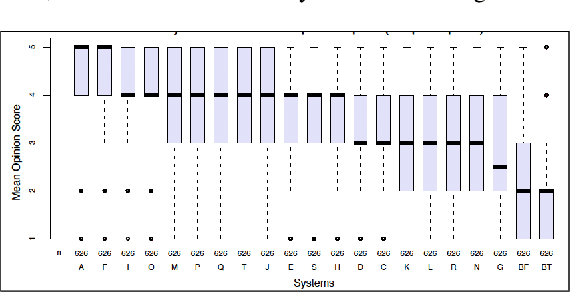
We describe an end-to-end speech synthesis system that uses generative adversarial training. We train our Vocoder for raw phoneme-to-audio conversion, using explicit phonetic, pitch and duration modeling. We experiment with several pre-trained models for contextualized and decontextualized word embeddings and we introduce a new method for highly expressive character voice matching, based on discreet style tokens.
View paper on