 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSDLog: A Deep Learning Framework for Detecting Sensitive Information in Software Logs
May 20, 2025Software logs are messages recorded during the execution of a software system that provide crucial run-time information about events and activities. Although software logs have a critical role in software maintenance and operation tasks, publicly accessible log datasets remain limited, hindering advance in log analysis research and practices. The presence of sensitive information, particularly Personally Identifiable Information (PII) and quasi-identifiers, introduces serious privacy and re-identification risks, discouraging the publishing and sharing of real-world logs. In practice, log anonymization techniques primarily rely on regular expression patterns, which involve manually crafting rules to identify and replace sensitive information. However, these regex-based approaches suffer from significant limitations, such as extensive manual efforts and poor generalizability across diverse log formats and datasets. To mitigate these limitations, we introduce SDLog, a deep learning-based framework designed to identify sensitive information in software logs. Our results show that SDLog overcomes regex limitations and outperforms the best-performing regex patterns in identifying sensitive information. With only 100 fine-tuning samples from the target dataset, SDLog can correctly identify 99.5% of sensitive attributes and achieves an F1-score of 98.4%. To the best of our knowledge, this is the first deep learning alternative to regex-based methods in software log anonymization.
What Information Contributes to Log-based Anomaly Detection? Insights from a Configurable Transformer-Based Approach
Sep 30, 2024


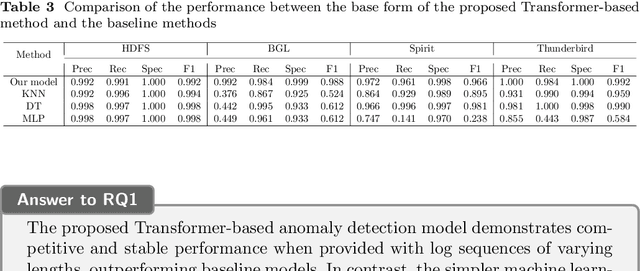
Log data are generated from logging statements in the source code, providing insights into the execution processes of software applications and systems. State-of-the-art log-based anomaly detection approaches typically leverage deep learning models to capture the semantic or sequential information in the log data and detect anomalous runtime behaviors. However, the impacts of these different types of information are not clear. In addition, existing approaches have not captured the timestamps in the log data, which can potentially provide more fine-grained temporal information than sequential information. In this work, we propose a configurable transformer-based anomaly detection model that can capture the semantic, sequential, and temporal information in the log data and allows us to configure the different types of information as the model's features. Additionally, we train and evaluate the proposed model using log sequences of different lengths, thus overcoming the constraint of existing methods that rely on fixed-length or time-windowed log sequences as inputs. With the proposed model, we conduct a series of experiments with different combinations of input features to evaluate the roles of different types of information in anomaly detection. When presented with log sequences of varying lengths, the model can attain competitive and consistently stable performance compared to the baselines. The results indicate that the event occurrence information plays a key role in identifying anomalies, while the impact of the sequential and temporal information is not significant for anomaly detection in the studied public datasets. On the other hand, the findings also reveal the simplicity of the studied public datasets and highlight the importance of constructing new datasets that contain different types of anomalies to better evaluate the performance of anomaly detection models.
Refining GPT-3 Embeddings with a Siamese Structure for Technical Post Duplicate Detection
Dec 22, 2023



One goal of technical online communities is to help developers find the right answer in one place. A single question can be asked in different ways with different wordings, leading to the existence of duplicate posts on technical forums. The question of how to discover and link duplicate posts has garnered the attention of both developer communities and researchers. For example, Stack Overflow adopts a voting-based mechanism to mark and close duplicate posts. However, addressing these constantly emerging duplicate posts in a timely manner continues to pose challenges. Therefore, various approaches have been proposed to detect duplicate posts on technical forum posts automatically. The existing methods suffer from limitations either due to their reliance on handcrafted similarity metrics which can not sufficiently capture the semantics of posts, or their lack of supervision to improve the performance. Additionally, the efficiency of these methods is hindered by their dependence on pair-wise feature generation, which can be impractical for large amount of data. In this work, we attempt to employ and refine the GPT-3 embeddings for the duplicate detection task. We assume that the GPT-3 embeddings can accurately represent the semantics of the posts. In addition, by training a Siamese-based network based on the GPT-3 embeddings, we obtain a latent embedding that accurately captures the duplicate relation in technical forum posts. Our experiment on a benchmark dataset confirms the effectiveness of our approach and demonstrates superior performance compared to baseline methods. When applied to the dataset we constructed with a recent Stack Overflow dump, our approach attains a Top-1, Top-5, and Top-30 accuracy of 23.1%, 43.9%, and 68.9%, respectively. With a manual study, we confirm our approach's potential of finding unlabelled duplicates on technical forums.
Characterizing and Classifying Developer Forum Posts with their Intentions
Dec 21, 2023With the rapid growth of the developer community, the amount of posts on online technical forums has been growing rapidly, which poses difficulties for users to filter useful posts and find important information. Tags provide a concise feature dimension for users to locate their interested posts and for search engines to index the most relevant posts according to the queries. However, most tags are only focused on the technical perspective (e.g., program language, platform, tool). In most cases, forum posts in online developer communities reveal the author's intentions to solve a problem, ask for advice, share information, etc. The modeling of the intentions of posts can provide an extra dimension to the current tag taxonomy. By referencing previous studies and learning from industrial perspectives, we create a refined taxonomy for the intentions of technical forum posts. Through manual labeling and analysis on a sampled post dataset extracted from online forums, we understand the relevance between the constitution of posts (code, error messages) and their intentions. Furthermore, inspired by our manual study, we design a pre-trained transformer-based model to automatically predict post intentions. The best variant of our intention prediction framework, which achieves a Micro F1-score of 0.589, Top 1-3 accuracy of 62.6% to 87.8%, and an average AUC of 0.787, outperforms the state-of-the-art baseline approach. Our characterization and automated classification of forum posts regarding their intentions may help forum maintainers or third-party tool developers improve the organization and retrieval of posts on technical forums. We have released our annotated dataset and codes in our supplementary material package.
On the Effectiveness of Log Representation for Log-based Anomaly Detection
Aug 17, 2023Logs are an essential source of information for people to understand the running status of a software system. Due to the evolving modern software architecture and maintenance methods, more research efforts have been devoted to automated log analysis. In particular, machine learning (ML) has been widely used in log analysis tasks. In ML-based log analysis tasks, converting textual log data into numerical feature vectors is a critical and indispensable step. However, the impact of using different log representation techniques on the performance of the downstream models is not clear, which limits researchers and practitioners' opportunities of choosing the optimal log representation techniques in their automated log analysis workflows. Therefore, this work investigates and compares the commonly adopted log representation techniques from previous log analysis research. Particularly, we select six log representation techniques and evaluate them with seven ML models and four public log datasets (i.e., HDFS, BGL, Spirit and Thunderbird) in the context of log-based anomaly detection. We also examine the impacts of the log parsing process and the different feature aggregation approaches when they are employed with log representation techniques. From the experiments, we provide some heuristic guidelines for future researchers and developers to follow when designing an automated log analysis workflow. We believe our comprehensive comparison of log representation techniques can help researchers and practitioners better understand the characteristics of different log representation techniques and provide them with guidance for selecting the most suitable ones for their ML-based log analysis workflow.