 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Information Contributes to Log-based Anomaly Detection? Insights from a Configurable Transformer-Based Approach
Paper and Code
Sep 30, 2024


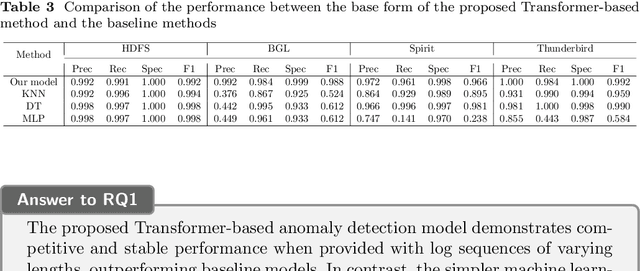
Log data are generated from logging statements in the source code, providing insights into the execution processes of software applications and systems. State-of-the-art log-based anomaly detection approaches typically leverage deep learning models to capture the semantic or sequential information in the log data and detect anomalous runtime behaviors. However, the impacts of these different types of information are not clear. In addition, existing approaches have not captured the timestamps in the log data, which can potentially provide more fine-grained temporal information than sequential information. In this work, we propose a configurable transformer-based anomaly detection model that can capture the semantic, sequential, and temporal information in the log data and allows us to configure the different types of information as the model's features. Additionally, we train and evaluate the proposed model using log sequences of different lengths, thus overcoming the constraint of existing methods that rely on fixed-length or time-windowed log sequences as inputs. With the proposed model, we conduct a series of experiments with different combinations of input features to evaluate the roles of different types of information in anomaly detection. When presented with log sequences of varying lengths, the model can attain competitive and consistently stable performance compared to the baselines. The results indicate that the event occurrence information plays a key role in identifying anomalies, while the impact of the sequential and temporal information is not significant for anomaly detection in the studied public datasets. On the other hand, the findings also reveal the simplicity of the studied public datasets and highlight the importance of constructing new datasets that contain different types of anomalies to better evaluate the performance of anomaly detection models.