 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFFGAF-SNN: The Forward-Forward Based Gradient Approximation Free Training Framework for Spiking Neural Networks
Aug 01, 2025Spiking Neural Networks (SNNs) offer a biologically plausible framework for energy-efficient neuromorphic computing. However, it is a challenge to train SNNs due to their non-differentiability, efficiently. Existing gradient approximation approaches frequently sacrifice accuracy and face deployment limitations on edge devices due to the substantial computational requirements of backpropagation. To address these challenges, we propose a Forward-Forward (FF) based gradient approximation-free training framework for Spiking Neural Networks, which treats spiking activations as black-box modules, thereby eliminating the need for gradient approximation while significantly reducing computational complexity. Furthermore, we introduce a class-aware complexity adaptation mechanism that dynamically optimizes the loss function based on inter-class difficulty metrics, enabling efficient allocation of network resources across different categories. Experimental results demonstrate that our proposed training framework achieves test accuracies of 99.58%, 92.13%, and 75.64% on the MNIST, Fashion-MNIST, and CIFAR-10 datasets, respectively, surpassing all existing FF-based SNN approaches. Additionally, our proposed method exhibits significant advantages in terms of memory access and computational power consumption.
An End-To-End Stuttering Detection Method Based On Conformer And BILSTM
Nov 14, 2024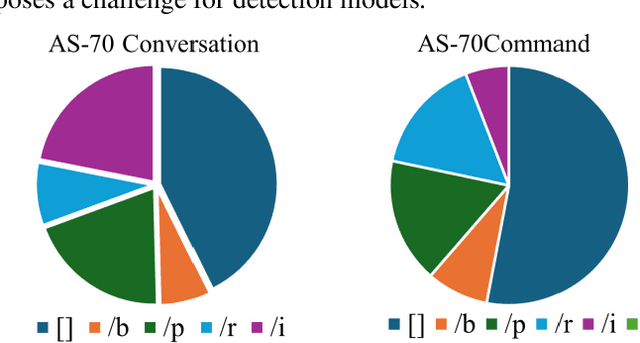

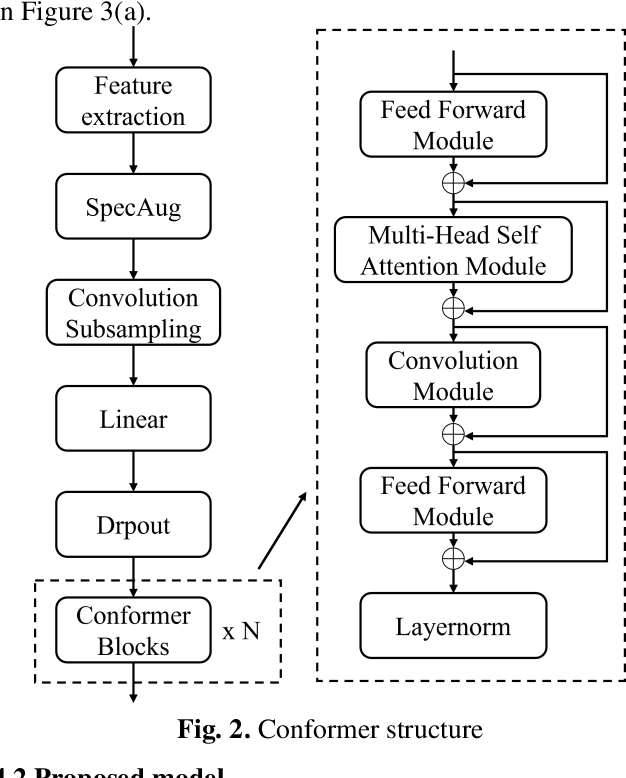

Stuttering is a neurodevelopmental speech disorder characterized by common speech symptoms such as pauses, exclamations, repetition, and prolongation. Speech-language pathologists typically assess the type and severity of stuttering by observing these symptoms. Many effective end-to-end methods exist for stuttering detection, but a commonly overlooked challenge is the uncertain relationship between tasks involved in this process. Using a suitable multi-task strategy could improve stuttering detection performance. This paper presents a novel stuttering event detection model designed to help speech-language pathologists assess both the type and severity of stuttering. First, the Conformer model extracts acoustic features from stuttered speech, followed by a Long Short-Term Memory (LSTM) network to capture contextual information. Finally, we explore multi-task learning for stuttering and propose an effective multi-task strategy. Experimental results show that our model outperforms current state-of-the-art methods for stuttering detection. In the SLT 2024 Stuttering Speech Challenge based on the AS-70 dataset [1], our model improved the mean F1 score by 24.8% compared to the baseline method and achieved first place. On this basis, we conducted relevant extensive experiments on LSTM and multi-task learning strategies respectively. The results show that our proposed method improved the mean F1 score by 39.8% compared to the baseline method.
SLSSNN: High energy efficiency spike-train level spiking neural networks with spatio-temporal conversion
Jul 14, 2023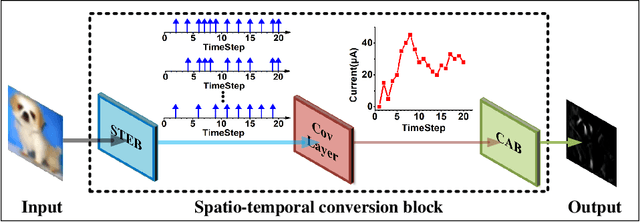
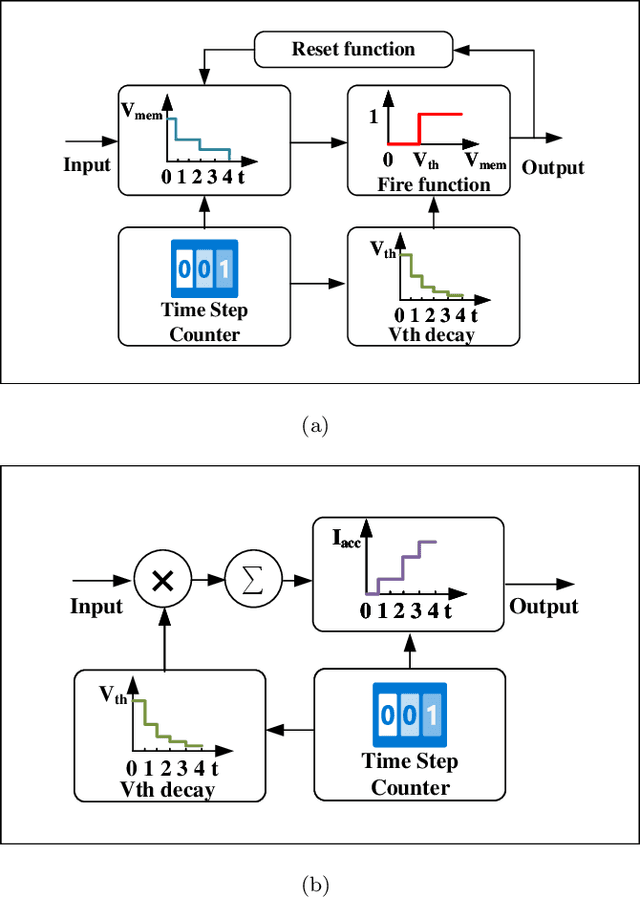
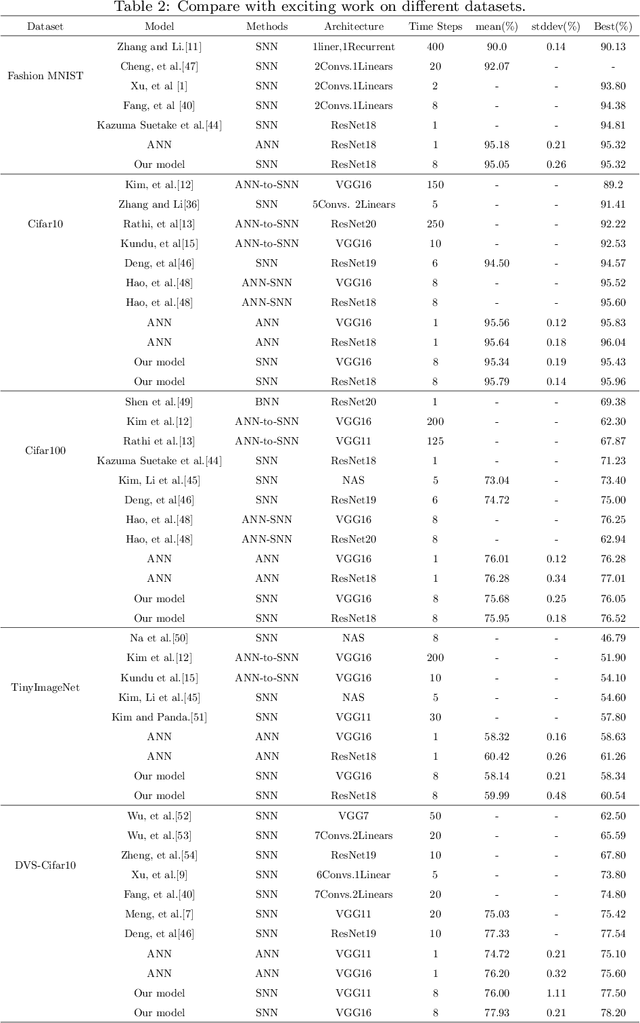
Brain-inspired spiking neuron networks (SNNs) have attracted widespread research interest due to their low power features, high biological plausibility, and strong spatiotemporal information processing capability. Although adopting a surrogate gradient (SG) makes the non-differentiability SNN trainable, achieving comparable accuracy for ANNs and keeping low-power features simultaneously is still tricky. In this paper, we proposed an energy-efficient spike-train level spiking neural network (SLSSNN) with low computational cost and high accuracy. In the SLSSNN, spatio-temporal conversion blocks (STCBs) are applied to replace the convolutional and ReLU layers to keep the low power features of SNNs and improve accuracy. However, SLSSNN cannot adopt backpropagation algorithms directly due to the non-differentiability nature of spike trains. We proposed a suitable learning rule for SLSSNNs by deducing the equivalent gradient of STCB. We evaluate the proposed SLSSNN on static and neuromorphic datasets, including Fashion-Mnist, Cifar10, Cifar100, TinyImageNet, and DVS-Cifar10. The experiment results show that our proposed SLSSNN outperforms the state-of-the-art accuracy on nearly all datasets, using fewer time steps and being highly energy-efficient.
Ultra-low Latency Adaptive Local Binary Spiking Neural Network with Accuracy Loss Estimator
Jul 31, 2022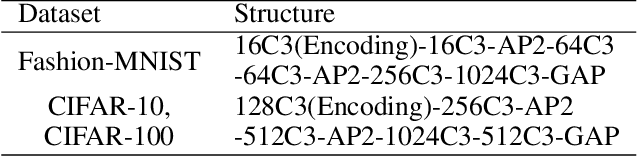
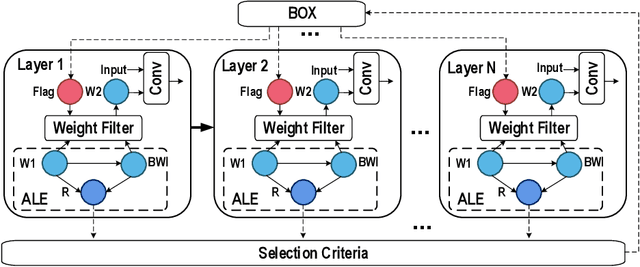
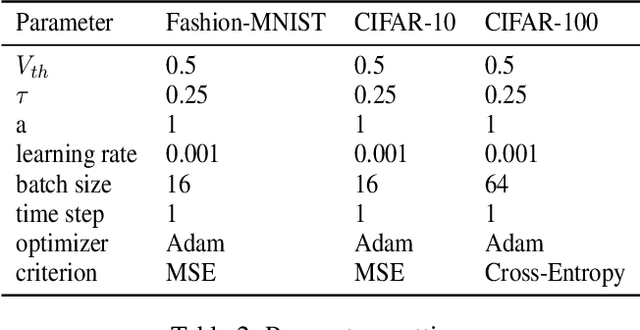
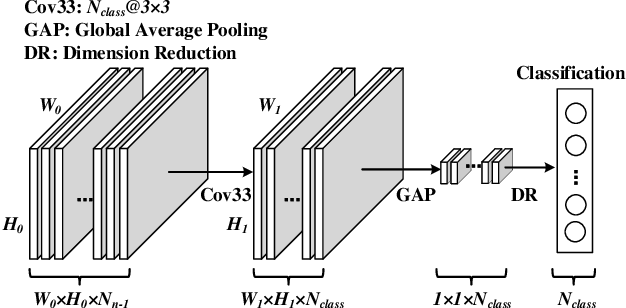
Spiking neural network (SNN) is a brain-inspired model which has more spatio-temporal information processing capacity and computational energy efficiency. However, with the increasing depth of SNNs, the memory problem caused by the weights of SNNs has gradually attracted attention. Inspired by Artificial Neural Networks (ANNs) quantization technology, binarized SNN (BSNN) is introduced to solve the memory problem. Due to the lack of suitable learning algorithms, BSNN is usually obtained by ANN-to-SNN conversion, whose accuracy will be limited by the trained ANNs. In this paper, we propose an ultra-low latency adaptive local binary spiking neural network (ALBSNN) with accuracy loss estimators, which dynamically selects the network layers to be binarized to ensure the accuracy of the network by evaluating the error caused by the binarized weights during the network learning process. Experimental results show that this method can reduce storage space by more than 20 % without losing network accuracy. At the same time, in order to accelerate the training speed of the network, the global average pooling(GAP) layer is introduced to replace the fully connected layers by the combination of convolution and pooling, so that SNNs can use a small number of time steps to obtain better recognition accuracy. In the extreme case of using only one time step, we still can achieve 92.92 %, 91.63 % ,and 63.54 % testing accuracy on three different datasets, FashionMNIST, CIFAR-10, and CIFAR-100, respectively.
Ultra-low Latency Spiking Neural Networks with Spatio-Temporal Compression and Synaptic Convolutional Block
Mar 18, 2022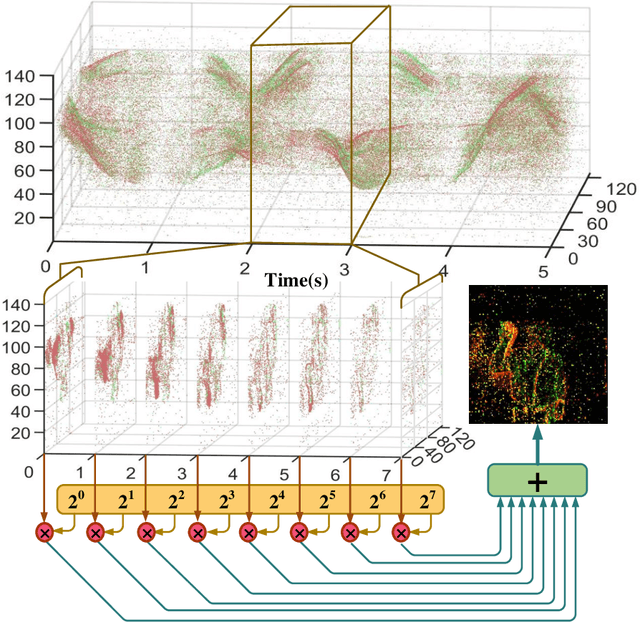
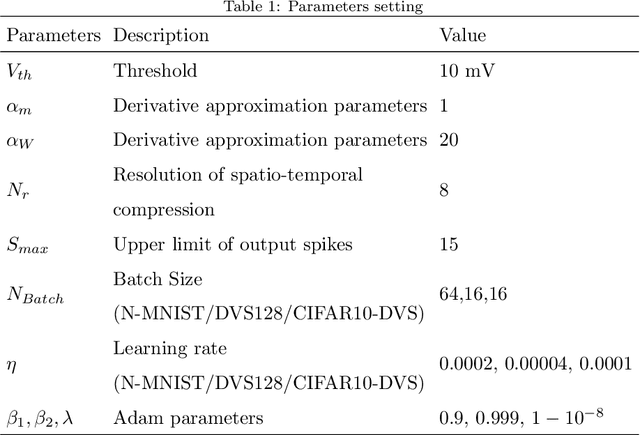
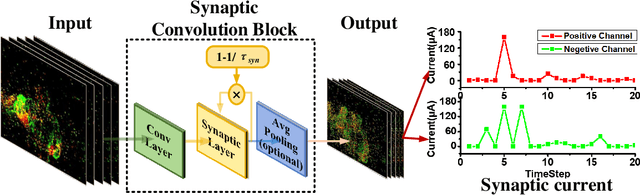
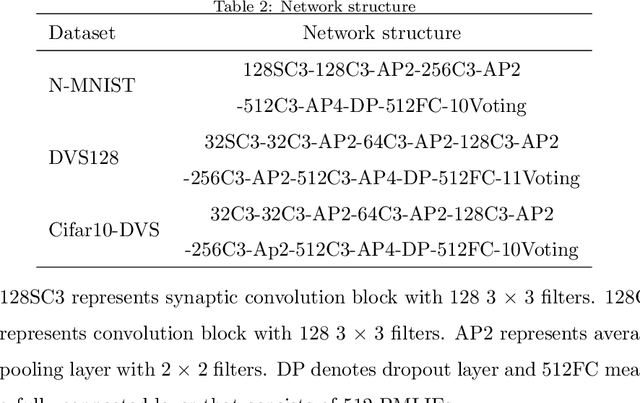
Spiking neural networks (SNNs), as one of the brain-inspired models, has spatio-temporal information processing capability, low power feature, and high biological plausibility. The effective spatio-temporal feature makes it suitable for event streams classification. However, neuromorphic datasets, such as N-MNIST, CIFAR10-DVS, DVS128-gesture, need to aggregate individual events into frames with a new higher temporal resolution for event stream classification, which causes high training and inference latency. In this work, we proposed a spatio-temporal compression method to aggregate individual events into a few time steps of synaptic current to reduce the training and inference latency. To keep the accuracy of SNNs under high compression ratios, we also proposed a synaptic convolutional block to balance the dramatic change between adjacent time steps. And multi-threshold Leaky Integrate-and-Fire (LIF) with learnable membrane time constant is introduced to increase its information processing capability. We evaluate the proposed method for event streams classification tasks on neuromorphic N-MNIST, CIFAR10-DVS, DVS128 gesture datasets. The experiment results show that our proposed method outperforms the state-of-the-art accuracy on nearly all datasets, using fewer time steps.
Self-supervised Point Cloud Registration with Deep Versatile Descriptors
Jan 25, 2022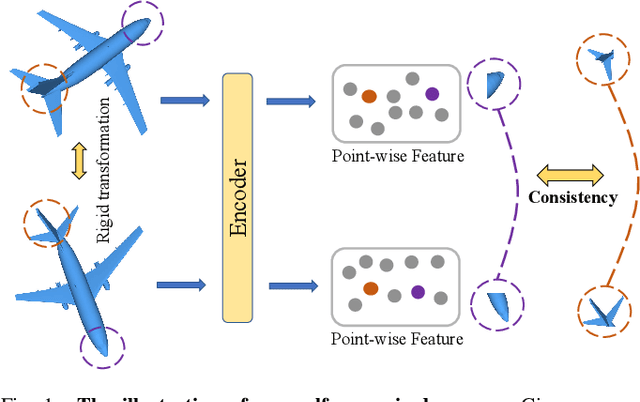

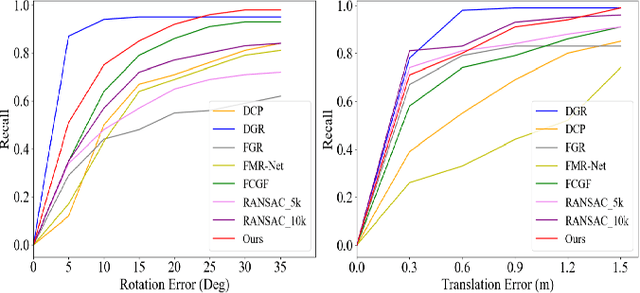
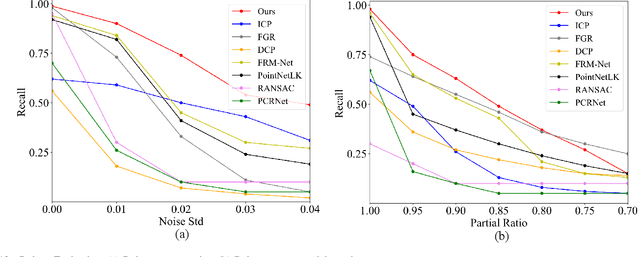
Recent years have witnessed an increasing trend toward solving point cloud registration problems with various deep learning-based algorithms. Compared to supervised/semi-supervised registration methods, unsupervised methods require no human annotations. However, unsupervised methods mainly depend on the global descriptors, which ignore the high-level representations of local geometries. In this paper, we propose a self-supervised registration scheme with a novel Deep Versatile Descriptors (DVD), jointly considering global representations and local representations. The DVD is motivated by a key observation that the local distinctive geometric structures of the point cloud by two subset points can be employed to enhance the representation ability of the feature extraction module. Furthermore, we utilize two additional tasks (reconstruction and normal estimation) to enhance the transformation awareness of the proposed DVDs. Lastly, we conduct extensive experiments on synthetic and real-world datasets, demonstrating that our method achieves state-of-the-art performance against competing methods over a wide range of experimental settings.
Direct Training via Backpropagation for Ultra-low Latency Spiking Neural Networks with Multi-threshold
Nov 25, 2021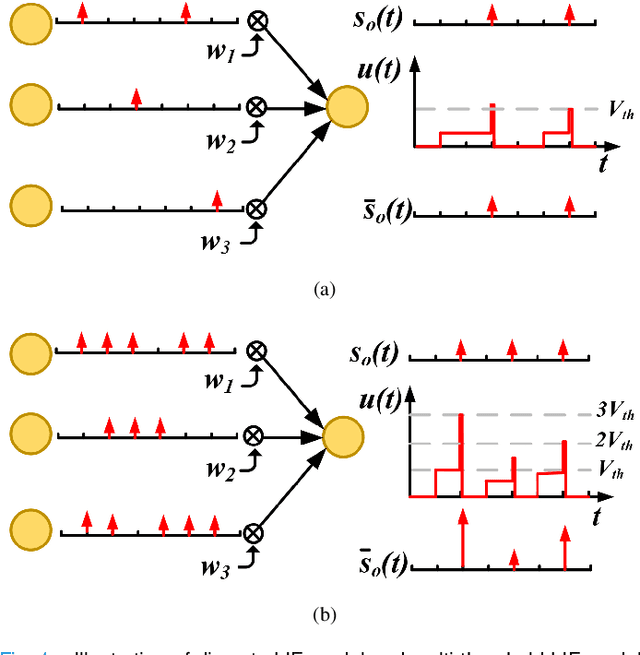
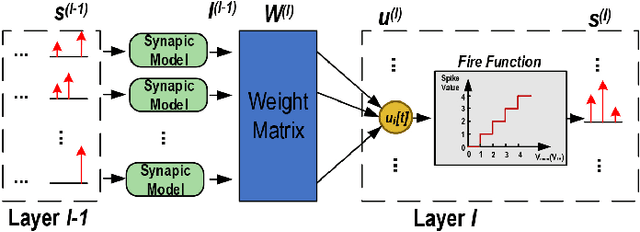
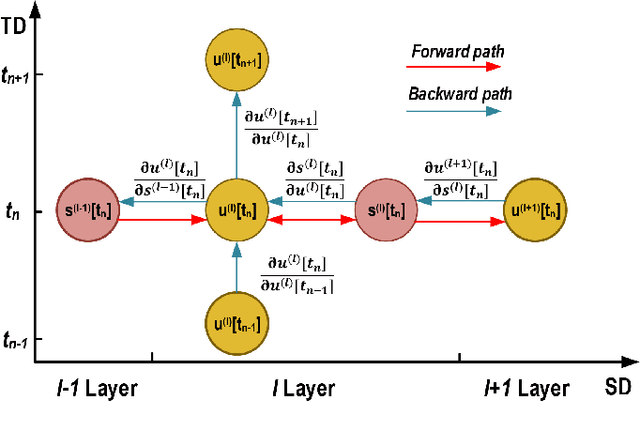
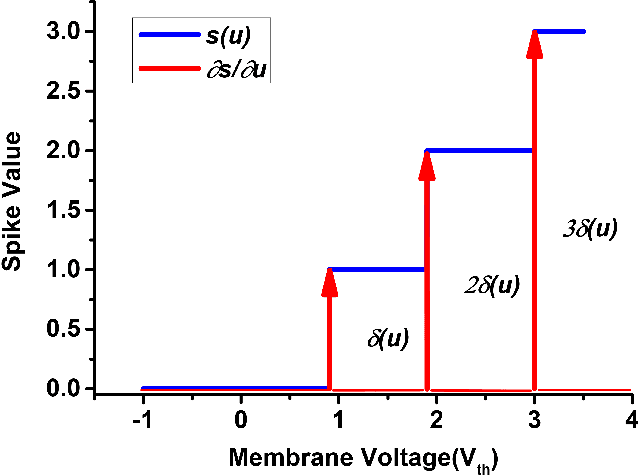
Spiking neural networks (SNNs) can utilize spatio-temporal information and have a nature of energy efficiency which is a good alternative to deep neural networks(DNNs). The event-driven information processing makes SNNs can reduce the expensive computation of DNNs and save a lot of energy consumption. However, high training and inference latency is a limitation of the development of deeper SNNs. SNNs usually need tens or even hundreds of time steps during the training and inference process which causes not only the increase of latency but also the waste of energy consumption. To overcome this problem, we proposed a novel training method based on backpropagation (BP) for ultra-low latency(1-2 time steps) SNN with multi-threshold. In order to increase the information capacity of each spike, we introduce the multi-threshold Leaky Integrate and Fired (LIF) model. In our proposed training method, we proposed three approximated derivative for spike activity to solve the problem of the non-differentiable issue which cause difficulties for direct training SNNs based on BP. The experimental results show that our proposed method achieves an average accuracy of 99.56%, 93.08%, and 87.90% on MNIST, FashionMNIST, and CIFAR10, respectively with only 2 time steps. For the CIFAR10 dataset, our proposed method achieve 1.12% accuracy improvement over the previously reported direct trained SNNs with fewer time steps.
A Self Contour-based Rotation and Translation-Invariant Transformation for Point Clouds Recognition
Sep 15, 2020
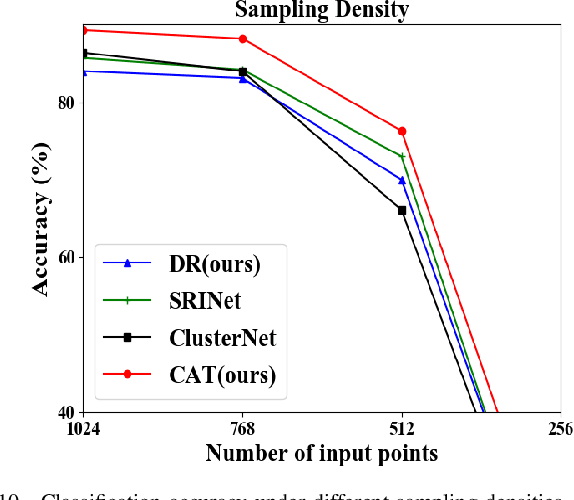
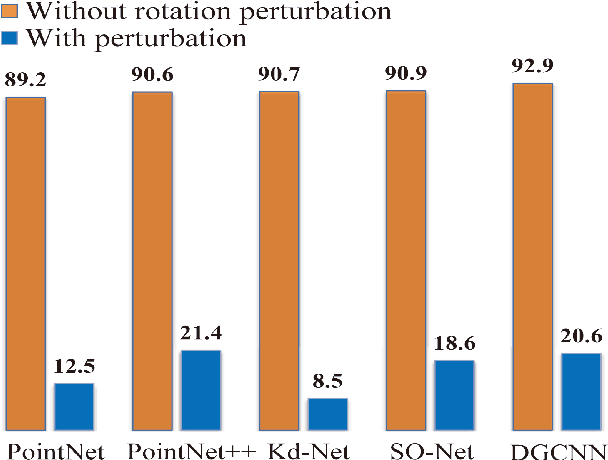
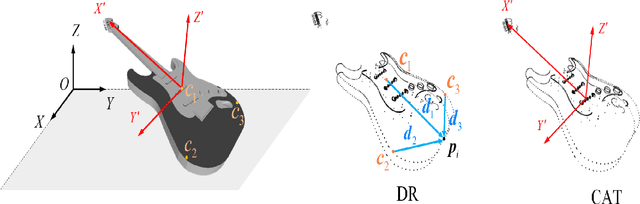
Recently, several direct processing point cloud models have achieved state-of-the-art performances for classification and segmentation tasks. However, these methods lack rotation robustness, and their performances degrade severely under random rotations, failing to extend to real-world applications with varying orientations. To address this problem, we propose a method named Self Contour-based Transformation (SCT), which can be flexibly integrated into a variety of existing point cloud recognition models against arbitrary rotations without any extra modifications. The SCT provides efficient and mathematically proved rotation and translation invariance by introducing Rotation and Translation-Invariant Transformation. It linearly transforms Cartesian coordinates of points to the self contour-based rotation-invariant representations while maintaining the global geometric structure. Moreover, to enhance discriminative feature extraction, the Frame Alignment module is further introduced, aiming to capture contours and transform self contour-based frames to the intra-class frame. Extensive experimental results and mathematical analyses show that the proposed method outperforms the state-of-the-art approaches under arbitrary rotations without any rotation augmentation on standard benchmarks, including ModelNet40, ScanObjectNN and ShapeNet.
Boosting Throughput and Efficiency of Hardware Spiking Neural Accelerators using Time Compression Supporting Multiple Spike Codes
Sep 10, 2019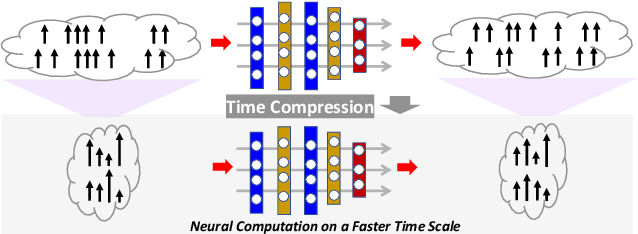
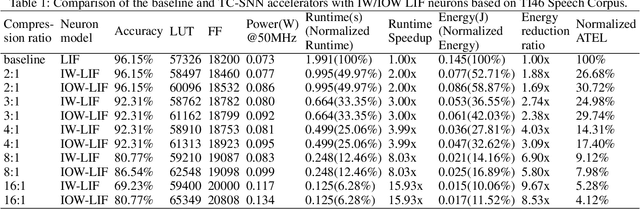
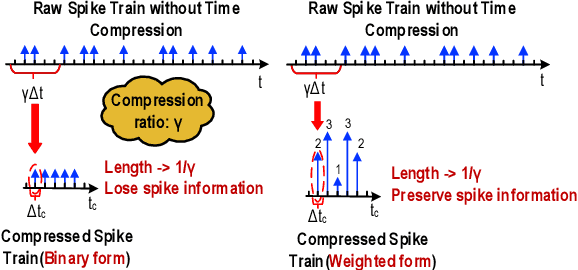
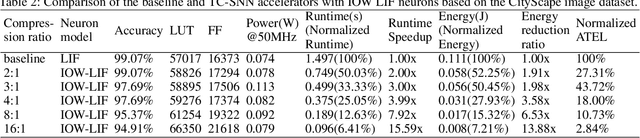
Spiking neural networks (SNNs) are the third generation of neural networks and can explore both rate and temporal coding for energy-efficient event-driven computation. However, the decision accuracy of existing SNN designs is contingent upon processing a large number of spikes over a long period. Nevertheless, the switching power of SNN hardware accelerators is proportional to the number of spikes processed while the length of spike trains limits throughput and static power efficiency. This paper presents the first study on developing temporal compression to significantly boost throughput and reduce energy dissipation of digital hardware SNN accelerators while being applicable to multiple spike codes. The proposed compression architectures consist of low-cost input spike compression units, novel input-and-output-weighted spiking neurons, and reconfigurable time constant scaling to support large and flexible time compression ratios. Our compression architectures can be transparently applied to any given pre-designed SNNs employing either rate or temporal codes while incurring minimal modification of the neural models, learning algorithms, and hardware design. Using spiking speech and image recognition datasets, we demonstrate the feasibility of supporting large time compression ratios of up to 16x, delivering up to 15.93x, 13.88x, and 86.21x improvements in throughput, energy dissipation, the tradeoffs between hardware area, runtime, energy, and classification accuracy, respectively based on different spike codes on a Xilinx Zynq-7000 FPGA. These results are achieved while incurring little extra hardware overhead.