 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Point Cloud Registration with Deep Versatile Descriptors
Jan 25, 2022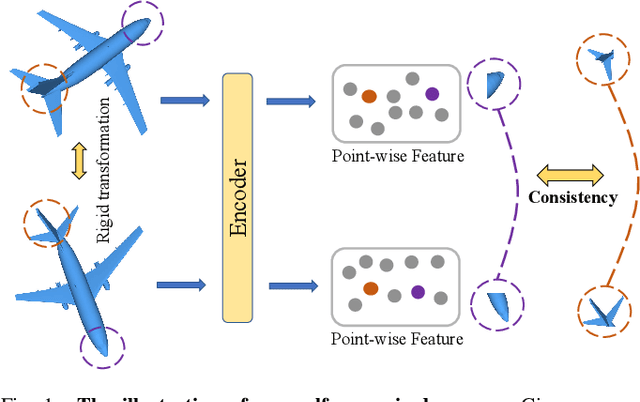

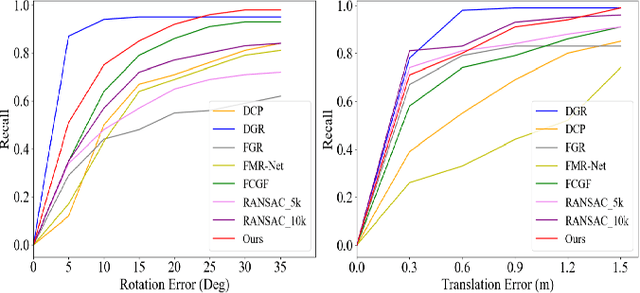
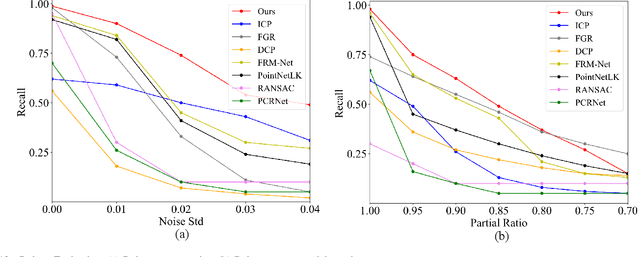
Recent years have witnessed an increasing trend toward solving point cloud registration problems with various deep learning-based algorithms. Compared to supervised/semi-supervised registration methods, unsupervised methods require no human annotations. However, unsupervised methods mainly depend on the global descriptors, which ignore the high-level representations of local geometries. In this paper, we propose a self-supervised registration scheme with a novel Deep Versatile Descriptors (DVD), jointly considering global representations and local representations. The DVD is motivated by a key observation that the local distinctive geometric structures of the point cloud by two subset points can be employed to enhance the representation ability of the feature extraction module. Furthermore, we utilize two additional tasks (reconstruction and normal estimation) to enhance the transformation awareness of the proposed DVDs. Lastly, we conduct extensive experiments on synthetic and real-world datasets, demonstrating that our method achieves state-of-the-art performance against competing methods over a wide range of experimental settings.
A Self Contour-based Rotation and Translation-Invariant Transformation for Point Clouds Recognition
Sep 15, 2020
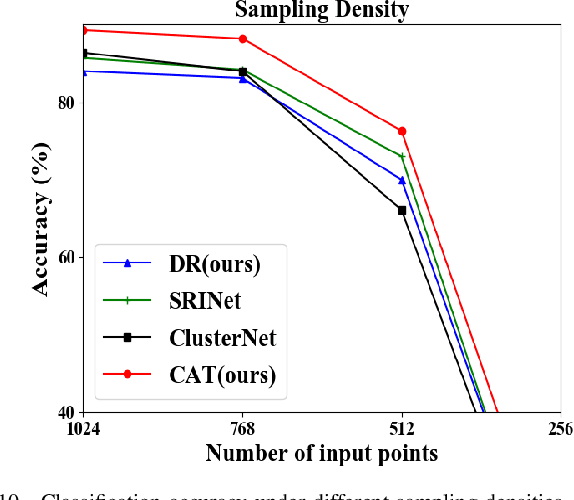
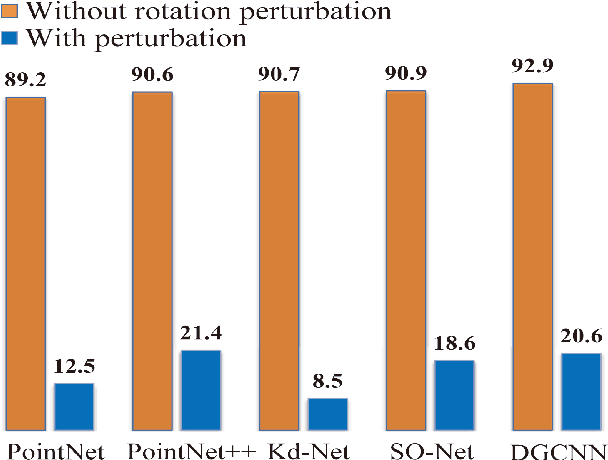
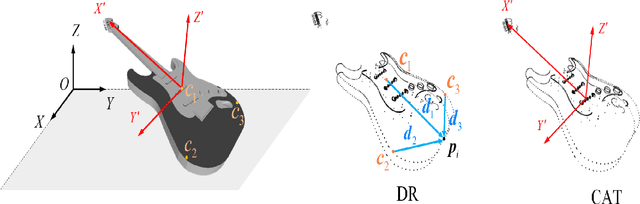
Recently, several direct processing point cloud models have achieved state-of-the-art performances for classification and segmentation tasks. However, these methods lack rotation robustness, and their performances degrade severely under random rotations, failing to extend to real-world applications with varying orientations. To address this problem, we propose a method named Self Contour-based Transformation (SCT), which can be flexibly integrated into a variety of existing point cloud recognition models against arbitrary rotations without any extra modifications. The SCT provides efficient and mathematically proved rotation and translation invariance by introducing Rotation and Translation-Invariant Transformation. It linearly transforms Cartesian coordinates of points to the self contour-based rotation-invariant representations while maintaining the global geometric structure. Moreover, to enhance discriminative feature extraction, the Frame Alignment module is further introduced, aiming to capture contours and transform self contour-based frames to the intra-class frame. Extensive experimental results and mathematical analyses show that the proposed method outperforms the state-of-the-art approaches under arbitrary rotations without any rotation augmentation on standard benchmarks, including ModelNet40, ScanObjectNN and ShapeNet.