 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo Streams and Two Resolution Spectrograms Model for End-to-end Automatic Speech Recognition
Paper and Code
Aug 18, 2021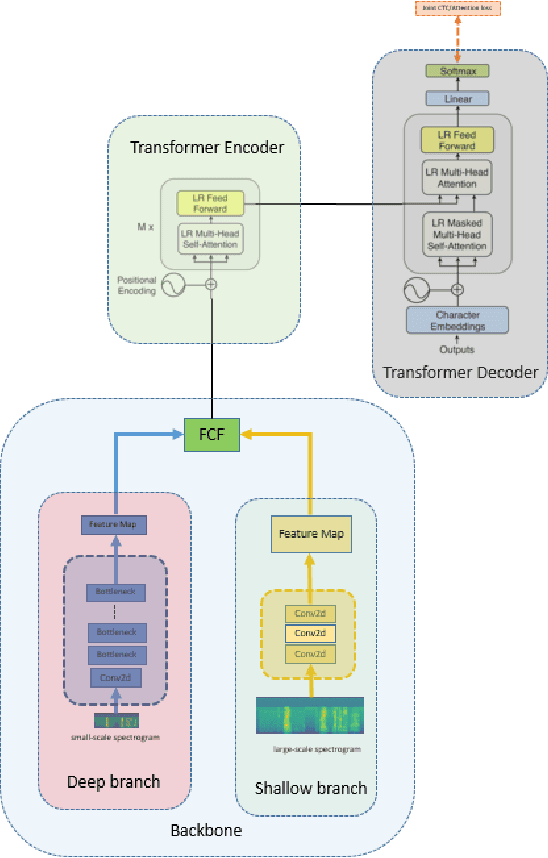
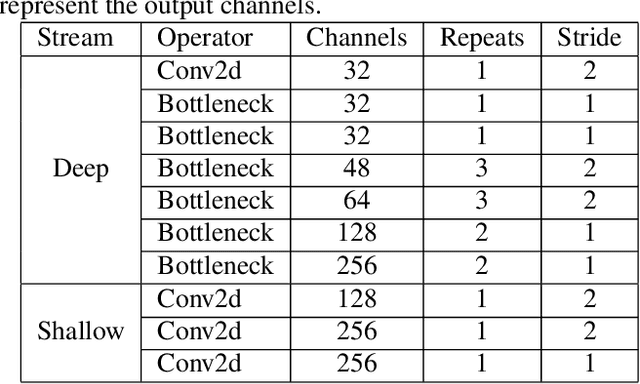

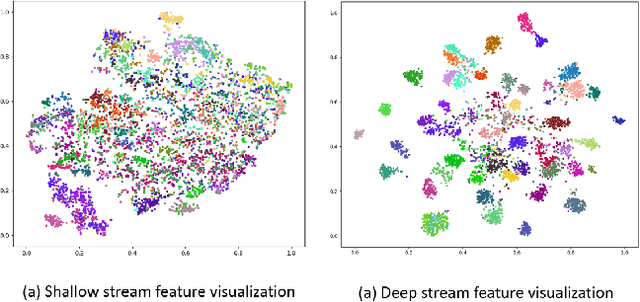
Transformer has shown tremendous progress in Automatic Speech Recognition (ASR), outperforming recurrent neural network-based approaches. Transformer architecture is good at parallelizing data to accelerate as well as capturing content-based global interaction. However, most studies with Transfomer have been utilized only shallow features extracted from the backbone without taking advantage of the deep feature that possesses invariant property. In this paper, we propose a novel framework with two streams that consist of different resolution spectrograms for each steam aiming to capture both shallow and deep features. The feature extraction module consists of a deep network for small resolution spectrogram and a shallow network for large resolution spectrogram. The backbone obtains not only detailed acoustic information for speech-text alignment but also sentence invariant features such as speaker information. Both features are fused with our proposed fusion method and then input into the Transformer encoder-decoder. With our method, the proposed framework shows competitive performance on Mandarin corpus. It outperforms various current state-of-the-art results on the HKUST Mandarian telephone ASR benchmark with a CER of 21.08. To the best of our knowledge, this is the first investigation of incorporating deep features to the backbone.