 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Interactive Image Inpainting via Sketch Refinement
Jun 14, 2023



One tough problem of image inpainting is to restore complex structures in the corrupted regions. It motivates interactive image inpainting which leverages additional hints, e.g., sketches, to assist the inpainting process. Sketch is simple and intuitive to end users, but meanwhile has free forms with much randomness. Such randomness may confuse the inpainting models, and incur severe artifacts in completed images. To address this problem, we propose a two-stage image inpainting method termed SketchRefiner. In the first stage, we propose using a cross-correlation loss function to robustly calibrate and refine the user-provided sketches in a coarse-to-fine fashion. In the second stage, we learn to extract informative features from the abstracted sketches in the feature space and modulate the inpainting process. We also propose an algorithm to simulate real sketches automatically and build a test protocol with different applications. Experimental results on public datasets demonstrate that SketchRefiner effectively utilizes sketch information and eliminates the artifacts due to the free-form sketches. Our method consistently outperforms the state-of-the-art ones both qualitatively and quantitatively, meanwhile revealing great potential in real-world applications. Our code and dataset are available.
Exploiting Optical Flow Guidance for Transformer-Based Video Inpainting
Jan 24, 2023Transformers have been widely used for video processing owing to the multi-head self attention (MHSA) mechanism. However, the MHSA mechanism encounters an intrinsic difficulty for video inpainting, since the features associated with the corrupted regions are degraded and incur inaccurate self attention. This problem, termed query degradation, may be mitigated by first completing optical flows and then using the flows to guide the self attention, which was verified in our previous work - flow-guided transformer (FGT). We further exploit the flow guidance and propose FGT++ to pursue more effective and efficient video inpainting. First, we design a lightweight flow completion network by using local aggregation and edge loss. Second, to address the query degradation, we propose a flow guidance feature integration module, which uses the motion discrepancy to enhance the features, together with a flow-guided feature propagation module that warps the features according to the flows. Third, we decouple the transformer along the temporal and spatial dimensions, where flows are used to select the tokens through a temporally deformable MHSA mechanism, and global tokens are combined with the inner-window local tokens through a dual perspective MHSA mechanism. FGT++ is experimentally evaluated to be outperforming the existing video inpainting networks qualitatively and quantitatively.
Generating Diverse Structure for Image Inpainting With Hierarchical VQ-VAE
Mar 18, 2021

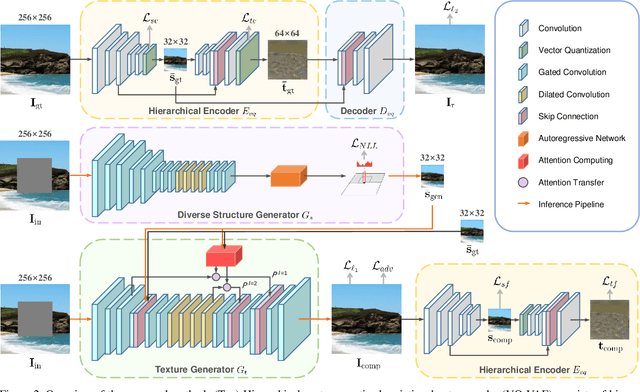
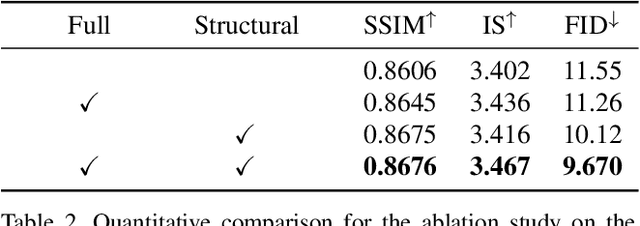
Given an incomplete image without additional constraint, image inpainting natively allows for multiple solutions as long as they appear plausible. Recently, multiplesolution inpainting methods have been proposed and shown the potential of generating diverse results. However, these methods have difficulty in ensuring the quality of each solution, e.g. they produce distorted structure and/or blurry texture. We propose a two-stage model for diverse inpainting, where the first stage generates multiple coarse results each of which has a different structure, and the second stage refines each coarse result separately by augmenting texture. The proposed model is inspired by the hierarchical vector quantized variational auto-encoder (VQ-VAE), whose hierarchical architecture isentangles structural and textural information. In addition, the vector quantization in VQVAE enables autoregressive modeling of the discrete distribution over the structural information. Sampling from the distribution can easily generate diverse and high-quality structures, making up the first stage of our model. In the second stage, we propose a structural attention module inside the texture generation network, where the module utilizes the structural information to capture distant correlations. We further reuse the VQ-VAE to calculate two feature losses, which help improve structure coherence and texture realism, respectively. Experimental results on CelebA-HQ, Places2, and ImageNet datasets show that our method not only enhances the diversity of the inpainting solutions but also improves the visual quality of the generated multiple images. Code and models are available at: https://github.com/USTC-JialunPeng/Diverse-Structure-Inpainting.