 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplanation is All You Need in Distillation: Mitigating Bias and Shortcut Learning
Paper and Code
Jul 13, 2024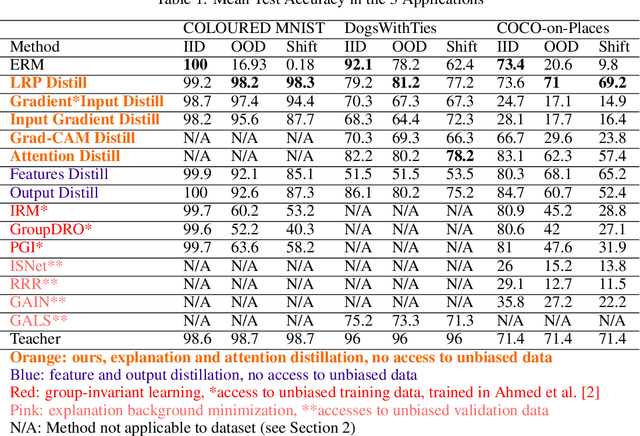


Bias and spurious correlations in data can cause shortcut learning, undermining out-of-distribution (OOD) generalization in deep neural networks. Most methods require unbiased data during training (and/or hyper-parameter tuning) to counteract shortcut learning. Here, we propose the use of explanation distillation to hinder shortcut learning. The technique does not assume any access to unbiased data, and it allows an arbitrarily sized student network to learn the reasons behind the decisions of an unbiased teacher, such as a vision-language model or a network processing debiased images. We found that it is possible to train a neural network with explanation (e.g by Layer Relevance Propagation, LRP) distillation only, and that the technique leads to high resistance to shortcut learning, surpassing group-invariant learning, explanation background minimization, and alternative distillation techniques. In the COLOURED MNIST dataset, LRP distillation achieved 98.2% OOD accuracy, while deep feature distillation and IRM achieved 92.1% and 60.2%, respectively. In COCO-on-Places, the undesirable generalization gap between in-distribution and OOD accuracy is only of 4.4% for LRP distillation, while the other two techniques present gaps of 15.1% and 52.1%, respectively.