 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Exact Finite-dimensional Explicit Feature Map for Kernel Functions
Oct 16, 2024Kernel methods in machine learning use a kernel function that takes two data points as input and returns their inner product after mapping them to a Hilbert space, implicitly and without actually computing the mapping. For many kernel functions, such as Gaussian and Laplacian kernels, the feature space is known to be infinite-dimensional, making operations in this space possible only implicitly. This implicit nature necessitates algorithms to be expressed using dual representations and the kernel trick. In this paper, given an arbitrary kernel function, we introduce an explicit, finite-dimensional feature map for any arbitrary kernel function that ensures the inner product of data points in the feature space equals the kernel function value, during both training and testing. The existence of this explicit mapping allows for kernelized algorithms to be formulated in their primal form, without the need for the kernel trick or the dual representation. As a first application, we demonstrate how to derive kernelized machine learning algorithms directly, without resorting to the dual representation, and apply this method specifically to PCA. As another application, without any changes to the t-SNE algorithm and its implementation, we use it for visualizing the feature space of kernel functions.
Adversarial Examples for Extreme Multilabel Text Classification
Dec 14, 2021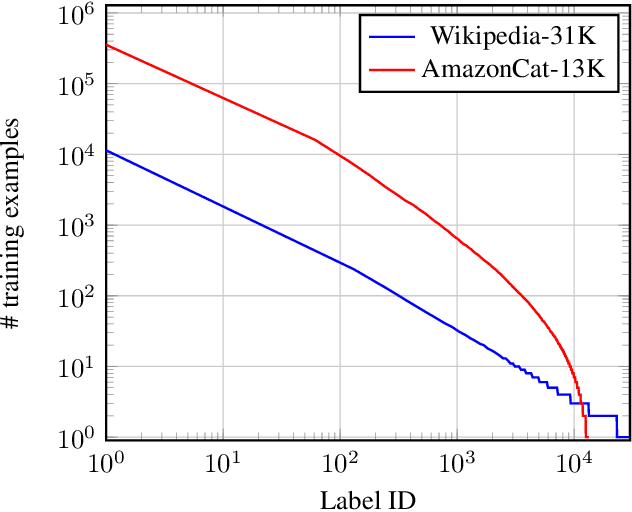


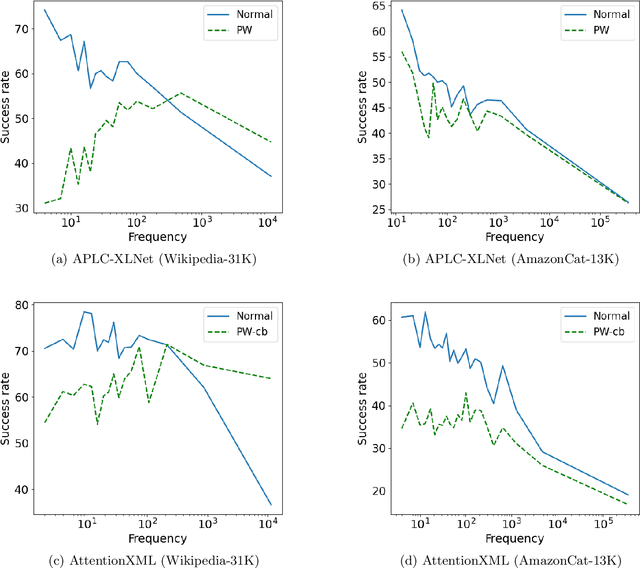
Extreme Multilabel Text Classification (XMTC) is a text classification problem in which, (i) the output space is extremely large, (ii) each data point may have multiple positive labels, and (iii) the data follows a strongly imbalanced distribution. With applications in recommendation systems and automatic tagging of web-scale documents, the research on XMTC has been focused on improving prediction accuracy and dealing with imbalanced data. However, the robustness of deep learning based XMTC models against adversarial examples has been largely underexplored. In this paper, we investigate the behaviour of XMTC models under adversarial attacks. To this end, first, we define adversarial attacks in multilabel text classification problems. We categorize attacking multilabel text classifiers as (a) positive-targeted, where the target positive label should fall out of top-k predicted labels, and (b) negative-targeted, where the target negative label should be among the top-k predicted labels. Then, by experiments on APLC-XLNet and AttentionXML, we show that XMTC models are highly vulnerable to positive-targeted attacks but more robust to negative-targeted ones. Furthermore, our experiments show that the success rate of positive-targeted adversarial attacks has an imbalanced distribution. More precisely, tail classes are highly vulnerable to adversarial attacks for which an attacker can generate adversarial samples with high similarity to the actual data-points. To overcome this problem, we explore the effect of rebalanced loss functions in XMTC where not only do they increase accuracy on tail classes, but they also improve the robustness of these classes against adversarial attacks. The code for our experiments is available at https://github.com/xmc-aalto/adv-xmtc
Neural Generalization of Multiple Kernel Learning
Feb 26, 2021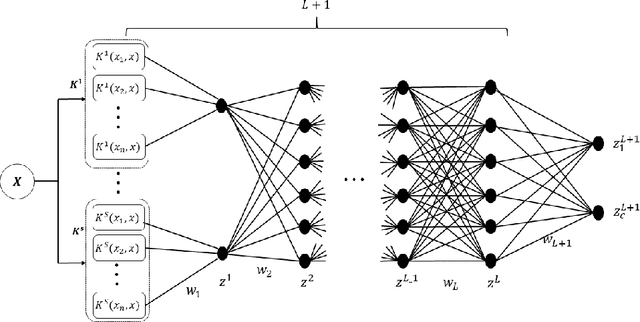

Multiple Kernel Learning is a conventional way to learn the kernel function in kernel-based methods. MKL algorithms enhance the performance of kernel methods. However, these methods have a lower complexity compared to deep learning models and are inferior to these models in terms of recognition accuracy. Deep learning models can learn complex functions by applying nonlinear transformations to data through several layers. In this paper, we show that a typical MKL algorithm can be interpreted as a one-layer neural network with linear activation functions. By this interpretation, we propose a Neural Generalization of Multiple Kernel Learning (NGMKL), which extends the conventional multiple kernel learning framework to a multi-layer neural network with nonlinear activation functions. Our experiments on several benchmarks show that the proposed method improves the complexity of MKL algorithms and leads to higher recognition accuracy.
Unbiased Loss Functions for Extreme Classification With Missing Labels
Jul 01, 2020

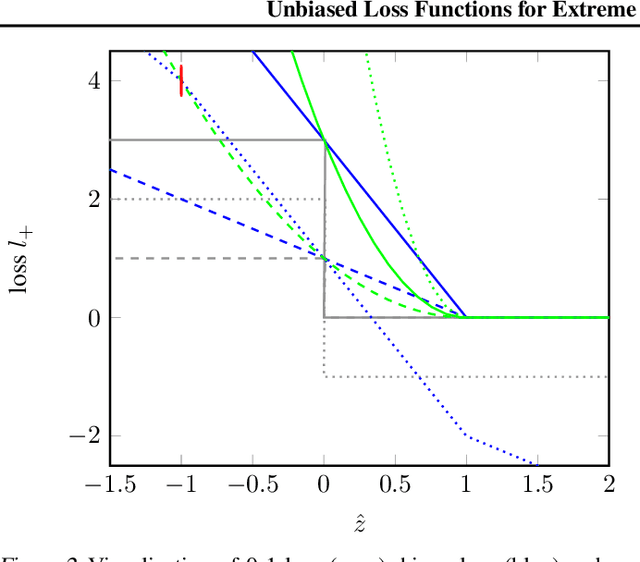
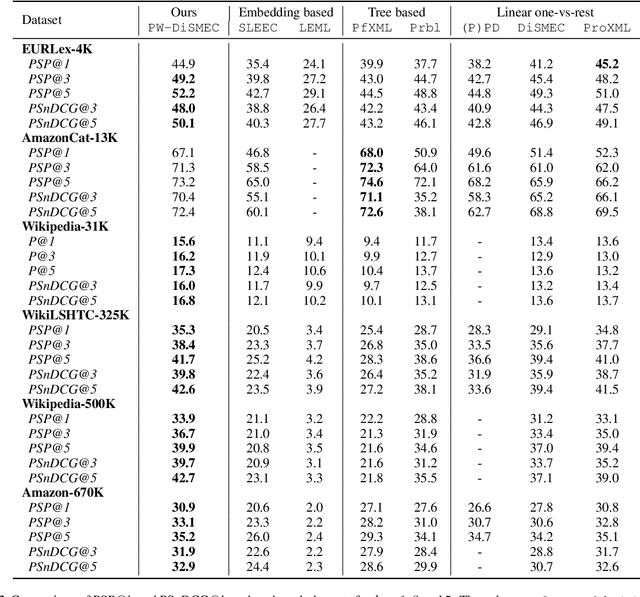
The goal in extreme multi-label classification (XMC) is to tag an instance with a small subset of relevant labels from an extremely large set of possible labels. In addition to the computational burden arising from large number of training instances, features and labels, problems in XMC are faced with two statistical challenges, (i) large number of 'tail-labels' -- those which occur very infrequently, and (ii) missing labels as it is virtually impossible to manually assign every relevant label to an instance. In this work, we derive an unbiased estimator for general formulation of loss functions which decompose over labels, and then infer the forms for commonly used loss functions such as hinge- and squared-hinge-loss and binary cross-entropy loss. We show that the derived unbiased estimators, in the form of appropriate weighting factors, can be easily incorporated in state-of-the-art algorithms for extreme classification, thereby scaling to datasets with hundreds of thousand labels. However, empirically, we find a slightly altered version that gives more relative weight to tail labels to perform even better. We suspect is due to the label imbalance in the dataset, which is not explicitly addressed by our theoretically derived estimator. Minimizing the proposed loss functions leads to significant improvement over existing methods (up to 20% in some cases) on benchmark datasets in XMC.