 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnbiased Loss Functions for Extreme Classification With Missing Labels
Paper and Code
Jul 01, 2020

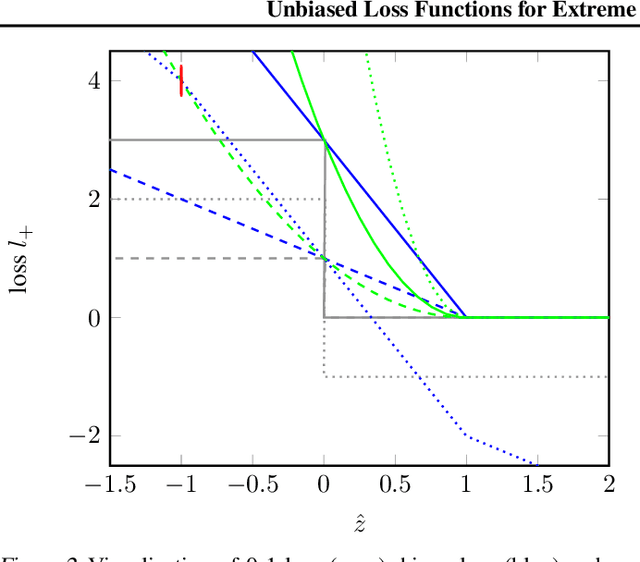
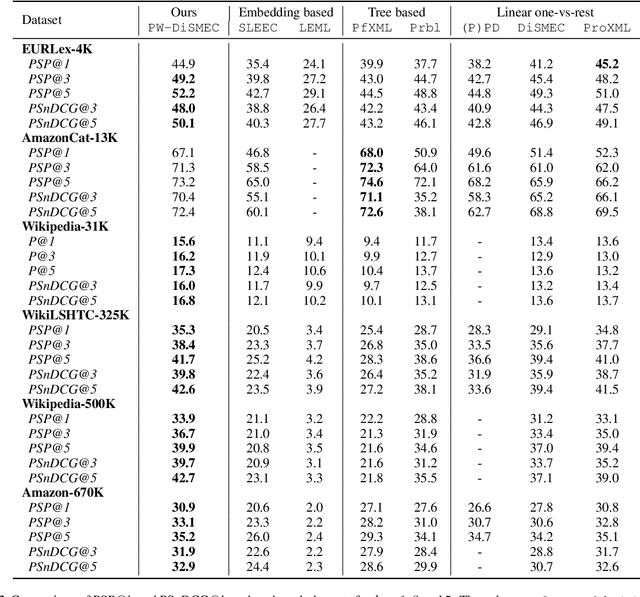
The goal in extreme multi-label classification (XMC) is to tag an instance with a small subset of relevant labels from an extremely large set of possible labels. In addition to the computational burden arising from large number of training instances, features and labels, problems in XMC are faced with two statistical challenges, (i) large number of 'tail-labels' -- those which occur very infrequently, and (ii) missing labels as it is virtually impossible to manually assign every relevant label to an instance. In this work, we derive an unbiased estimator for general formulation of loss functions which decompose over labels, and then infer the forms for commonly used loss functions such as hinge- and squared-hinge-loss and binary cross-entropy loss. We show that the derived unbiased estimators, in the form of appropriate weighting factors, can be easily incorporated in state-of-the-art algorithms for extreme classification, thereby scaling to datasets with hundreds of thousand labels. However, empirically, we find a slightly altered version that gives more relative weight to tail labels to perform even better. We suspect is due to the label imbalance in the dataset, which is not explicitly addressed by our theoretically derived estimator. Minimizing the proposed loss functions leads to significant improvement over existing methods (up to 20% in some cases) on benchmark datasets in XMC.