 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMechanics of Learned Reasoning 1: TempoBench, A Benchmark for Interpretable Deconstruction of Reasoning System Performance
Oct 31, 2025Large Language Models (LLMs) are increasingly excelling and outpacing human performance on many tasks. However, to improve LLM reasoning, researchers either rely on ad-hoc generated datasets or formal mathematical proof systems such as the Lean proof assistant. Whilst ad-hoc generated methods can capture the decision chains of real-world reasoning processes, they may encode some inadvertent bias in the space of reasoning they cover; they also cannot be formally verified. On the other hand, systems like Lean can guarantee verifiability, but are not well-suited to capture the nature of agentic decision chain-based tasks. This creates a gap both in performance for functions such as business agents or code assistants, and in the usefulness of LLM reasoning benchmarks, whereby these fall short in reasoning structure or real-world alignment. We introduce TempoBench, the first formally grounded and verifiable diagnostic benchmark that parametrizes difficulty to systematically analyze how LLMs perform reasoning. TempoBench uses two evaluation benchmarks to break down reasoning ability. First, temporal trace evaluation (TTE) tests the ability of an LLM to understand and simulate the execution of a given multi-step reasoning system. Subsequently, temporal causal evaluation (TCE) tests an LLM's ability to perform multi-step causal reasoning and to distill cause-and-effect relations from complex systems. We find that models score 65.6% on TCE-normal, and 7.5% on TCE-hard. This shows that state-of-the-art LLMs clearly understand the TCE task but perform poorly as system complexity increases. Our code is available at our \href{https://github.com/nik-hz/tempobench}{GitHub repository}.
Embedding Alignment in Code Generation for Audio
Aug 07, 2025LLM-powered code generation has the potential to revolutionize creative coding endeavors, such as live-coding, by enabling users to focus on structural motifs over syntactic details. In such domains, when prompting an LLM, users may benefit from considering multiple varied code candidates to better realize their musical intentions. Code generation models, however, struggle to present unique and diverse code candidates, with no direct insight into the code's audio output. To better establish a relationship between code candidates and produced audio, we investigate the topology of the mapping between code and audio embedding spaces. We find that code and audio embeddings do not exhibit a simple linear relationship, but supplement this with a constructed predictive model that shows an embedding alignment map could be learned. Supplementing the aim for musically diverse output, we present a model that given code predicts output audio embedding, constructing a code-audio embedding alignment map.
Research Vision: Multi-Agent Path Planning for Cops And Robbers Via Reactive Synthesis
Mar 14, 2025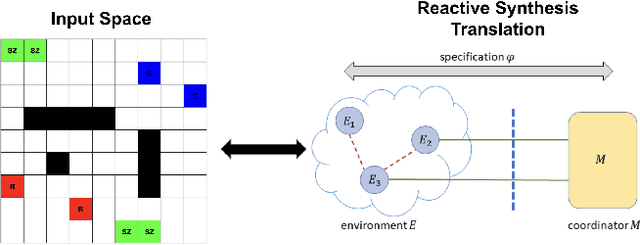

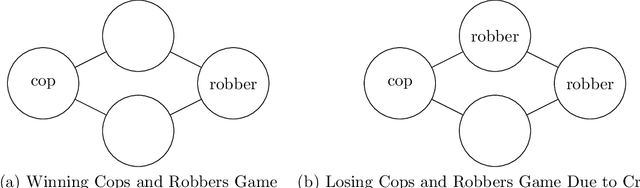
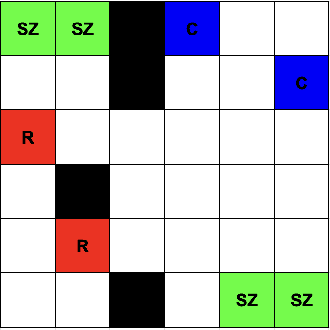
We propose the problem of multi-agent path planning for a generalization of the classic Cops and Robbers game via reactive synthesis. Specifically, through the application of LTLt and Coordination Synthesis, we aim to check whether various Cops and Robbers games are realizable (a strategy exists for the cops which guarantees they catch the robbers). Additionally, we construct this strategy as an executable program for the multiple system players in our games. In this paper we formalize the problem space, and propose potential directions for solutions. We also show how our formalization of this generalized cops and robbers game can be mapped to a broad range of other problems in the reactive program synthesis space.
Using a Feedback Loop for LLM-based Infrastructure as Code Generation
Nov 28, 2024
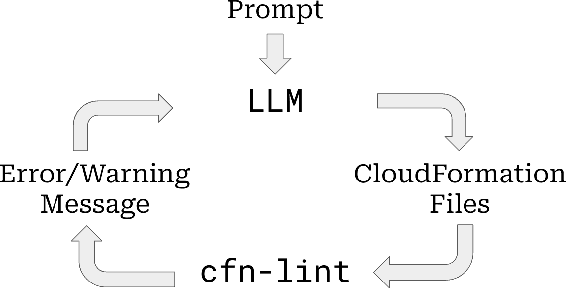
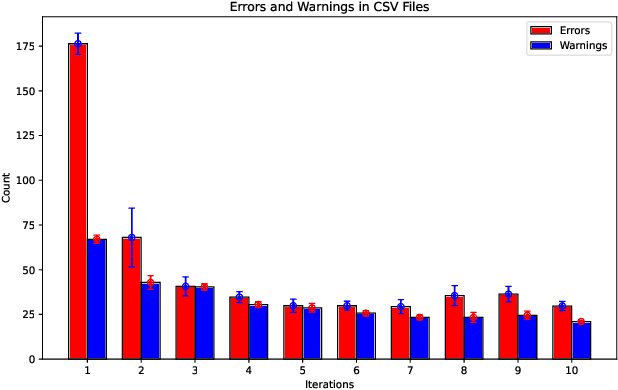
Code generation with Large Language Models (LLMs) has helped to increase software developer productivity in coding tasks, but has yet to have significant impact on the tasks of software developers that surround this code. In particular, the challenge of infrastructure management remains an open question. We investigate the ability of an LLM agent to construct infrastructure using the Infrastructure as Code (IaC) paradigm. We particularly investigate the use of a feedback loop that returns errors and warnings on the generated IaC to allow the LLM agent to improve the code. We find that, for each iteration of the loop, its effectiveness decreases exponentially until it plateaus at a certain point and becomes ineffective.
Benchmarking LLM Code Generation for Audio Programming with Visual Dataflow Languages
Sep 01, 2024



Node-based programming languages are increasingly popular in media arts coding domains. These languages are designed to be accessible to users with limited coding experience, allowing them to achieve creative output without an extensive programming background. Using LLM-based code generation to further lower the barrier to creative output is an exciting opportunity. However, the best strategy for code generation for visual node-based programming languages is still an open question. In particular, such languages have multiple levels of representation in text, each of which may be used for code generation. In this work, we explore the performance of LLM code generation in audio programming tasks in visual programming languages at multiple levels of representation. We explore code generation through metaprogramming code representations for these languages (i.e., coding the language using a different high-level text-based programming language), as well as through direct node generation with JSON. We evaluate code generated in this way for two visual languages for audio programming on a benchmark set of coding problems. We measure both correctness and complexity of the generated code. We find that metaprogramming results in more semantically correct generated code, given that the code is well-formed (i.e., is syntactically correct and runs). We also find that prompting for richer metaprogramming using randomness and loops led to more complex code.
Guiding LLM Temporal Logic Generation with Explicit Separation of Data and Control
Jun 11, 2024Temporal logics are powerful tools that are widely used for the synthesis and verification of reactive systems. The recent progress on Large Language Models (LLMs) has the potential to make the process of writing such specifications more accessible. However, writing specifications in temporal logics remains challenging for all but the most expert users. A key question in using LLMs for temporal logic specification engineering is to understand what kind of guidance is most helpful to the LLM and the users to easily produce specifications. Looking specifically at the problem of reactive program synthesis, we explore the impact of providing an LLM with guidance on the separation of control and data--making explicit for the LLM what functionality is relevant for the specification, and treating the remaining functionality as an implementation detail for a series of pre-defined functions and predicates. We present a benchmark set and find that this separation of concerns improves specification generation. Our benchmark provides a test set against which to verify future work in LLM generation of temporal logic specifications.
Enforcing Temporal Constraints on Generative Agent Behavior with Reactive Synthesis
Feb 24, 2024The surge in popularity of Large Language Models (LLMs) has opened doors for new approaches to the creation of interactive agents. However, managing the temporal behavior of such agents over the course of an interaction remains challenging. The stateful, long-term horizon and quantitative reasoning required for coherent agent behavior does not fit well into the LLM paradigm. We propose a combination of formal logic-based program synthesis and LLM content generation to create generative agents that adhere to temporal constraints. Our approach uses Temporal Stream Logic (TSL) to generate an automaton that enforces a temporal structure on an agent and leaves the details of each action for a moment in time to an LLM. By using TSL, we are able to augment the generative agent where users have a higher level of guarantees on behavior, better interpretability of the system, and more ability to build agents in a modular way. We evaluate our approach on different tasks involved in creating a coherent interactive agent specialized for various application domains. We found that over all of the tasks, our approach using TSL achieves at least 96% adherence, whereas the pure LLM-based approach demonstrates as low as 14.67% adherence.
Succinct Explanations With Cascading Decision Trees
Oct 13, 2020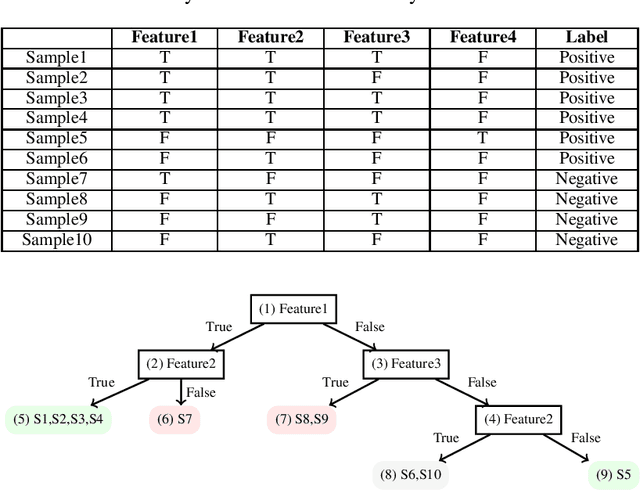
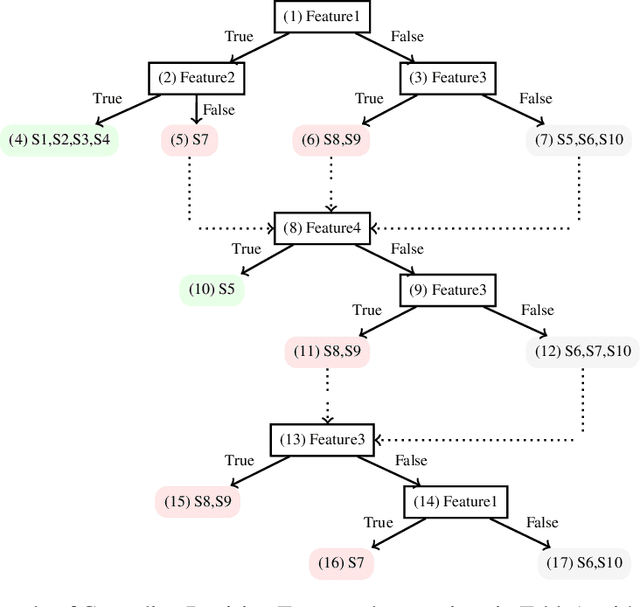

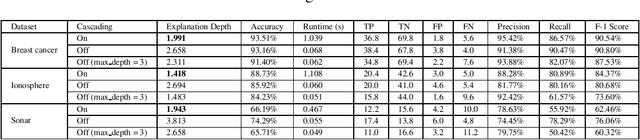
Classic decision tree learning is a binary classification algorithm that constructs models with first-class transparency - every classification has a directly derivable explanation. However, learning decision trees on modern datasets generates large trees, which in turn generate decision paths of excessive depth, obscuring the explanation of classifications. To improve the comprehensibility of classifications, we propose a new decision tree model that we call Cascading Decision Trees. Cascading Decision Trees shorten the size of explanations of classifications, without sacrificing model performance overall. Our key insight is to separate the notion of a decision path and an explanation path. Utilizing this insight, instead of having one monolithic decision tree, we build several smaller decision subtrees and cascade them in sequence. Our cascading decision subtrees are designed to specifically target explanations for positive classifications. This way each subtree identifies the smallest set of features that can classify as many positive samples as possible, without misclassifying any negative samples. Applying cascading decision trees to new samples results in a significantly shorter and succinct explanation, if one of the subtrees detects a positive classification. In that case, we immediately stop and report the decision path of only the current subtree to the user as an explanation for the classification. We evaluate our algorithm on standard datasets, as well as new real-world applications and find that our model shortens the explanation depth by over 40.8% for positive classifications compared to the classic decision tree model.
Grammar Filtering For Syntax-Guided Synthesis
Feb 07, 2020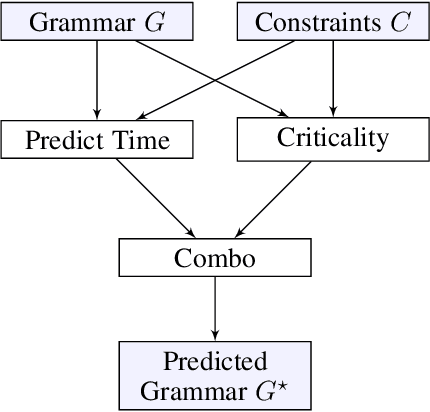
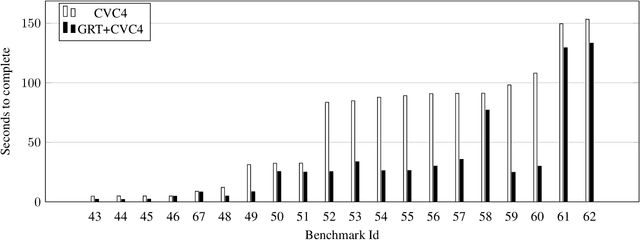
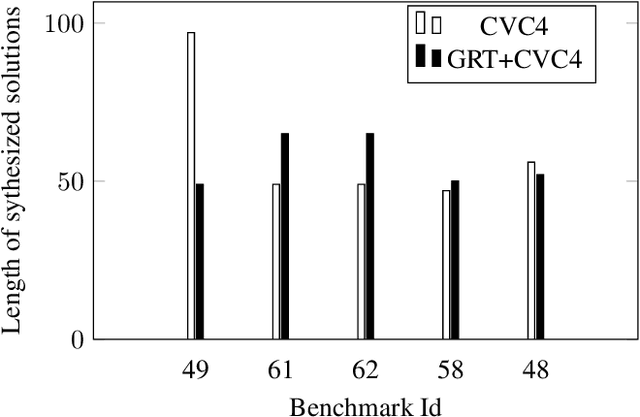
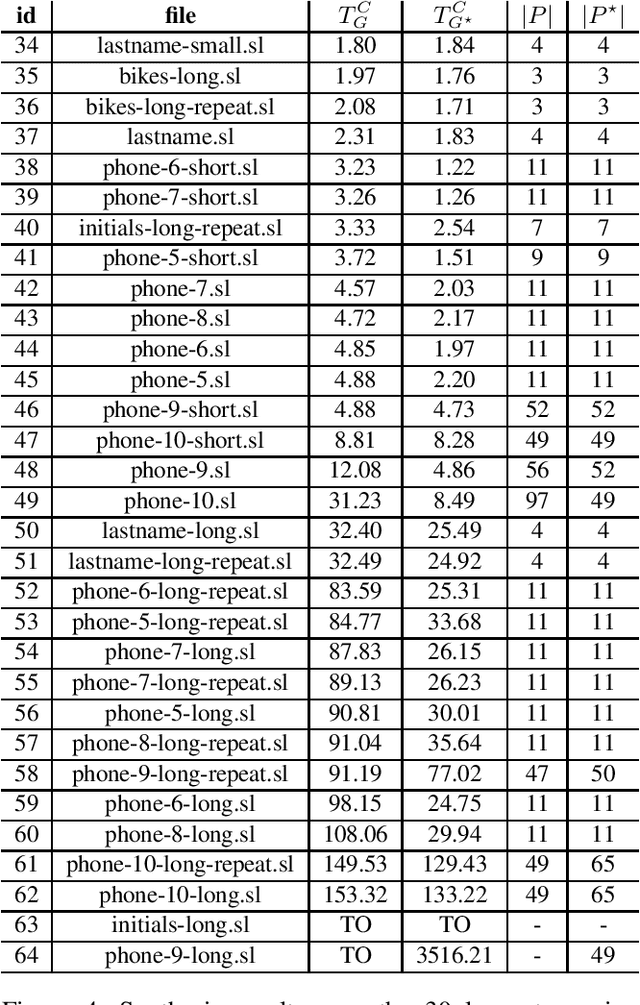
Programming-by-example (PBE) is a synthesis paradigm that allows users to generate functions by simply providing input-output examples. While a promising interaction paradigm, synthesis is still too slow for realtime interaction and more widespread adoption. Existing approaches to PBE synthesis have used automated reasoning tools, such as SMT solvers, as well as works applying machine learning techniques. At its core, the automated reasoning approach relies on highly domain specific knowledge of programming languages. On the other hand, the machine learning approaches utilize the fact that when working with program code, it is possible to generate arbitrarily large training datasets. In this work, we propose a system for using machine learning in tandem with automated reasoning techniques to solve Syntax Guided Synthesis (SyGuS) style PBE problems. By preprocessing SyGuS PBE problems with a neural network, we can use a data driven approach to reduce the size of the search space, then allow automated reasoning-based solvers to more quickly find a solution analytically. Our system is able to run atop existing SyGuS PBE synthesis tools, decreasing the runtime of the winner of the 2019 SyGuS Competition for the PBE Strings track by 47.65% to outperform all of the competing tools.