 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Are You Weird? Infusing Interpretability in Isolation Forest for Anomaly Detection
Paper and Code
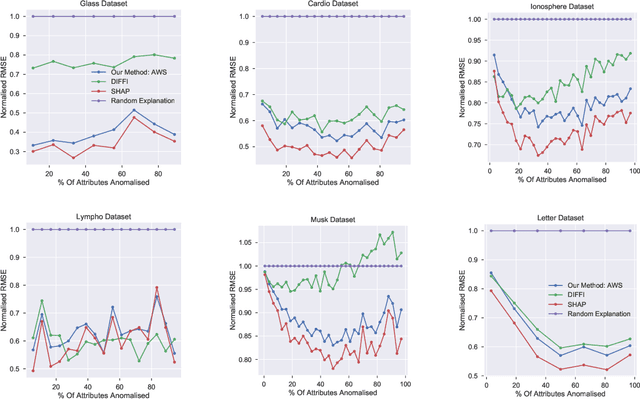
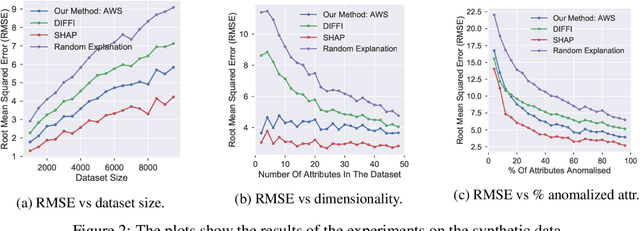
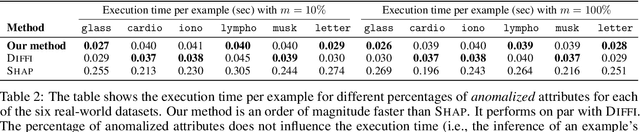
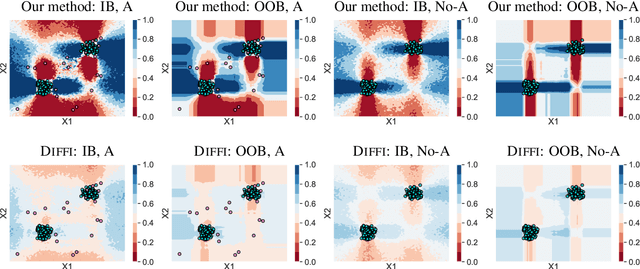
Anomaly detection is concerned with identifying examples in a dataset that do not conform to the expected behaviour. While a vast amount of anomaly detection algorithms exist, little attention has been paid to explaining why these algorithms flag certain examples as anomalies. However, such an explanation could be extremely useful to anyone interpreting the algorithms' output. This paper develops a method to explain the anomaly predictions of the state-of-the-art Isolation Forest anomaly detection algorithm. The method outputs an explanation vector that captures how important each attribute of an example is to identifying it as anomalous. A thorough experimental evaluation on both synthetic and real-world datasets shows that our method is more accurate and more efficient than most contemporary state-of-the-art explainability methods.