 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimultaneous Identification of Sparse Structures and Communities in Heterogeneous Graphical Models
May 16, 2024Exploring and detecting community structures hold significant importance in genetics, social sciences, neuroscience, and finance. Especially in graphical models, community detection can encourage the exploration of sets of variables with group-like properties. In this paper, within the framework of Gaussian graphical models, we introduce a novel decomposition of the underlying graphical structure into a sparse part and low-rank diagonal blocks (non-overlapped communities). We illustrate the significance of this decomposition through two modeling perspectives and propose a three-stage estimation procedure with a fast and efficient algorithm for the identification of the sparse structure and communities. Also on the theoretical front, we establish conditions for local identifiability and extend the traditional irrepresentability condition to an adaptive form by constructing an effective norm, which ensures the consistency of model selection for the adaptive $\ell_1$ penalized estimator in the second stage. Moreover, we also provide the clustering error bound for the K-means procedure in the third stage. Extensive numerical experiments are conducted to demonstrate the superiority of the proposed method over existing approaches in estimating graph structures. Furthermore, we apply our method to the stock return data, revealing its capability to accurately identify non-overlapped community structures.
Subtask Analysis of Process Data Through a Predictive Model
Aug 29, 2020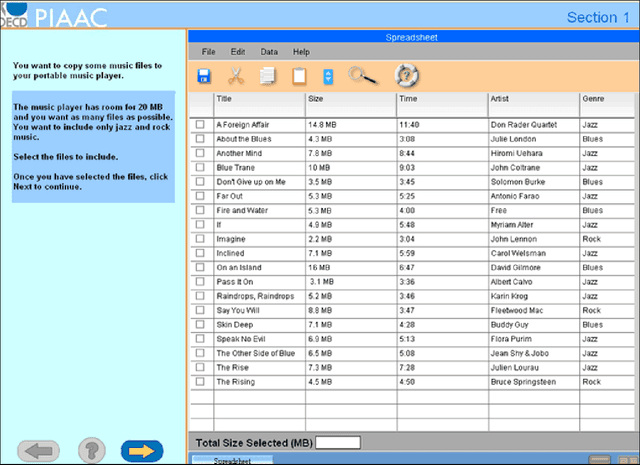

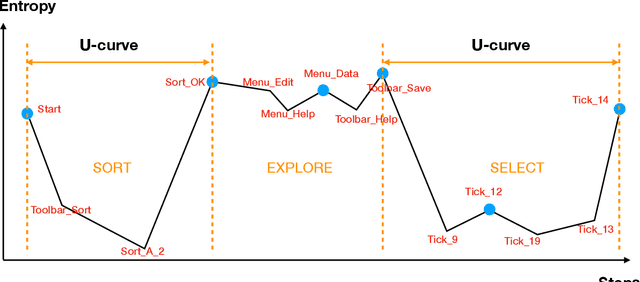
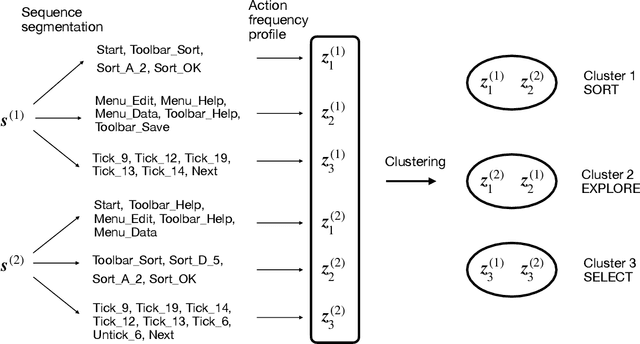
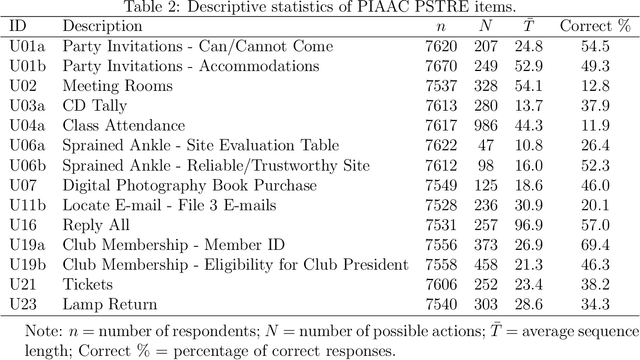
Response process data collected from human-computer interactive items contain rich information about respondents' behavioral patterns and cognitive processes. Their irregular formats as well as their large sizes make standard statistical tools difficult to apply. This paper develops a computationally efficient method for exploratory analysis of such process data. The new approach segments a lengthy individual process into a sequence of short subprocesses to achieve complexity reduction, easy clustering and meaningful interpretation. Each subprocess is considered a subtask. The segmentation is based on sequential action predictability using a parsimonious predictive model combined with the Shannon entropy. Simulation studies are conducted to assess performance of the new methods. We use the process data from PIAAC 2012 to demonstrate how exploratory analysis of process data can be done with the new approach.
ProcData: An R Package for Process Data Analysis
Jun 09, 2020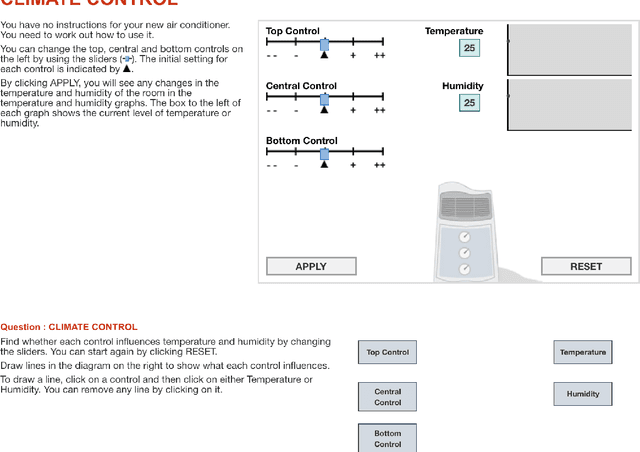


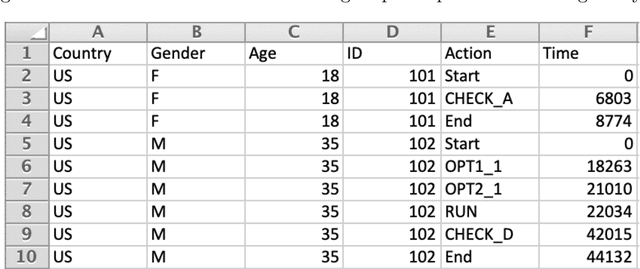
Process data refer to data recorded in the log files of computer-based items. These data, represented as timestamped action sequences, keep track of respondents' response processes of solving the items. Process data analysis aims at enhancing educational assessment accuracy and serving other assessment purposes by utilizing the rich information contained in response processes. The R package ProcData presented in this article is designed to provide tools for processing, describing, and analyzing process data. We define an S3 class "proc" for organizing process data and extend generic methods summary and print for class "proc". Two feature extraction methods for process data are implemented in the package for compressing information in the irregular response processes into regular numeric vectors. ProcData also provides functions for fitting and making predictions from a neural-network-based sequence model. These functions call relevant functions in package keras for constructing and training neural networks. In addition, several response process generators and a real dataset of response processes of the climate control item in the 2012 Programme for International Student Assessment are included in the package.
An Exploratory Analysis of the Latent Structure of Process Data via Action Sequence Autoencoder
Aug 16, 2019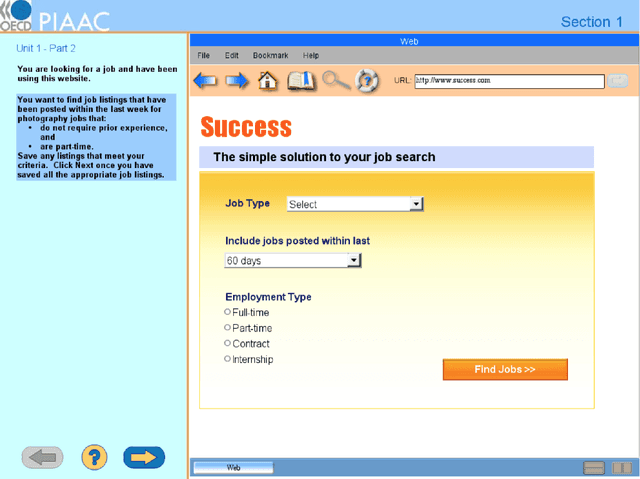
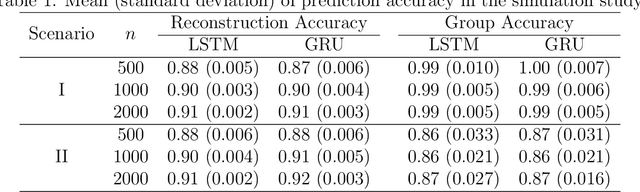
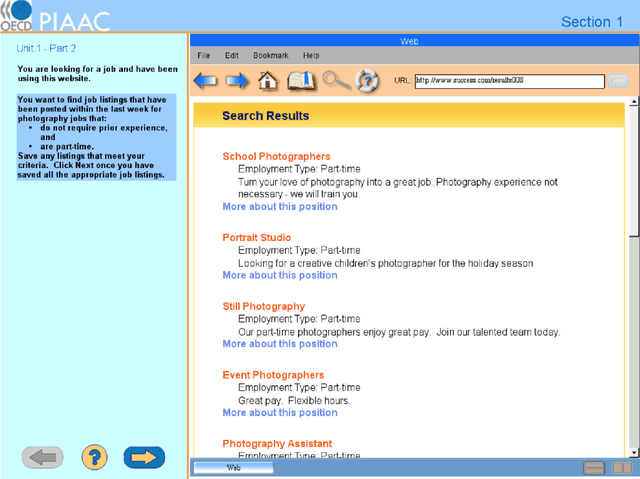
Computer simulations have become a popular tool of assessing complex skills such as problem-solving skills. Log files of computer-based items record the entire human-computer interactive processes for each respondent. The response processes are very diverse, noisy, and of nonstandard formats. Few generic methods have been developed for exploiting the information contained in process data. In this article, we propose a method to extract latent variables from process data. The method utilizes a sequence-to-sequence autoencoder to compress response processes into standard numerical vectors. It does not require prior knowledge of the specific items and human-computers interaction patterns. The proposed method is applied to both simulated and real process data to demonstrate that the resulting latent variables extract useful information from the response processes.
Likelihood Adaptively Modified Penalties
Aug 23, 2013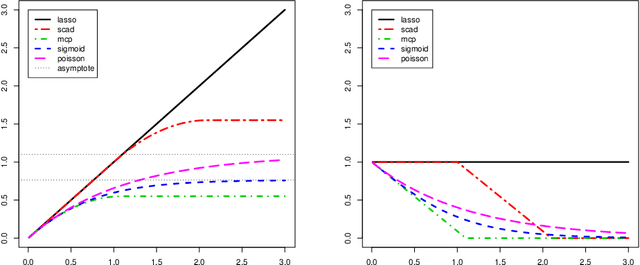
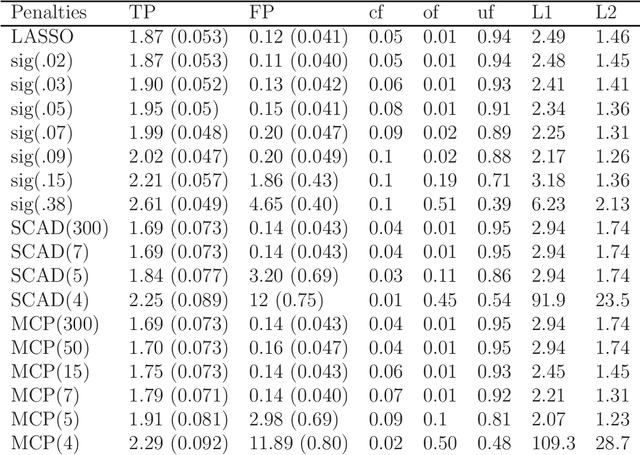
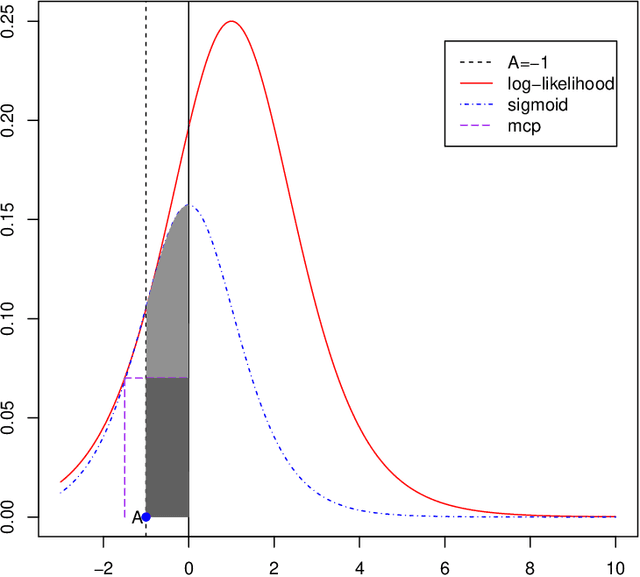
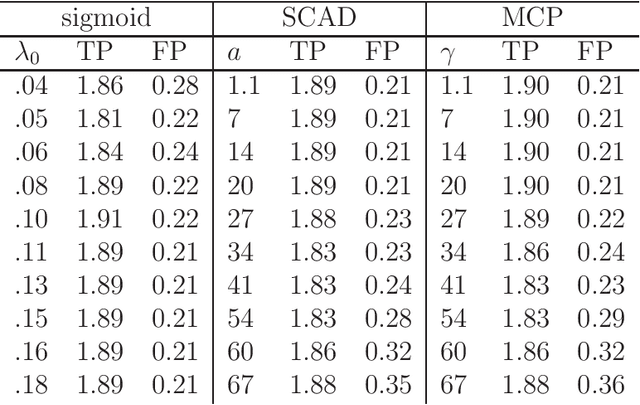
A new family of penalty functions, adaptive to likelihood, is introduced for model selection in general regression models. It arises naturally through assuming certain types of prior distribution on the regression parameters. To study stability properties of the penalized maximum likelihood estimator, two types of asymptotic stability are defined. Theoretical properties, including the parameter estimation consistency, model selection consistency, and asymptotic stability, are established under suitable regularity conditions. An efficient coordinate-descent algorithm is proposed. Simulation results and real data analysis show that the proposed method has competitive performance in comparison with existing ones.
Focus of Attention for Linear Predictors
Dec 29, 2012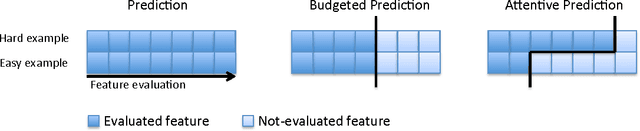
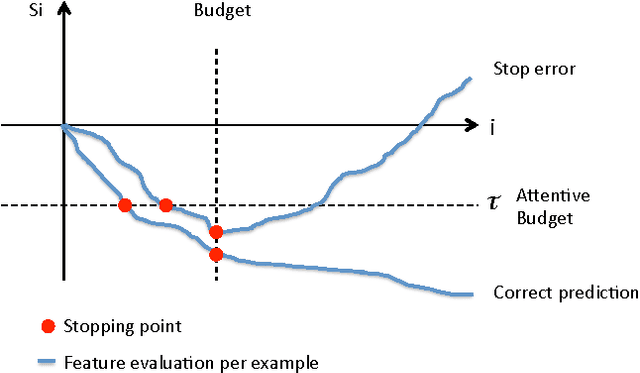
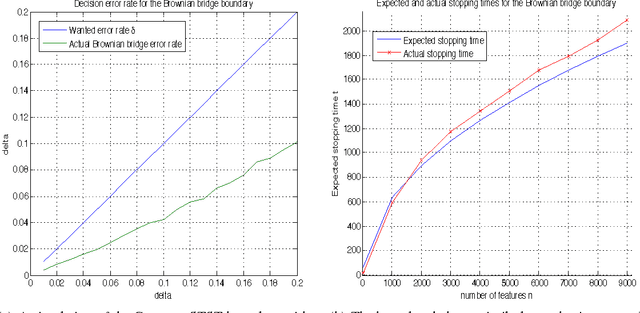
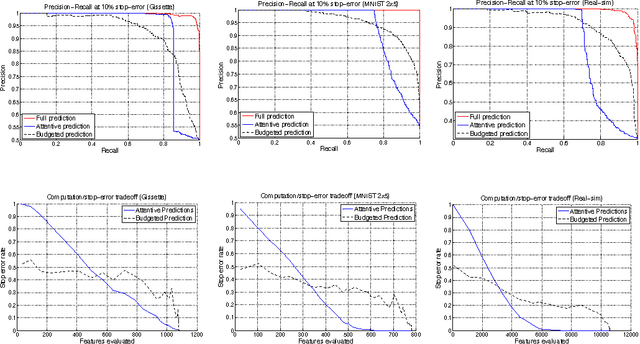
We present a method to stop the evaluation of a prediction process when the result of the full evaluation is obvious. This trait is highly desirable in prediction tasks where a predictor evaluates all its features for every example in large datasets. We observe that some examples are easier to classify than others, a phenomenon which is characterized by the event when most of the features agree on the class of an example. By stopping the feature evaluation when encountering an easy- to-classify example, the predictor can achieve substantial gains in computation. Our method provides a natural attention mechanism for linear predictors where the predictor concentrates most of its computation on hard-to-classify examples and quickly discards easy-to-classify ones. By modifying a linear prediction algorithm such as an SVM or AdaBoost to include our attentive method we prove that the average number of features computed is O(sqrt(n log 1/sqrt(delta))) where n is the original number of features, and delta is the error rate incurred due to early stopping. We demonstrate the effectiveness of Attentive Prediction on MNIST, Real-sim, Gisette, and synthetic datasets.
Rapid Learning with Stochastic Focus of Attention
May 02, 2011
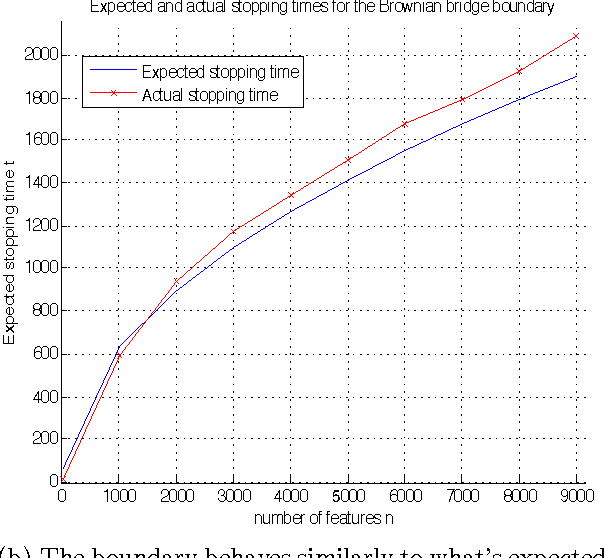
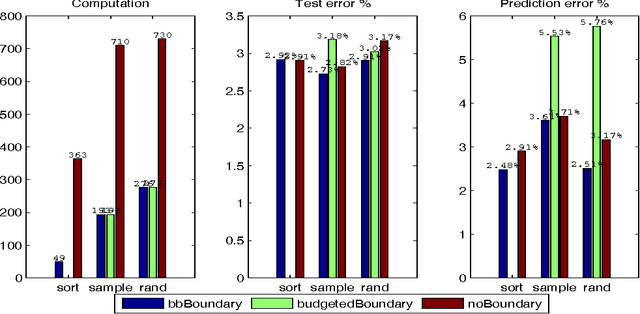
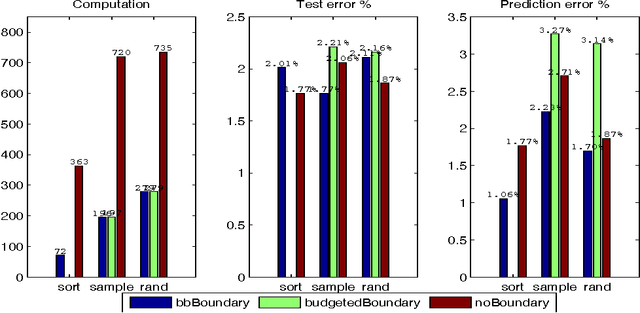
We present a method to stop the evaluation of a decision making process when the result of the full evaluation is obvious. This trait is highly desirable for online margin-based machine learning algorithms where a classifier traditionally evaluates all the features for every example. We observe that some examples are easier to classify than others, a phenomenon which is characterized by the event when most of the features agree on the class of an example. By stopping the feature evaluation when encountering an easy to classify example, the learning algorithm can achieve substantial gains in computation. Our method provides a natural attention mechanism for learning algorithms. By modifying Pegasos, a margin-based online learning algorithm, to include our attentive method we lower the number of attributes computed from $n$ to an average of $O(\sqrt{n})$ features without loss in prediction accuracy. We demonstrate the effectiveness of Attentive Pegasos on MNIST data.
The Attentive Perceptron
Sep 29, 2010We propose a focus of attention mechanism to speed up the Perceptron algorithm. Focus of attention speeds up the Perceptron algorithm by lowering the number of features evaluated throughout training and prediction. Whereas the traditional Perceptron evaluates all the features of each example, the Attentive Perceptron evaluates less features for easy to classify examples, thereby achieving significant speedups and small losses in prediction accuracy. Focus of attention allows the Attentive Perceptron to stop the evaluation of features at any interim point and filter the example. This creates an attentive filter which concentrates computation at examples that are hard to classify, and quickly filters examples that are easy to classify.