 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFocus of Attention for Linear Predictors
Dec 29, 2012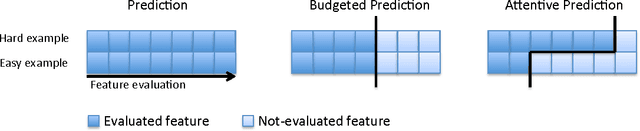
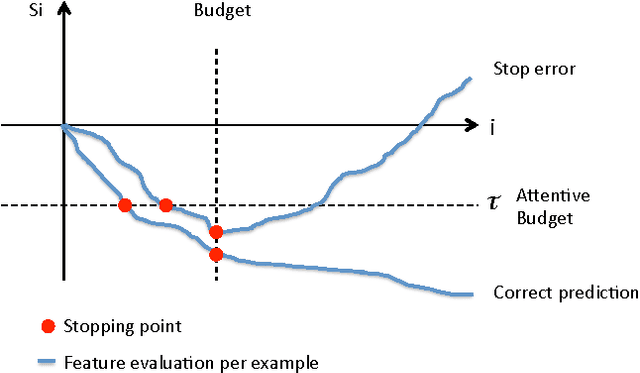
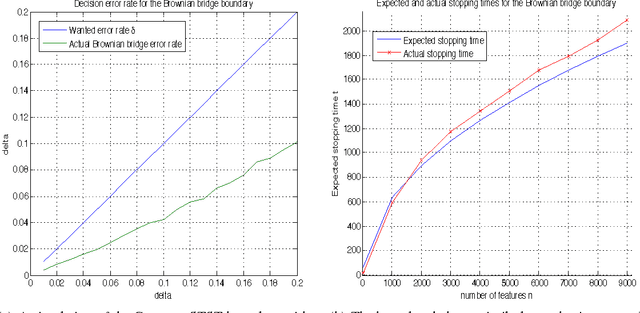
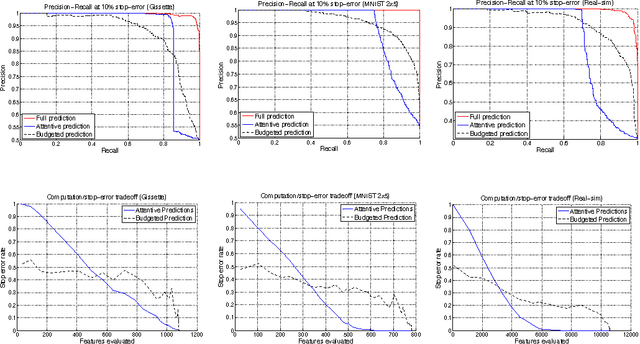
We present a method to stop the evaluation of a prediction process when the result of the full evaluation is obvious. This trait is highly desirable in prediction tasks where a predictor evaluates all its features for every example in large datasets. We observe that some examples are easier to classify than others, a phenomenon which is characterized by the event when most of the features agree on the class of an example. By stopping the feature evaluation when encountering an easy- to-classify example, the predictor can achieve substantial gains in computation. Our method provides a natural attention mechanism for linear predictors where the predictor concentrates most of its computation on hard-to-classify examples and quickly discards easy-to-classify ones. By modifying a linear prediction algorithm such as an SVM or AdaBoost to include our attentive method we prove that the average number of features computed is O(sqrt(n log 1/sqrt(delta))) where n is the original number of features, and delta is the error rate incurred due to early stopping. We demonstrate the effectiveness of Attentive Prediction on MNIST, Real-sim, Gisette, and synthetic datasets.
Rapid Learning with Stochastic Focus of Attention
May 02, 2011
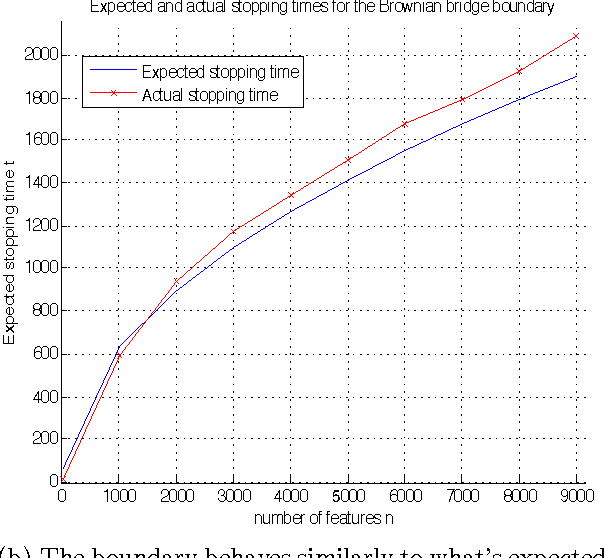
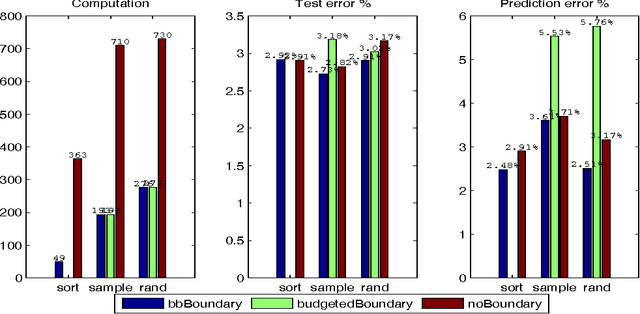
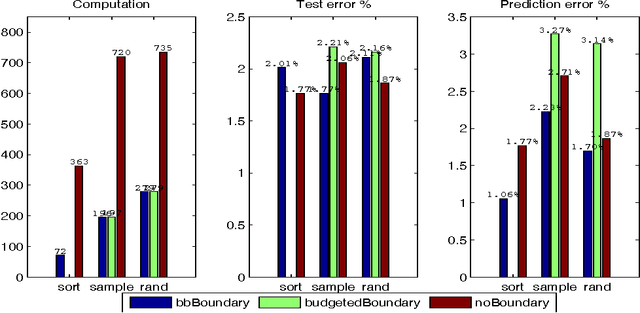
We present a method to stop the evaluation of a decision making process when the result of the full evaluation is obvious. This trait is highly desirable for online margin-based machine learning algorithms where a classifier traditionally evaluates all the features for every example. We observe that some examples are easier to classify than others, a phenomenon which is characterized by the event when most of the features agree on the class of an example. By stopping the feature evaluation when encountering an easy to classify example, the learning algorithm can achieve substantial gains in computation. Our method provides a natural attention mechanism for learning algorithms. By modifying Pegasos, a margin-based online learning algorithm, to include our attentive method we lower the number of attributes computed from $n$ to an average of $O(\sqrt{n})$ features without loss in prediction accuracy. We demonstrate the effectiveness of Attentive Pegasos on MNIST data.
The Attentive Perceptron
Sep 29, 2010We propose a focus of attention mechanism to speed up the Perceptron algorithm. Focus of attention speeds up the Perceptron algorithm by lowering the number of features evaluated throughout training and prediction. Whereas the traditional Perceptron evaluates all the features of each example, the Attentive Perceptron evaluates less features for easy to classify examples, thereby achieving significant speedups and small losses in prediction accuracy. Focus of attention allows the Attentive Perceptron to stop the evaluation of features at any interim point and filter the example. This creates an attentive filter which concentrates computation at examples that are hard to classify, and quickly filters examples that are easy to classify.
Online Coordinate Boosting
Oct 24, 2008


We present a new online boosting algorithm for adapting the weights of a boosted classifier, which yields a closer approximation to Freund and Schapire's AdaBoost algorithm than previous online boosting algorithms. We also contribute a new way of deriving the online algorithm that ties together previous online boosting work. We assume that the weak hypotheses were selected beforehand, and only their weights are updated during online boosting. The update rule is derived by minimizing AdaBoost's loss when viewed in an incremental form. The equations show that optimization is computationally expensive. However, a fast online approximation is possible. We compare approximation error to batch AdaBoost on synthetic datasets and generalization error on face datasets and the MNIST dataset.