 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Code Switching Language Models for Automatic Speech Recognition
Jun 16, 2020
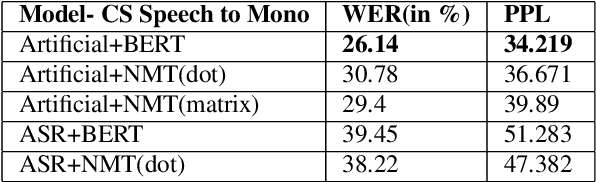

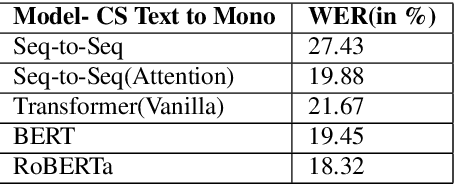
In this paper, we particularly work on the code-switched text, one of the most common occurrences in the bilingual communities across the world. Due to the discrepancies in the extraction of code-switched text from an Automated Speech Recognition(ASR) module, and thereby extracting the monolingual text from the code-switched text, we propose an approach for extracting monolingual text using Deep Bi-directional Language Models(LM) such as BERT and other Machine Translation models, and also explore different ways of extracting code-switched text from the ASR model. We also explain the robustness of the model by comparing the results of Perplexity and other different metrics like WER, to the standard bi-lingual text output without any external information.