 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Fair Evaluation of Dialogue State Tracking by Flexible Incorporation of Turn-level Performances
Paper and Code
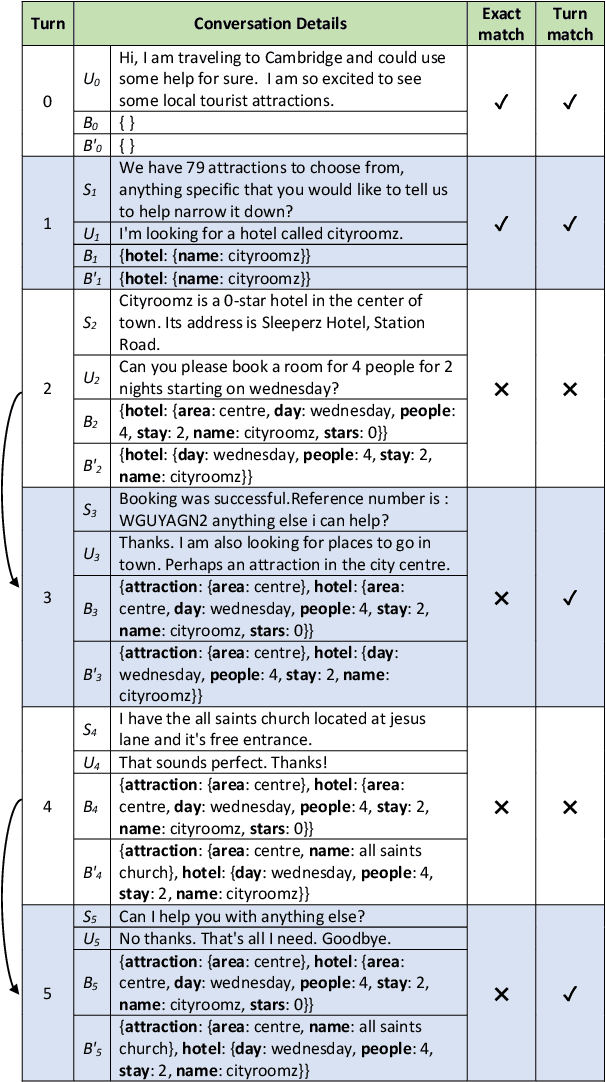

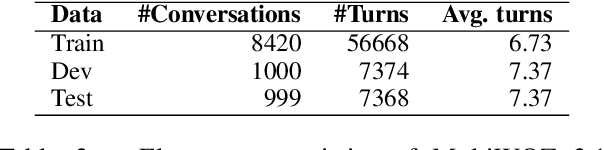

Dialogue State Tracking (DST) is primarily evaluated using Joint Goal Accuracy (JGA) defined as the fraction of turns where the ground-truth dialogue state exactly matches the prediction. Generally in DST, the dialogue state or belief state for a given turn contains all the intents shown by the user till that turn. Due to this cumulative nature of the belief state, it is difficult to get a correct prediction once a misprediction has occurred. Thus, although being a useful metric, it can be harsh at times and underestimate the true potential of a DST model. Moreover, an improvement in JGA can sometimes decrease the performance of turn-level or non-cumulative belief state prediction due to inconsistency in annotations. So, using JGA as the only metric for model selection may not be ideal for all scenarios. In this work, we discuss various evaluation metrics used for DST along with their shortcomings. To address the existing issues, we propose a new evaluation metric named Flexible Goal Accuracy (FGA). FGA is a generalized version of JGA. But unlike JGA, it tries to give penalized rewards to mispredictions that are locally correct i.e. the root cause of the error is an earlier turn. By doing so, FGA considers the performance of both cumulative and turn-level prediction flexibly and provides a better insight than the existing metrics. We also show that FGA is a better discriminator of DST model performance.