 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Fine-Grained Complexity View on Propositional Abduction -- Algorithms and Lower Bounds
May 15, 2025The Boolean satisfiability problem (SAT) is a well-known example of monotonic reasoning, of intense practical interest due to fast solvers, complemented by rigorous fine-grained complexity results. However, for non-monotonic reasoning, e.g., abductive reasoning, comparably little is known outside classic complexity theory. In this paper we take a first step of bridging the gap between monotonic and non-monotonic reasoning by analyzing the complexity of intractable abduction problems under the seemingly overlooked but natural parameter n: the number of variables in the knowledge base. We obtain several positive results for $\Sigma^P_2$- as well as NP- and coNP-complete fragments, which implies the first example of beating exhaustive search for a $\Sigma^P_2$-complete problem (to the best of our knowledge). We complement this with lower bounds and for many fragments rule out improvements under the (strong) exponential-time hypothesis.
HOLa: HoloLens Object Labeling
Dec 06, 2024In the context of medical Augmented Reality (AR) applications, object tracking is a key challenge and requires a significant amount of annotation masks. As segmentation foundation models like the Segment Anything Model (SAM) begin to emerge, zero-shot segmentation requires only minimal human participation obtaining high-quality object masks. We introduce a HoloLens-Object-Labeling (HOLa) Unity and Python application based on the SAM-Track algorithm that offers fully automatic single object annotation for HoloLens 2 while requiring minimal human participation. HOLa does not have to be adjusted to a specific image appearance and could thus alleviate AR research in any application field. We evaluate HOLa for different degrees of image complexity in open liver surgery and in medical phantom experiments. Using HOLa for image annotation can increase the labeling speed by more than 500 times while providing Dice scores between 0.875 and 0.982, which are comparable to human annotators. Our code is publicly available at: https://github.com/mschwimmbeck/HOLa
Learning Tree Pattern Transformations
Oct 10, 2024
Explaining why and how a tree $t$ structurally differs from another tree $t^*$ is a question that is encountered throughout computer science, including in understanding tree-structured data such as XML or JSON data. In this article, we explore how to learn explanations for structural differences between pairs of trees from sample data: suppose we are given a set $\{(t_1, t_1^*),\dots, (t_n, t_n^*)\}$ of pairs of labelled, ordered trees; is there a small set of rules that explains the structural differences between all pairs $(t_i, t_i^*)$? This raises two research questions: (i) what is a good notion of "rule" in this context?; and (ii) how can sets of rules explaining a data set be learnt algorithmically? We explore these questions from the perspective of database theory by (1) introducing a pattern-based specification language for tree transformations; (2) exploring the computational complexity of variants of the above algorithmic problem, e.g. showing NP-hardness for very restricted variants; and (3) discussing how to solve the problem for data from CS education research using SAT solvers.
Computational Performance of Deep Reinforcement Learning to find Nash Equilibria
Apr 26, 2021
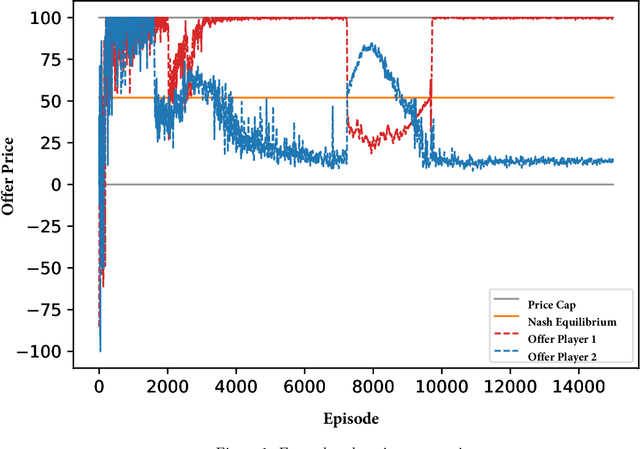
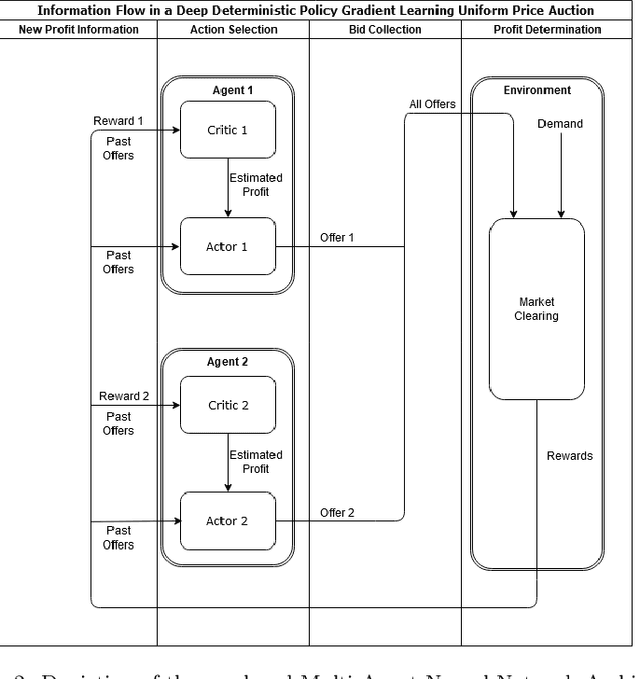
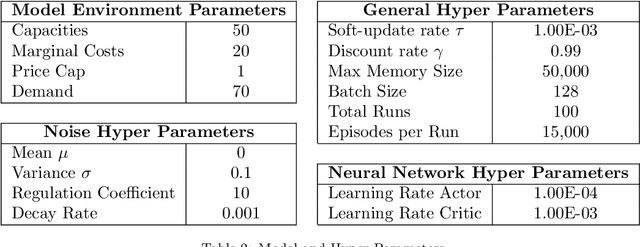
We test the performance of deep deterministic policy gradient (DDPG), a deep reinforcement learning algorithm, able to handle continuous state and action spaces, to learn Nash equilibria in a setting where firms compete in prices. These algorithms are typically considered model-free because they do not require transition probability functions (as in e.g., Markov games) or predefined functional forms. Despite being model-free, a large set of parameters are utilized in various steps of the algorithm. These are e.g., learning rates, memory buffers, state-space dimensioning, normalizations, or noise decay rates and the purpose of this work is to systematically test the effect of these parameter configurations on convergence to the analytically derived Bertrand equilibrium. We find parameter choices that can reach convergence rates of up to 99%. The reliable convergence may make the method a useful tool to study strategic behavior of firms even in more complex settings. Keywords: Bertrand Equilibrium, Competition in Uniform Price Auctions, Deep Deterministic Policy Gradient Algorithm, Parameter Sensitivity Analysis
Parameterized Complexity of Logic-Based Argumentation in Schaefer's Framework
Feb 23, 2021
Logic-based argumentation is a well-established formalism modelling nonmonotonic reasoning. It has been playing a major role in AI for decades, now. Informally, a set of formulas is the support for a given claim if it is consistent, subset-minimal, and implies the claim. In such a case, the pair of the support and the claim together is called an argument. In this paper, we study the propositional variants of the following three computational tasks studied in argumentation: ARG (exists a support for a given claim with respect to a given set of formulas), ARG-Check (is a given set a support for a given claim), and ARG-Rel (similarly as ARG plus requiring an additionally given formula to be contained in the support). ARG-Check is complete for the complexity class DP, and the other two problems are known to be complete for the second level of the polynomial hierarchy (Parson et al., J. Log. Comput., 2003) and, accordingly, are highly intractable. Analyzing the reason for this intractability, we perform a two-dimensional classification: first, we consider all possible propositional fragments of the problem within Schaefer's framework (STOC 1978), and then study different parameterizations for each of the fragment. We identify a list of reasonable structural parameters (size of the claim, support, knowledge-base) that are connected to the aforementioned decision problems. Eventually, we thoroughly draw a fine border of parameterized intractability for each of the problems showing where the problems are fixed-parameter tractable and when this exactly stops. Surprisingly, several cases are of very high intractability (paraNP and beyond).
Machine learning models show similar performance to Renewables.ninja for generation of long-term wind power time series even without location information
Dec 09, 2019
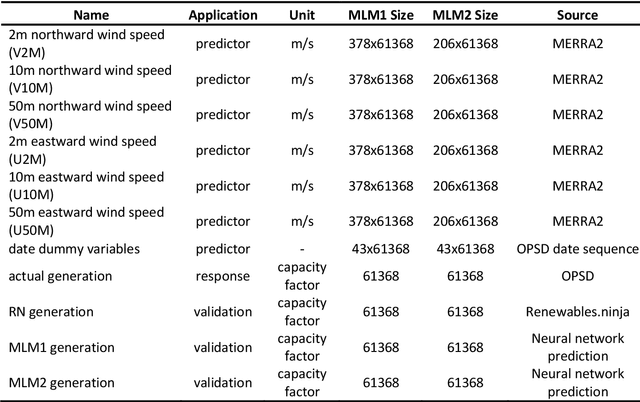

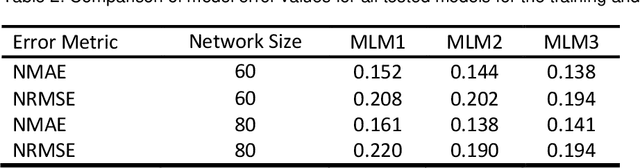
Driven by climatic processes, wind power generation is inherently variable. Long-term simulated wind power time series are therefore an essential component for understanding the temporal availability of wind power and its integration into future renewable energy systems. In the recent past, mainly power curve based models such as Renewables.ninja (RN) have been used for deriving synthetic time series for wind power generation despite their need for accurate location information as well as for bias correction, and their insufficient replication of extreme events and short-term power ramps. We assess how time series generated by machine learning models (MLM) compare to RN in terms of their ability to replicate the characteristics of observed nationally aggregated wind power generation for Germany. Hence, we apply neural networks to one MERRA2 reanalysis wind speed input dataset with no location information and one with basic location information. The resulting time series and the RN time series are compared with actual generation. Both MLM time series feature equal or even better time series quality than RN depending on the characteristics considered. We conclude that MLM models can, even when reducing information on turbine locations and turbine types, produce time series of at least equal quality to RN.
On the Parameterized Complexity of Default Logic and Autoepistemic Logic
Oct 06, 2011
We investigate the application of Courcelle's Theorem and the logspace version of Elberfeld etal. in the context of the implication problem for propositional sets of formulae, the extension existence problem for default logic, as well as the expansion existence problem for autoepistemic logic and obtain fixed-parameter time and space efficient algorithms for these problems. On the other hand, we exhibit, for each of the above problems, families of instances of a very simple structure that, for a wide range of different parameterizations, do not have efficient fixed-parameter algorithms (even in the sense of the large class XPnu), unless P=NP.
Complexity of Propositional Abduction for Restricted Sets of Boolean Functions
Jun 28, 2010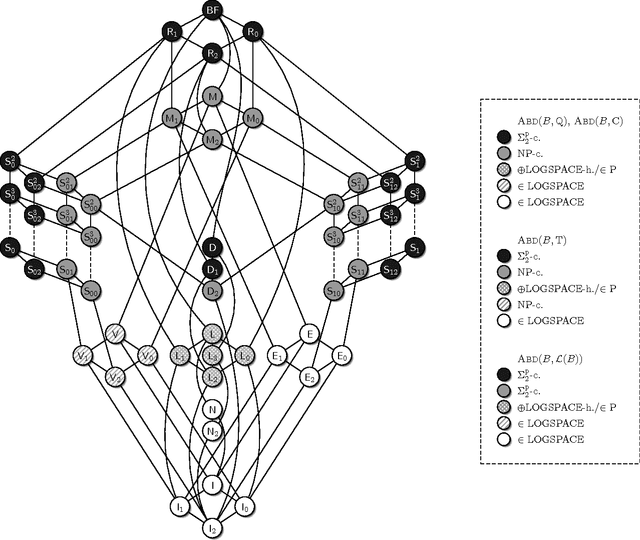

Abduction is a fundamental and important form of non-monotonic reasoning. Given a knowledge base explaining how the world behaves it aims at finding an explanation for some observed manifestation. In this paper we focus on propositional abduction, where the knowledge base and the manifestation are represented by propositional formulae. The problem of deciding whether there exists an explanation has been shown to be SigmaP2-complete in general. We consider variants obtained by restricting the allowed connectives in the formulae to certain sets of Boolean functions. We give a complete classification of the complexity for all considerable sets of Boolean functions. In this way, we identify easier cases, namely NP-complete and polynomial cases; and we highlight sources of intractability. Further, we address the problem of counting the explanations and draw a complete picture for the counting complexity.