 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputational Performance of Deep Reinforcement Learning to find Nash Equilibria
Apr 26, 2021
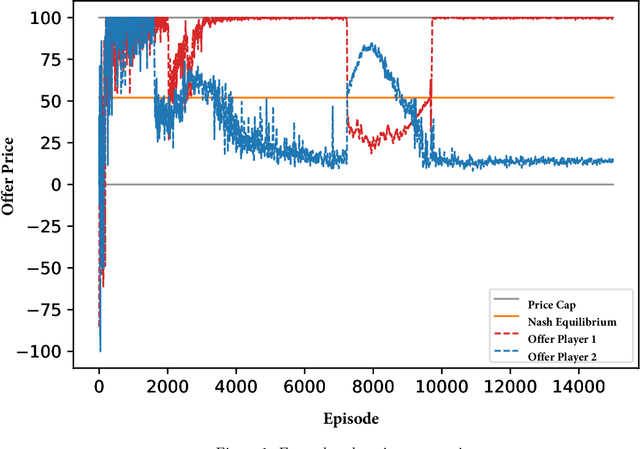
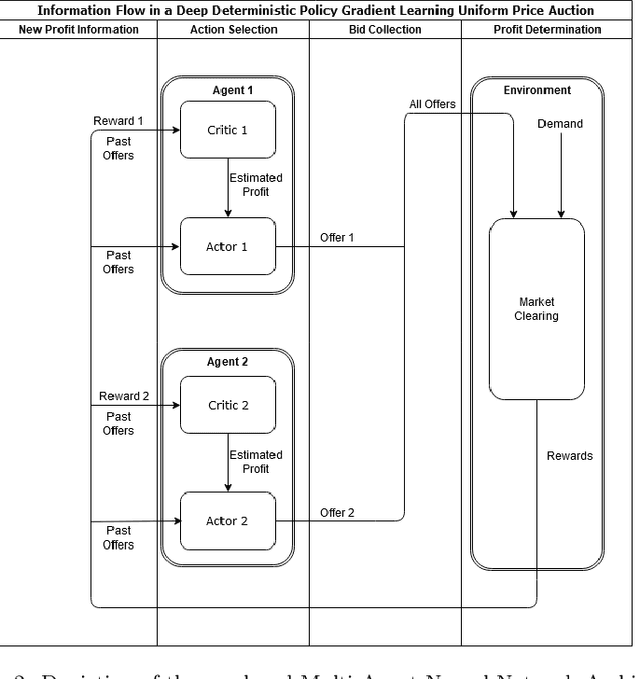
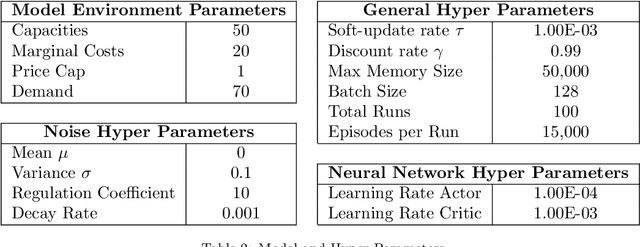
We test the performance of deep deterministic policy gradient (DDPG), a deep reinforcement learning algorithm, able to handle continuous state and action spaces, to learn Nash equilibria in a setting where firms compete in prices. These algorithms are typically considered model-free because they do not require transition probability functions (as in e.g., Markov games) or predefined functional forms. Despite being model-free, a large set of parameters are utilized in various steps of the algorithm. These are e.g., learning rates, memory buffers, state-space dimensioning, normalizations, or noise decay rates and the purpose of this work is to systematically test the effect of these parameter configurations on convergence to the analytically derived Bertrand equilibrium. We find parameter choices that can reach convergence rates of up to 99%. The reliable convergence may make the method a useful tool to study strategic behavior of firms even in more complex settings. Keywords: Bertrand Equilibrium, Competition in Uniform Price Auctions, Deep Deterministic Policy Gradient Algorithm, Parameter Sensitivity Analysis