 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-supervised Time Domain Target Speaker Extraction with Attention
Jun 18, 2022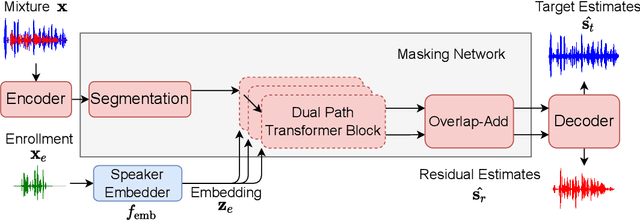

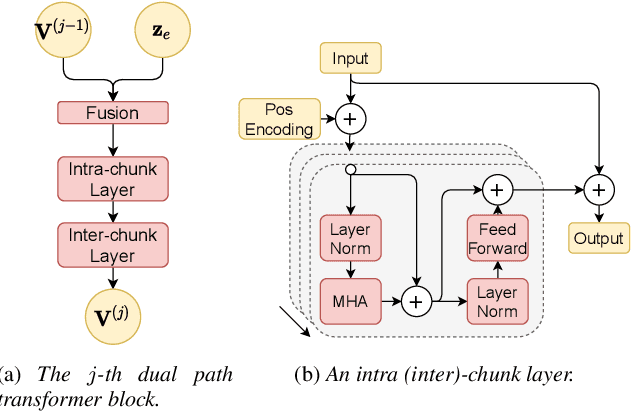
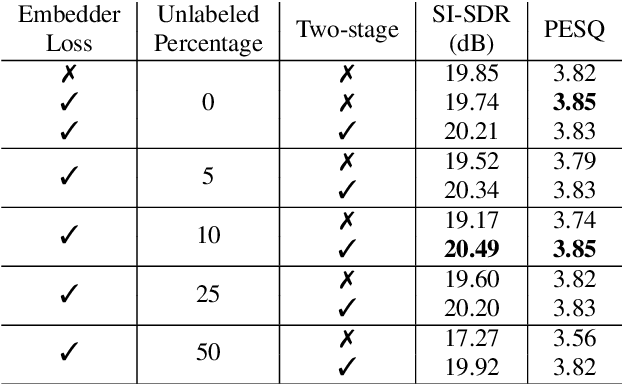
In this work, we propose Exformer, a time-domain architecture for target speaker extraction. It consists of a pre-trained speaker embedder network and a separator network based on transformer encoder blocks. We study multiple methods to combine speaker information with the input mixture, and the resulting Exformer architecture obtains superior extraction performance compared to prior time-domain networks. Furthermore, we investigate a two-stage procedure to train the model using mixtures without reference signals upon a pre-trained supervised model. Experimental results show that the proposed semi-supervised learning procedure improves the performance of the supervised baselines.
To Dereverb Or Not to Dereverb? Perceptual Studies On Real-Time Dereverberation Targets
Jun 16, 2022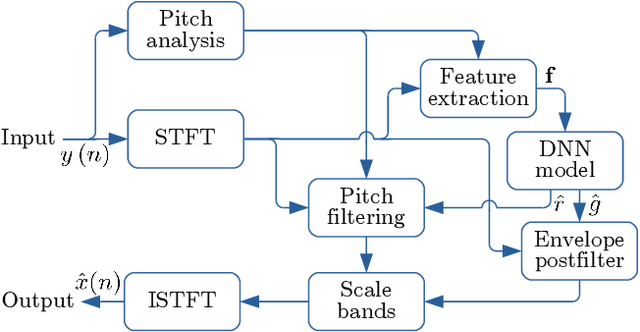


In real life, room effect, also known as room reverberation, and the present background noise degrade the quality of speech. Recently, deep learning-based speech enhancement approaches have shown a lot of promise and surpassed traditional denoising and dereverberation methods. It is also well established that these state-of-the-art denoising algorithms significantly improve the quality of speech as perceived by human listeners. But the role of dereverberation on subjective (perceived) speech quality, and whether the additional artifacts introduced by dereverberation cause more harm than good are still unclear. In this paper, we attempt to answer these questions by evaluating a state of the art speech enhancement system in a comprehensive subjective evaluation study for different choices of dereverberation targets.
Personalized PercepNet: Real-time, Low-complexity Target Voice Separation and Enhancement
Jun 08, 2021
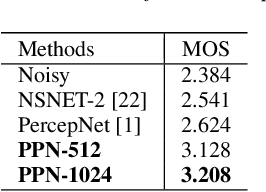
The presence of multiple talkers in the surrounding environment poses a difficult challenge for real-time speech communication systems considering the constraints on network size and complexity. In this paper, we present Personalized PercepNet, a real-time speech enhancement model that separates a target speaker from a noisy multi-talker mixture without compromising on complexity of the recently proposed PercepNet. To enable speaker-dependent speech enhancement, we first show how we can train a perceptually motivated speaker embedder network to produce a representative embedding vector for the given speaker. Personalized PercepNet uses the target speaker embedding as additional information to pick out and enhance only the target speaker while suppressing all other competing sounds. Our experiments show that the proposed model significantly outperforms PercepNet and other baselines, both in terms of objective speech enhancement metrics and human opinion scores.
Efficient Trainable Front-Ends for Neural Speech Enhancement
Feb 20, 2020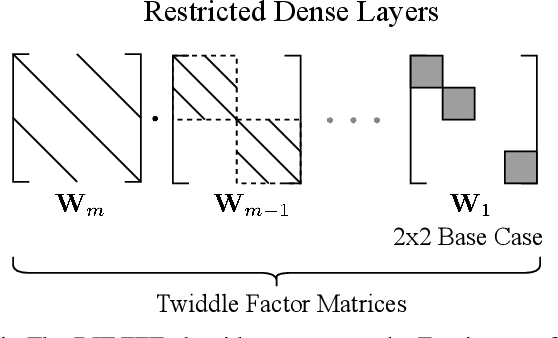
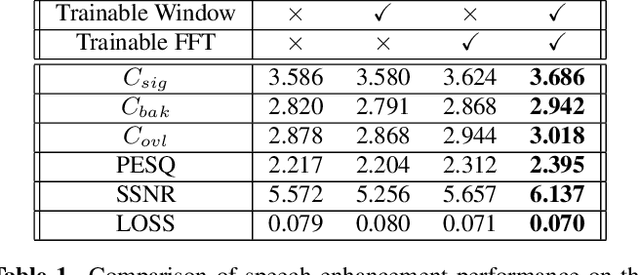
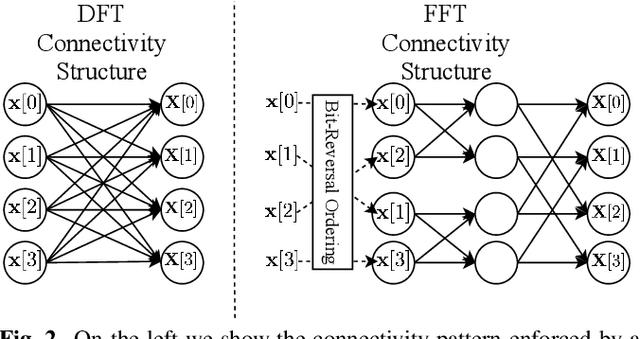
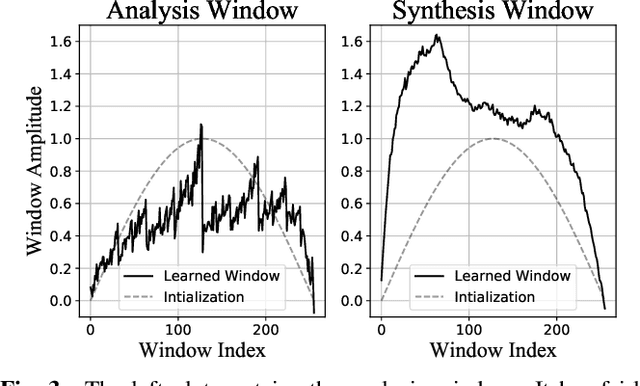
Many neural speech enhancement and source separation systems operate in the time-frequency domain. Such models often benefit from making their Short-Time Fourier Transform (STFT) front-ends trainable. In current literature, these are implemented as large Discrete Fourier Transform matrices; which are prohibitively inefficient for low-compute systems. We present an efficient, trainable front-end based on the butterfly mechanism to compute the Fast Fourier Transform, and show its accuracy and efficiency benefits for low-compute neural speech enhancement models. We also explore the effects of making the STFT window trainable.
Two-Step Sound Source Separation: Training on Learned Latent Targets
Oct 23, 2019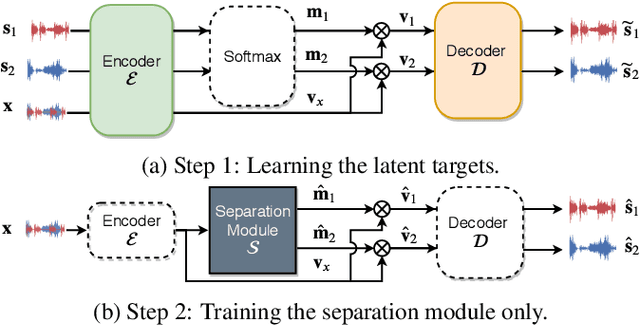
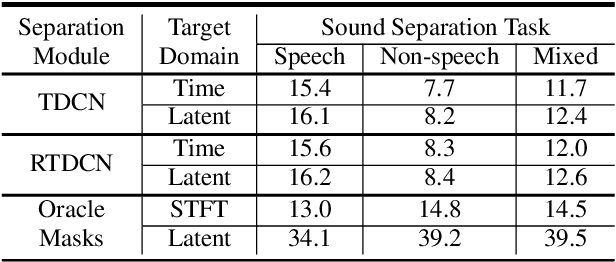
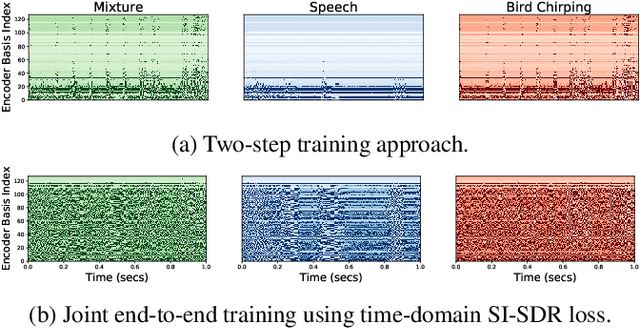
In this paper, we propose a two-step training procedure for source separation via a deep neural network. In the first step we learn a transform (and it's inverse) to a latent space where masking-based separation performance using oracles is optimal. For the second step, we train a separation module that operates on the previously learned space. In order to do so, we also make use of a scale-invariant signal to distortion ratio (SI-SDR) loss function that works in the latent space, and we prove that it lower-bounds the SI-SDR in the time domain. We run various sound separation experiments that show how this approach can obtain better performance as compared to systems that learn the transform and the separation module jointly. The proposed methodology is general enough to be applicable to a large class of neural network end-to-end separation systems.
Class-conditional embeddings for music source separation
Nov 07, 2018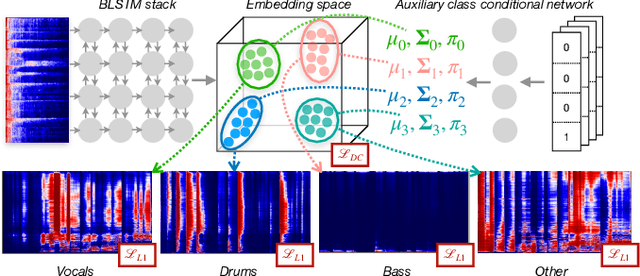
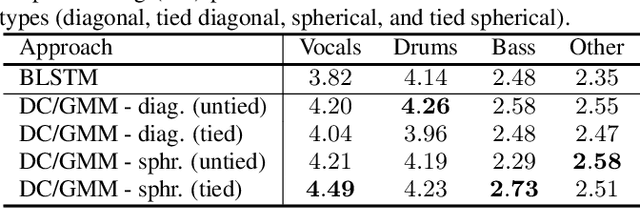
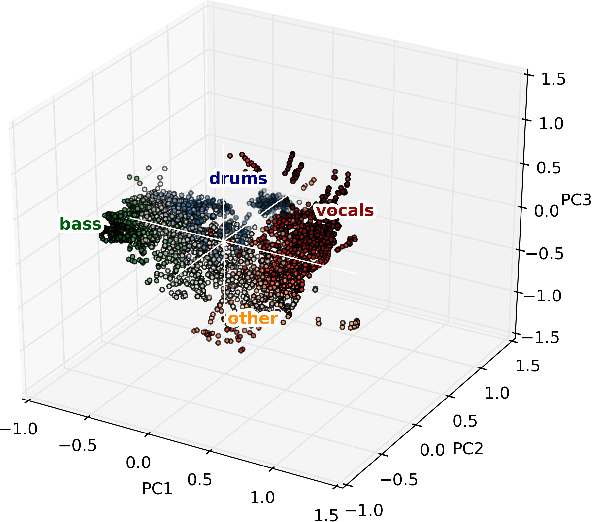
Isolating individual instruments in a musical mixture has a myriad of potential applications, and seems imminently achievable given the levels of performance reached by recent deep learning methods. While most musical source separation techniques learn an independent model for each instrument, we propose using a common embedding space for the time-frequency bins of all instruments in a mixture inspired by deep clustering and deep attractor networks. Additionally, an auxiliary network is used to generate parameters of a Gaussian mixture model (GMM) where the posterior distribution over GMM components in the embedding space can be used to create a mask that separates individual sources from a mixture. In addition to outperforming a mask-inference baseline on the MUSDB-18 dataset, our embedding space is easily interpretable and can be used for query-based separation.
Unsupervised Deep Clustering for Source Separation: Direct Learning from Mixtures using Spatial Information
Nov 05, 2018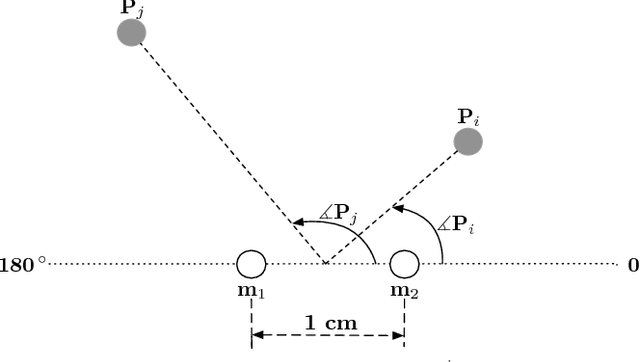
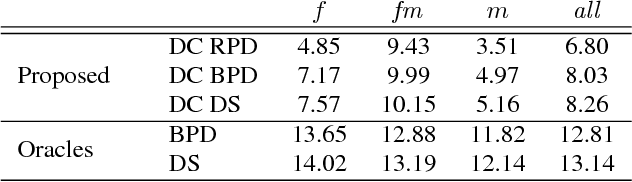
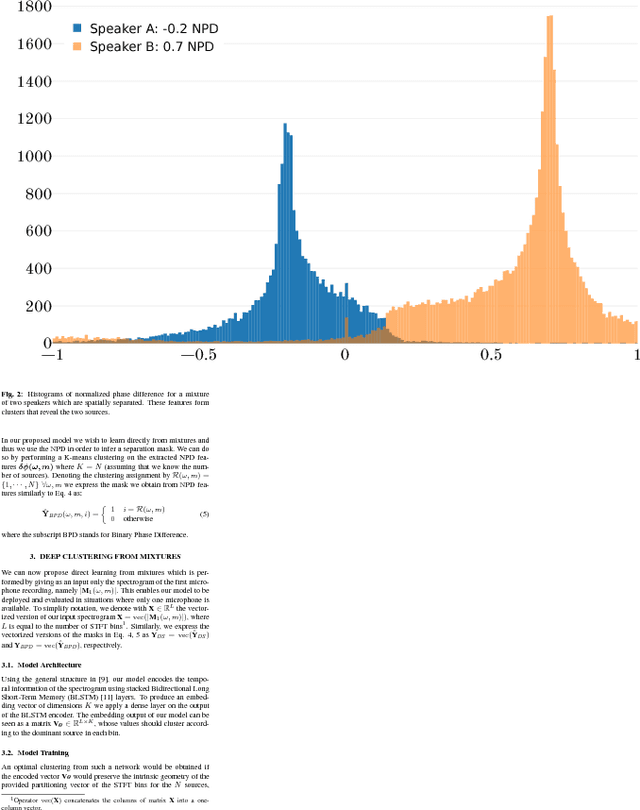
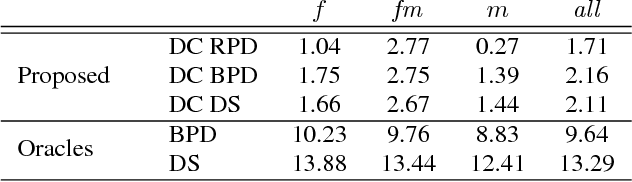
We present a monophonic source separation system that is trained by only observing mixtures with no ground truth separation information. We use a deep clustering approach which trains on multi-channel mixtures and learns to project spectrogram bins to source clusters that correlate with various spatial features. We show that using such a training process we can obtain separation performance that is as good as making use of ground truth separation information. Once trained, this system is capable of performing sound separation on monophonic inputs, despite having learned how to do so using multi-channel recordings.