Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Deep Clustering for Source Separation: Direct Learning from Mixtures using Spatial Information
Paper and Code
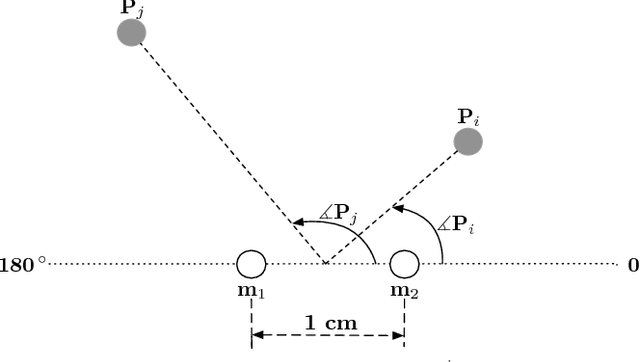
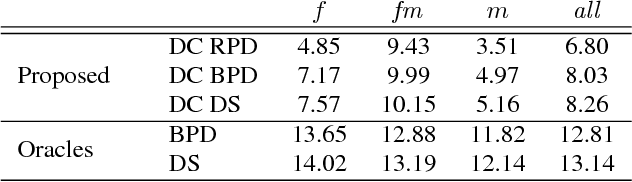
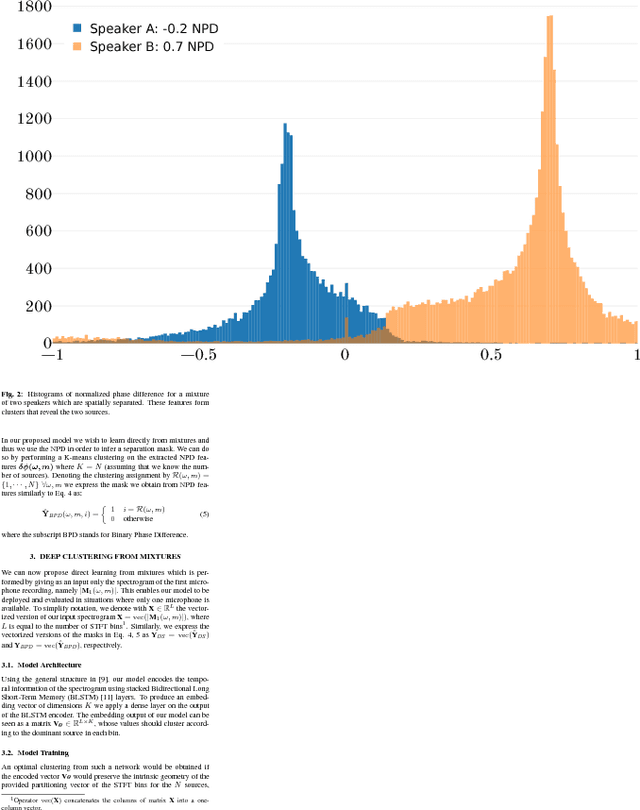
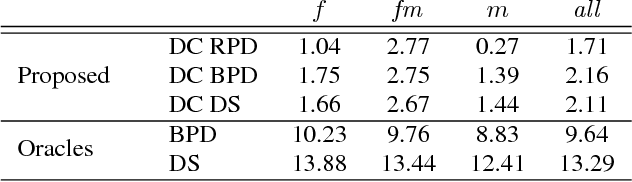
We present a monophonic source separation system that is trained by only observing mixtures with no ground truth separation information. We use a deep clustering approach which trains on multi-channel mixtures and learns to project spectrogram bins to source clusters that correlate with various spatial features. We show that using such a training process we can obtain separation performance that is as good as making use of ground truth separation information. Once trained, this system is capable of performing sound separation on monophonic inputs, despite having learned how to do so using multi-channel recordings.
* Submitted to ICASSP 2019
View paper on