Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-supervised Time Domain Target Speaker Extraction with Attention
Paper and Code
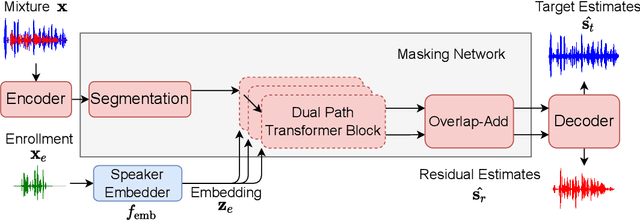

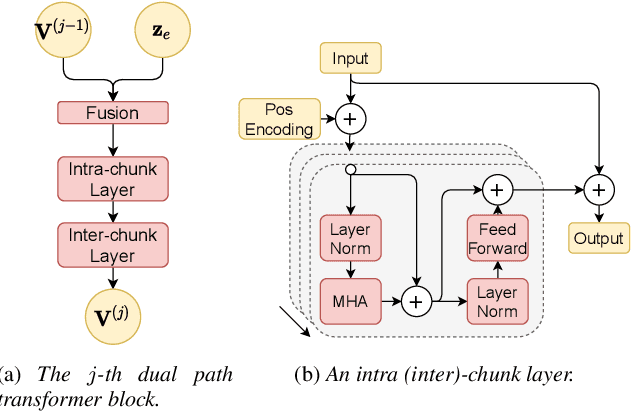
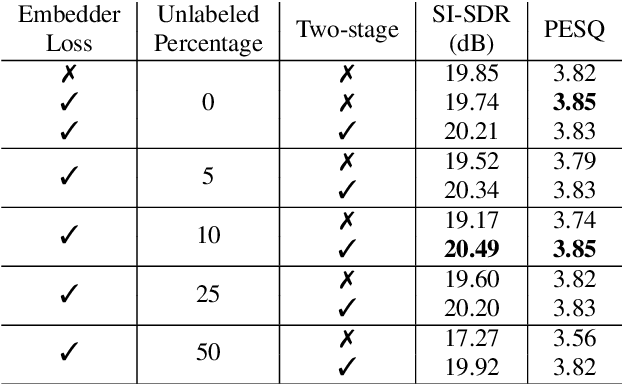
In this work, we propose Exformer, a time-domain architecture for target speaker extraction. It consists of a pre-trained speaker embedder network and a separator network based on transformer encoder blocks. We study multiple methods to combine speaker information with the input mixture, and the resulting Exformer architecture obtains superior extraction performance compared to prior time-domain networks. Furthermore, we investigate a two-stage procedure to train the model using mixtures without reference signals upon a pre-trained supervised model. Experimental results show that the proposed semi-supervised learning procedure improves the performance of the supervised baselines.
View paper on