Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Trainable Front-Ends for Neural Speech Enhancement
Paper and Code
Feb 20, 2020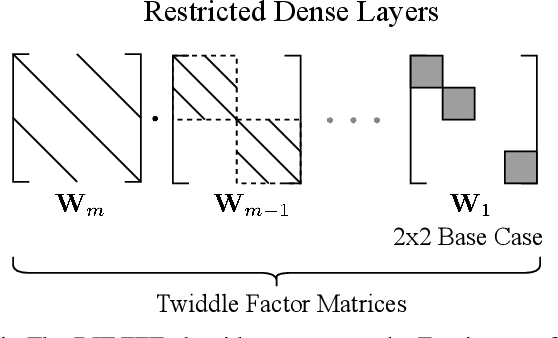
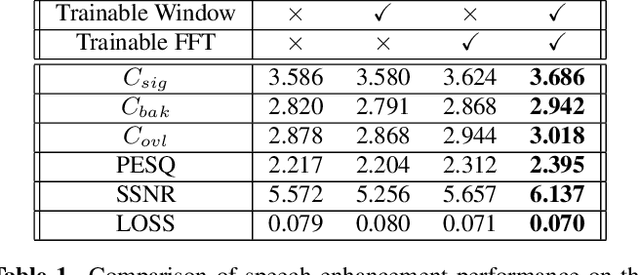
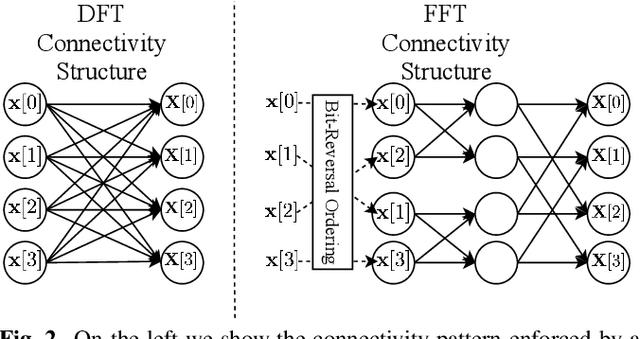
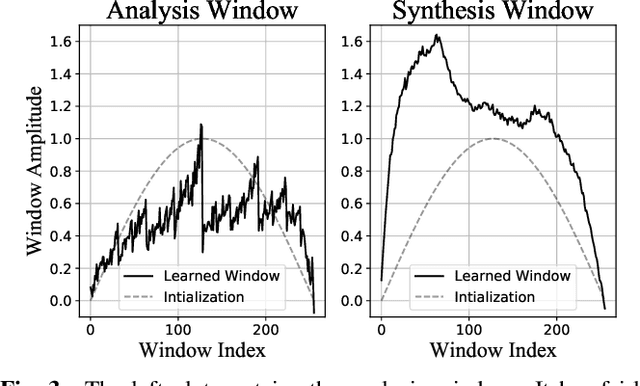
Many neural speech enhancement and source separation systems operate in the time-frequency domain. Such models often benefit from making their Short-Time Fourier Transform (STFT) front-ends trainable. In current literature, these are implemented as large Discrete Fourier Transform matrices; which are prohibitively inefficient for low-compute systems. We present an efficient, trainable front-end based on the butterfly mechanism to compute the Fast Fourier Transform, and show its accuracy and efficiency benefits for low-compute neural speech enhancement models. We also explore the effects of making the STFT window trainable.
* 5 pages, 5 figures, ICASSP 2020
View paper on