 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Class Separability Pitfalls In Audio-Text Contrastive Zero-Shot Learning
Paper and Code

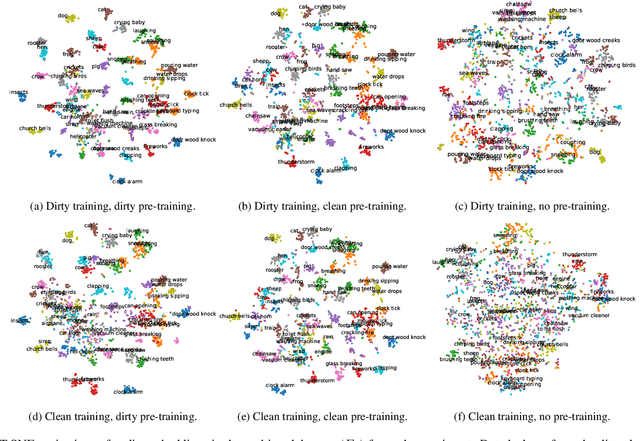


Recent advances in audio-text cross-modal contrastive learning have shown its potential towards zero-shot learning. One possibility for this is by projecting item embeddings from pre-trained backbone neural networks into a cross-modal space in which item similarity can be calculated in either domain. This process relies on a strong unimodal pre-training of the backbone networks, and on a data-intensive training task for the projectors. These two processes can be biased by unintentional data leakage, which can arise from using supervised learning in pre-training or from inadvertently training the cross-modal projection using labels from the zero-shot learning evaluation. In this study, we show that a significant part of the measured zero-shot learning accuracy is due to strengths inherited from the audio and text backbones, that is, they are not learned in the cross-modal domain and are not transferred from one modality to another.