 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentify Speakers in Cocktail Parties with End-to-End Attention
Paper and Code
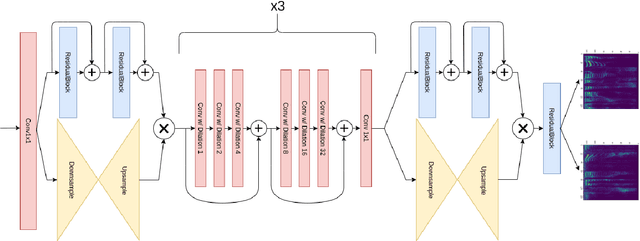
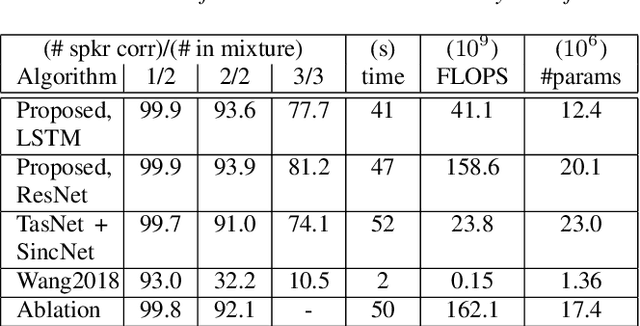
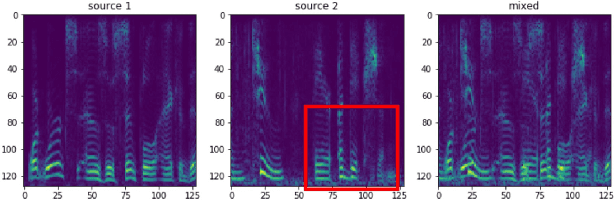
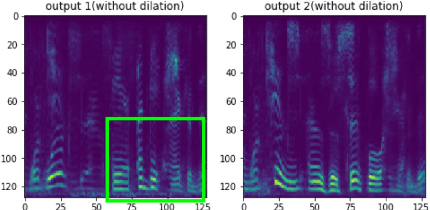
In scenarios where multiple speakers talk at the same time, it is important to be able to identify the talkers accurately. This paper presents an end-to-end system that integrates speech source extraction and speaker identification, and proposes a new way to jointly optimize these two parts by max-pooling the speaker predictions along the channel dimension. Residual attention permits us to learn spectrogram masks that are optimized for the purpose of speaker identification, while residual forward connections permit dilated convolution with a sufficiently large context window to guarantee correct streaming across syllable boundaries. End-to-end training results in a system that recognizes one speaker in a two-speaker broadcast speech mixture with 99.9% accuracy and both speakers with 93.9% accuracy, and that recognizes all speakers in three-speaker scenarios with 81.2% accuracy.