 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCooperative Reward Shaping for Multi-Agent Pathfinding
Jul 15, 2024The primary objective of Multi-Agent Pathfinding (MAPF) is to plan efficient and conflict-free paths for all agents. Traditional multi-agent path planning algorithms struggle to achieve efficient distributed path planning for multiple agents. In contrast, Multi-Agent Reinforcement Learning (MARL) has been demonstrated as an effective approach to achieve this objective. By modeling the MAPF problem as a MARL problem, agents can achieve efficient path planning and collision avoidance through distributed strategies under partial observation. However, MARL strategies often lack cooperation among agents due to the absence of global information, which subsequently leads to reduced MAPF efficiency. To address this challenge, this letter introduces a unique reward shaping technique based on Independent Q-Learning (IQL). The aim of this method is to evaluate the influence of one agent on its neighbors and integrate such an interaction into the reward function, leading to active cooperation among agents. This reward shaping method facilitates cooperation among agents while operating in a distributed manner. The proposed approach has been evaluated through experiments across various scenarios with different scales and agent counts. The results are compared with those from other state-of-the-art (SOTA) planners. The evidence suggests that the approach proposed in this letter parallels other planners in numerous aspects, and outperforms them in scenarios featuring a large number of agents.
Five-Tiered Route Planner for Multi-AUV Accessing Fixed Nodes in Uncertain Ocean Environments
Nov 11, 2023This article introduces a five-tiered route planner for accessing multiple nodes with multiple autonomous underwater vehicles (AUVs) that enables efficient task completion in stochastic ocean environments. First, the pre-planning tier solves the single-AUV routing problem to find the optimal giant route (GR), estimates the number of required AUVs based on GR segmentation, and allocates nodes for each AUV to access. Second, the route planning tier plans individual routes for each AUV. During navigation, the path planning tier provides each AUV with physical paths between any two points, while the actuation tier is responsible for path tracking and obstacle avoidance. Finally, in the stochastic ocean environment, deviations from the initial plan may occur, thus, an auction-based coordination tier drives online task coordination among AUVs in a distributed manner. Simulation experiments are conducted in multiple different scenarios to test the performance of the proposed planner, and the promising results show that the proposed method reduces AUV usage by 7.5% compared with the existing methods. When using the same number of AUVs, the fleet equipped with the proposed planner achieves a 6.2% improvement in average task completion rate.
Resource-Efficient Cooperative Online Scalar Field Mapping via Distributed Sparse Gaussian Process Regression
Sep 28, 2023Cooperative online scalar field mapping is an important task for multi-robot systems. Gaussian process regression is widely used to construct a map that represents spatial information with confidence intervals. However, it is difficult to handle cooperative online mapping tasks because of its high computation and communication costs. This letter proposes a resource-efficient cooperative online field mapping method via distributed sparse Gaussian process regression. A novel distributed online Gaussian process evaluation method is developed such that robots can cooperatively evaluate and find observations of sufficient global utility to reduce computation. The bounded errors of distributed aggregation results are guaranteed theoretically, and the performances of the proposed algorithms are validated by real online light field mapping experiments.
CARE: Confidence-rich Autonomous Robot Exploration using Bayesian Kernel Inference and Optimization
Sep 11, 2023



In this paper, we consider improving the efficiency of information-based autonomous robot exploration in unknown and complex environments. We first utilize Gaussian process (GP) regression to learn a surrogate model to infer the confidence-rich mutual information (CRMI) of querying control actions, then adopt an objective function consisting of predicted CRMI values and prediction uncertainties to conduct Bayesian optimization (BO), i.e., GP-based BO (GPBO). The trade-off between the best action with the highest CRMI value (exploitation) and the action with high prediction variance (exploration) can be realized. To further improve the efficiency of GPBO, we propose a novel lightweight information gain inference method based on Bayesian kernel inference and optimization (BKIO), achieving an approximate logarithmic complexity without the need for training. BKIO can also infer the CRMI and generate the best action using BO with bounded cumulative regret, which ensures its comparable accuracy to GPBO with much higher efficiency. Extensive numerical and real-world experiments show the desired efficiency of our proposed methods without losing exploration performance in different unstructured, cluttered environments. We also provide our open-source implementation code at https://github.com/Shepherd-Gregory/BKIO-Exploration.
* Full version for the paper accepted by IEEE Robotics and Automation Letters (RA-L) 2023. arXiv admin note: text overlap with arXiv:2301.00523
Physics-informed Neural Network Combined with Characteristic-Based Split for Solving Navier-Stokes Equations
Apr 21, 2023In this paper, physics-informed neural network (PINN) based on characteristic-based split (CBS) is proposed, which can be used to solve the time-dependent Navier-Stokes equations (N-S equations). In this method, The output parameters and corresponding losses are separated, so the weights between output parameters are not considered. Not all partial derivatives participate in gradient backpropagation, and the remaining terms will be reused.Therefore, compared with traditional PINN, this method is a rapid version. Here, labeled data, physical constraints and network outputs are regarded as priori information, and the residuals of the N-S equations are regarded as posteriori information. So this method can deal with both data-driven and data-free problems. As a result, it can solve the special form of compressible N-S equations -- -Shallow-Water equations, and incompressible N-S equations. As boundary conditions are known, this method only needs the flow field information at a certain time to restore the past and future flow field information. We solve the progress of a solitary wave onto a shelving beach and the dispersion of the hot water in the flow, which show this method's potential in the marine engineering. We also use incompressible equations with exact solutions to prove this method's correctness and universality. We find that PINN needs more strict boundary conditions to solve the N-S equation, because it has no computational boundary compared with the finite element method.
Bayesian Generalized Kernel Inference for Exploration of Autonomous Robots
Jan 02, 2023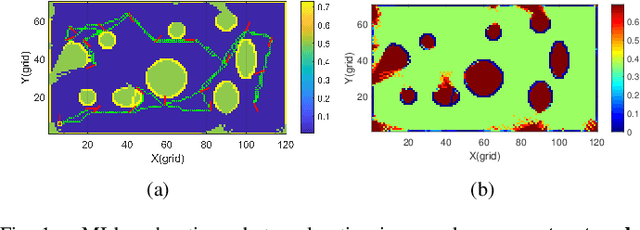
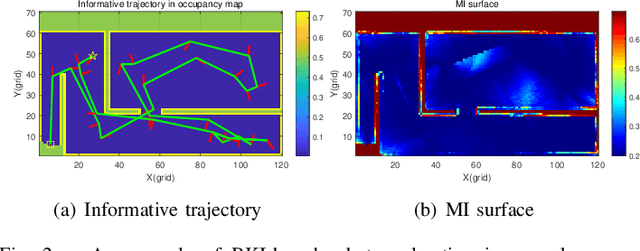
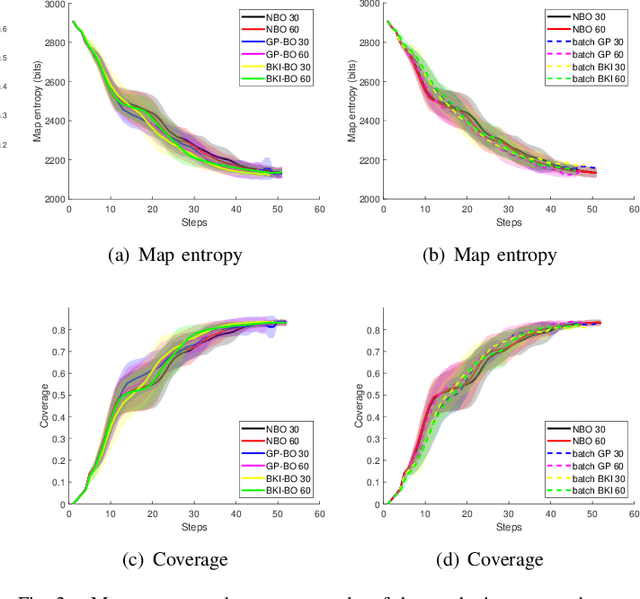
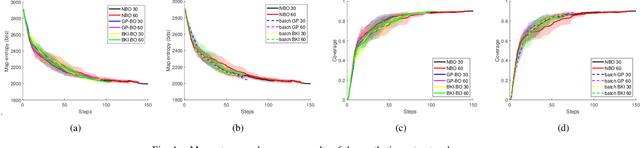
This paper concerns realizing highly efficient information-theoretic robot exploration with desired performance in complex scenes. We build a continuous lightweight inference model to predict the mutual information (MI) and the associated prediction confidence of the robot's candidate actions which have not been evaluated explicitly. This allows the decision-making stage in robot exploration to run with a logarithmic complexity approximately, this will also benefit online exploration in large unstructured, and cluttered places that need more spatial samples to assess and decide. We also develop an objective function to balance the local optimal action with the highest MI value and the global choice with high prediction variance. Extensive numerical and dataset simulations show the desired efficiency of our proposed method without losing exploration performance in different environments. We also provide our open-source implementation codes released on GitHub for the robot community.
Confidence-rich Localization and Mapping based on Particle Filter for Robotic Exploration
Mar 07, 2022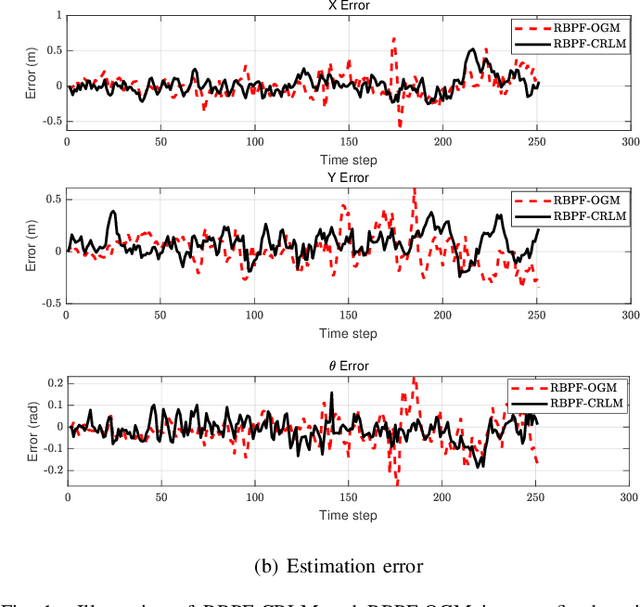
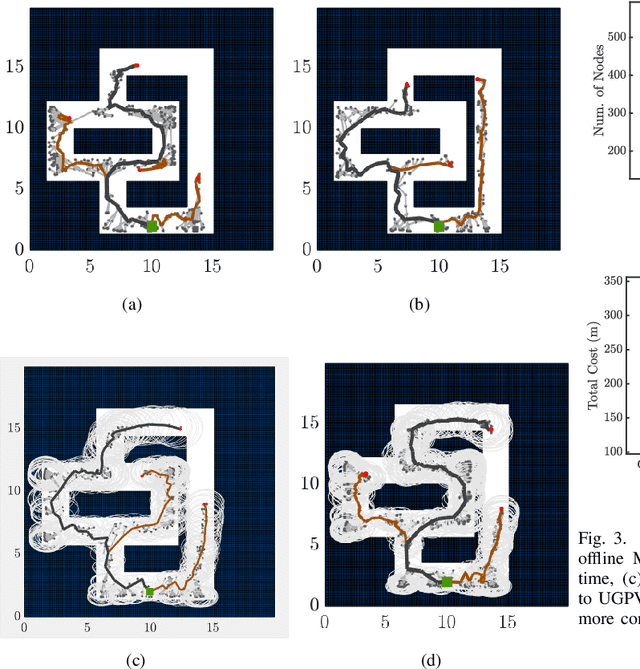
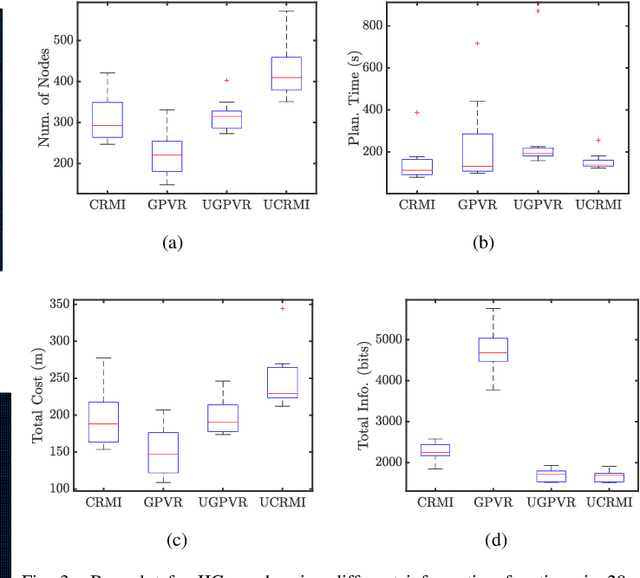
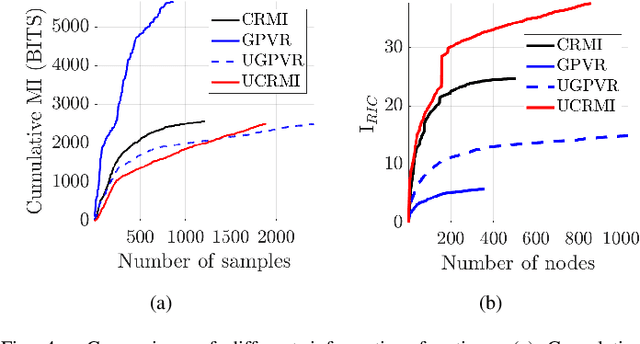
This paper mainly studies the localization and mapping of range sensing robots in the confidence-rich map (CRM), a dense environmental representation with continuous belief, and then extends to information-theoretic exploration to reduce the pose uncertainty. Most previous works about active simultaneous localization and mapping (SLAM) and exploration always assumed the known robot poses or utilized inaccurate information metrics to approximate pose uncertainty, resulting in imbalanced exploration performance and efficiency in the unknown environment. This inspires us to extend the confidence-rich mutual information (CRMI) with measurable pose uncertainty. Specifically, we propose a Rao-Blackwellized particle filter-based localization and mapping scheme (RBPF-CLAM) for CRMs, then we develop a new closed-form weighting method to improve the localization accuracy without scan matching. We further compute the uncertain CRMI (UCRMI) with the weighted particles by a more accurate approximation. Simulations and experimental evaluations show the localization accuracy and exploration performance of the proposed methods in unstructured and confined scenes.
Hierarchical Multi-robot Strategies Synthesis and Optimization under Individual and Collaborative Temporal Logic Specifications
Oct 21, 2021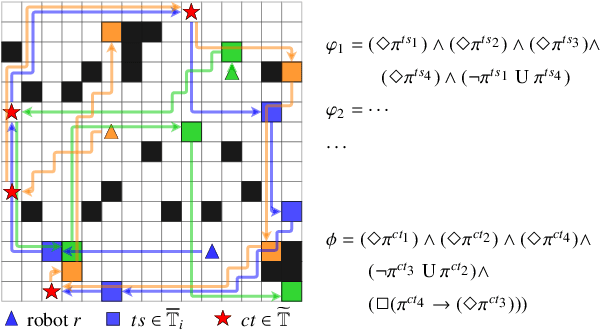
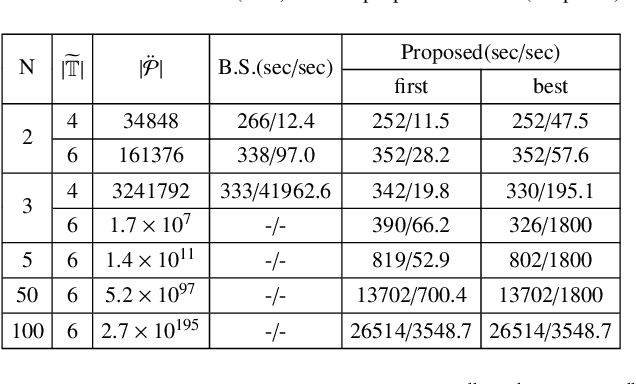
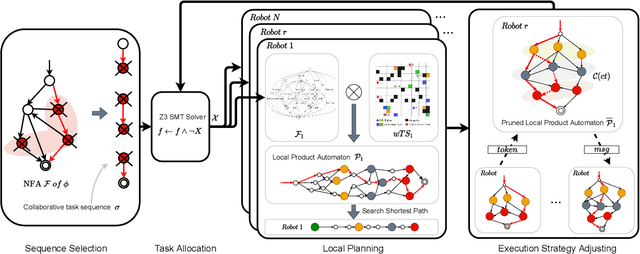

This paper presents a hierarchical framework to solve the multi-robot temporal task planning problem. We assume that each robot has its individual task specification and the robots have to jointly satisfy a global collaborative task specification, both described in linear temporal logic. Specifically, a central server firstly extracts and decomposes a collaborative task sequence from the automaton corresponding to the collaborative task specification, and allocates the subtasks in the sequence to robots. The robots can then synthesize their initial execution strategies based on locally constructed product automatons, combining the assigned collaborative tasks and their individual task specifications. Furthermore, we propose a distributed execution strategy adjusting mechanism to iteratively improve the time efficiency, by reducing wait time in collaborations caused by potential synchronization constraints. We prove the completeness of the proposed framework under assumptions, and analyze its time complexity and optimality. Extensive simulation results verify the scalability and optimization efficiency of the proposed method.
Multi-Robot Task Planning under Individual and Collaborative Temporal Logic Specifications
Aug 27, 2021



This paper investigates the task coordination of multi-robot where each robot has a private individual temporal logic task specification; and also has to jointly satisfy a globally given collaborative temporal logic task specification. To efficiently generate feasible and optimized task execution plans for the robots, we propose a hierarchical multi-robot temporal task planning framework, in which a central server allocates the collaborative tasks to the robots, and then individual robots can independently synthesize their task execution plans in a decentralized manner. Furthermore, we propose an execution plan adjusting mechanism that allows the robots to iteratively modify their execution plans via privacy-preserved inter-agent communication, to improve the expected actual execution performance by reducing waiting time in collaborations for the robots. The correctness and efficiency of the proposed method are analyzed and also verified by extensive simulation experiments.
Integer-Programming-Based Narrow-Passage Multi-Robot Path Planning with Effective Heuristics
Jul 26, 2021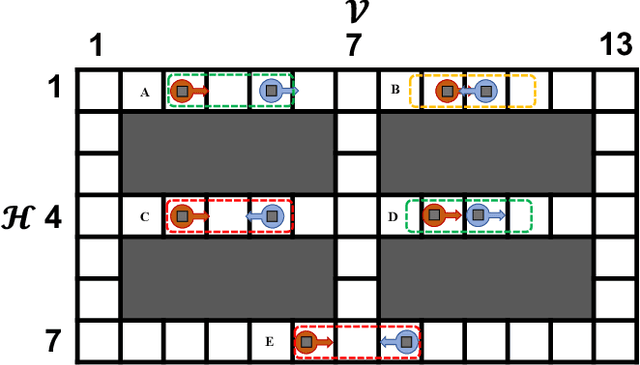
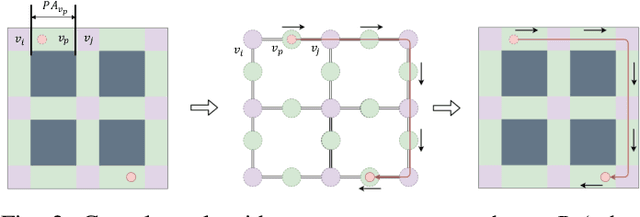
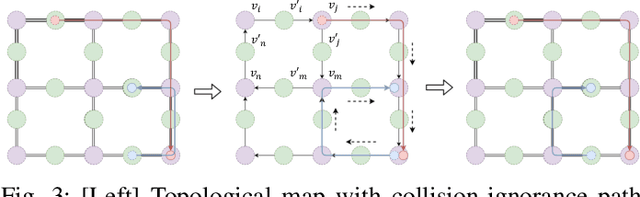
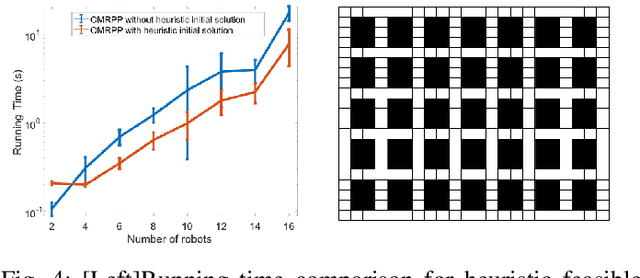
We study optimal Multi-robot Path Planning (MPP) on graphs, in order to improve the efficiency of multi-robot system (MRS) in the warehouse-like environment. We propose a novel algorithm, OMRPP (One-way Multi-robot Path Planning) based on Integer programming (IP) method. We focus on reducing the cost caused by a set of robots moving from their initial configuration to goal configuration in the warehouse-like environment. The novelty of this work includes: (1) proposing a topological map extraction based on the property of warehouse-like environment to reduce the scale of constructed IP model; (2) proposing one-way passage constraint to prevent the robots from having unsolvable collisions in the passage. (3) developing a heuristic architecture that IP model can always have feasible initial solution to ensure its solvability. Numerous simulations demonstrate the efficiency and performance of the proposed algorithm.