 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating dataset harms requires stewardship: Lessons from 1000 papers
Paper and Code
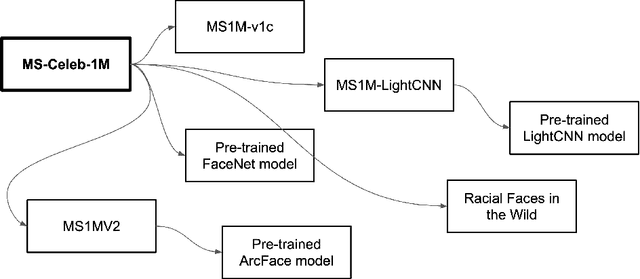


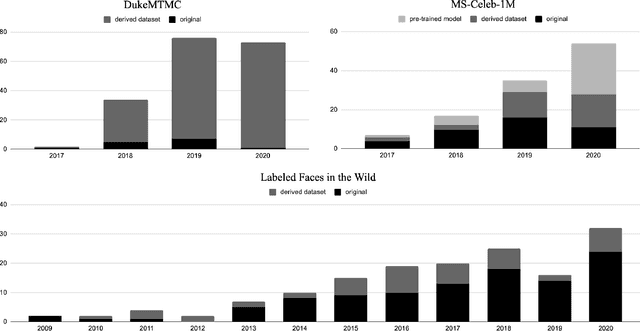
Concerns about privacy, bias, and harmful applications have shone a light on the ethics of machine learning datasets, even leading to the retraction of prominent datasets including DukeMTMC, MS-Celeb-1M, TinyImages, and VGGFace2. In response, the machine learning community has called for higher ethical standards, transparency efforts, and technical fixes in the dataset creation process. The premise of our work is that these efforts can be more effective if informed by an understanding of how datasets are used in practice in the research community. We study three influential face and person recognition datasets - DukeMTMC, MS-Celeb-1M, and Labeled Faces in the Wild (LFW) - by analyzing nearly 1000 papers that cite them. We found that the creation of derivative datasets and models, broader technological and social change, the lack of clarity of licenses, and dataset management practices can introduce a wide range of ethical concerns. We conclude by suggesting a distributed approach that can mitigate these harms, making recommendations to dataset creators, conference program committees, dataset users, and the broader research community.