 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTargeted and Troublesome: Tracking and Advertising on Children's Websites
Aug 09, 2023



On the modern web, trackers and advertisers frequently construct and monetize users' detailed behavioral profiles without consent. Despite various studies on web tracking mechanisms and advertisements, there has been no rigorous study focusing on websites targeted at children. To address this gap, we present a measurement of tracking and (targeted) advertising on websites directed at children. Motivated by lacking a comprehensive list of child-directed (i.e., targeted at children) websites, we first build a multilingual classifier based on web page titles and descriptions. Applying this classifier to over two million pages, we compile a list of two thousand child-directed websites. Crawling these sites from five vantage points, we measure the prevalence of trackers, fingerprinting scripts, and advertisements. Our crawler detects ads displayed on child-directed websites and determines if ad targeting is enabled by scraping ad disclosure pages whenever available. Our results show that around 90% of child-directed websites embed one or more trackers, and about 27% contain targeted advertisements--a practice that should require verifiable parental consent. Next, we identify improper ads on child-directed websites by developing an ML pipeline that processes both images and text extracted from ads. The pipeline allows us to run semantic similarity queries for arbitrary search terms, revealing ads that promote services related to dating, weight loss, and mental health; as well as ads for sex toys and flirting chat services. Some of these ads feature repulsive and sexually explicit imagery. In summary, our findings indicate a trend of non-compliance with privacy regulations and troubling ad safety practices among many advertisers and child-directed websites. To protect children and create a safer online environment, regulators and stakeholders must adopt and enforce more stringent measures.
Mitigating dataset harms requires stewardship: Lessons from 1000 papers
Aug 06, 2021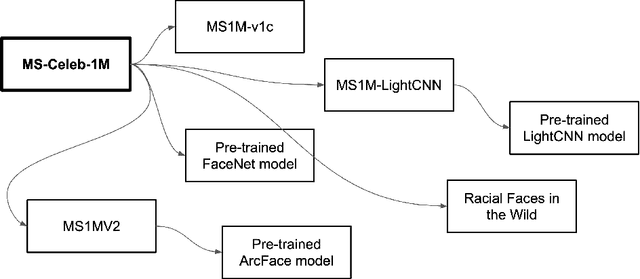


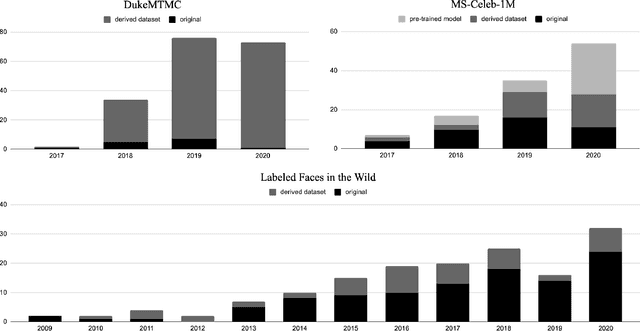
Concerns about privacy, bias, and harmful applications have shone a light on the ethics of machine learning datasets, even leading to the retraction of prominent datasets including DukeMTMC, MS-Celeb-1M, TinyImages, and VGGFace2. In response, the machine learning community has called for higher ethical standards, transparency efforts, and technical fixes in the dataset creation process. The premise of our work is that these efforts can be more effective if informed by an understanding of how datasets are used in practice in the research community. We study three influential face and person recognition datasets - DukeMTMC, MS-Celeb-1M, and Labeled Faces in the Wild (LFW) - by analyzing nearly 1000 papers that cite them. We found that the creation of derivative datasets and models, broader technological and social change, the lack of clarity of licenses, and dataset management practices can introduce a wide range of ethical concerns. We conclude by suggesting a distributed approach that can mitigate these harms, making recommendations to dataset creators, conference program committees, dataset users, and the broader research community.