 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Modeling of Zero-Shot Classifications for Urban Flood Detection
Paper and Code
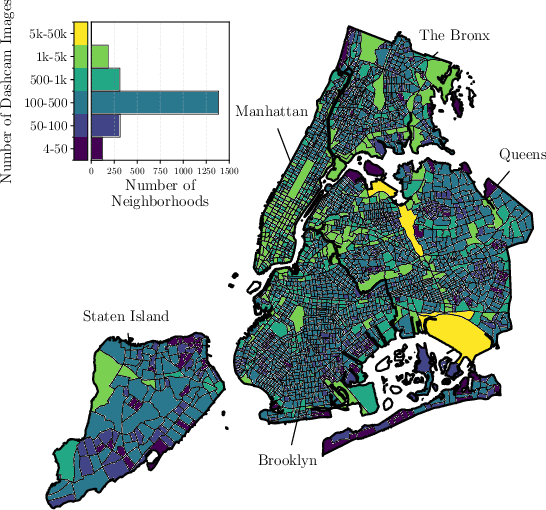
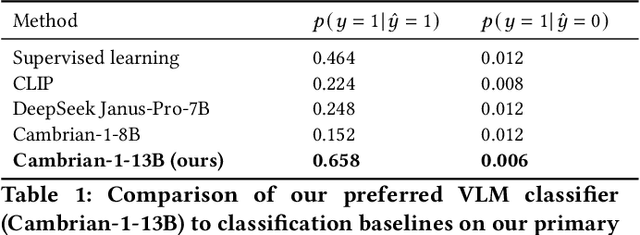

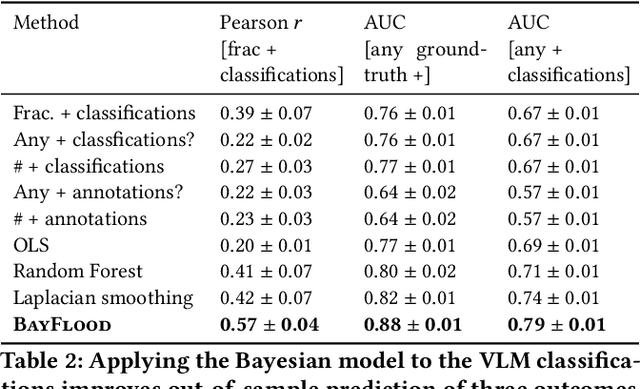
Street scene datasets, collected from Street View or dashboard cameras, offer a promising means of detecting urban objects and incidents like street flooding. However, a major challenge in using these datasets is their lack of reliable labels: there are myriad types of incidents, many types occur rarely, and ground-truth measures of where incidents occur are lacking. Here, we propose BayFlood, a two-stage approach which circumvents this difficulty. First, we perform zero-shot classification of where incidents occur using a pretrained vision-language model (VLM). Second, we fit a spatial Bayesian model on the VLM classifications. The zero-shot approach avoids the need to annotate large training sets, and the Bayesian model provides frequent desiderata in urban settings - principled measures of uncertainty, smoothing across locations, and incorporation of external data like stormwater accumulation zones. We comprehensively validate this two-stage approach, showing that VLMs provide strong zero-shot signal for floods across multiple cities and time periods, the Bayesian model improves out-of-sample prediction relative to baseline methods, and our inferred flood risk correlates with known external predictors of risk. Having validated our approach, we show it can be used to improve urban flood detection: our analysis reveals 113,738 people who are at high risk of flooding overlooked by current methods, identifies demographic biases in existing methods, and suggests locations for new flood sensors. More broadly, our results showcase how Bayesian modeling of zero-shot LM annotations represents a promising paradigm because it avoids the need to collect large labeled datasets and leverages the power of foundation models while providing the expressiveness and uncertainty quantification of Bayesian models.