 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatched Pair Calibration for Ranking Fairness
Jun 20, 2023



We propose a test of fairness in score-based ranking systems called matched pair calibration. Our approach constructs a set of matched item pairs with minimal confounding differences between subgroups before computing an appropriate measure of ranking error over the set. The matching step ensures that we compare subgroup outcomes between identically scored items so that measured performance differences directly imply unfairness in subgroup-level exposures. We show how our approach generalizes the fairness intuitions of calibration from a binary classification setting to ranking and connect our approach to other proposals for ranking fairness measures. Moreover, our strategy shows how the logic of marginal outcome tests extends to cases where the analyst has access to model scores. Lastly, we provide an example of applying matched pair calibration to a real-word ranking data set to demonstrate its efficacy in detecting ranking bias.
Fairness On The Ground: Applying Algorithmic Fairness Approaches to Production Systems
Mar 24, 2021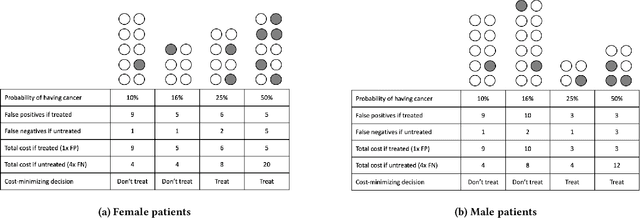
Many technical approaches have been proposed for ensuring that decisions made by machine learning systems are fair, but few of these proposals have been stress-tested in real-world systems. This paper presents an example of one team's approach to the challenge of applying algorithmic fairness approaches to complex production systems within the context of a large technology company. We discuss how we disentangle normative questions of product and policy design (like, "how should the system trade off between different stakeholders' interests and needs?") from empirical questions of system implementation (like, "is the system achieving the desired tradeoff in practice?"). We also present an approach for answering questions of the latter sort, which allows us to measure how machine learning systems and human labelers are making these tradeoffs across different relevant groups. We hope our experience integrating fairness tools and approaches into large-scale and complex production systems will be useful to other practitioners facing similar challenges, and illuminating to academics and researchers looking to better address the needs of practitioners.
Combating Human Trafficking with Deep Multimodal Models
May 08, 2017
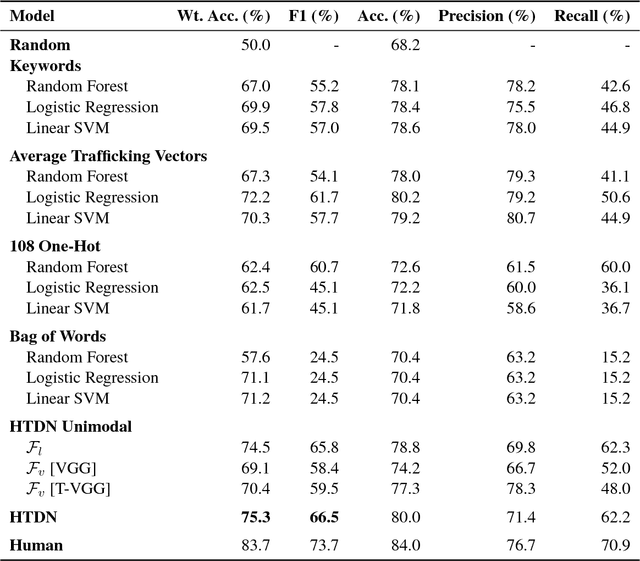
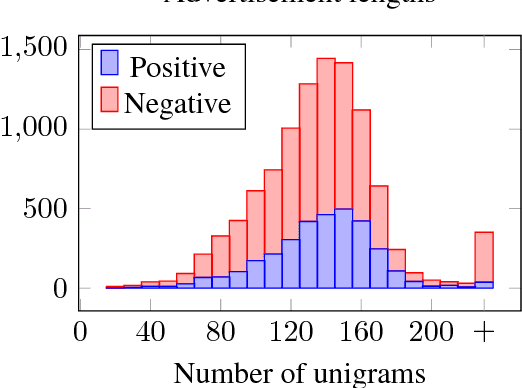
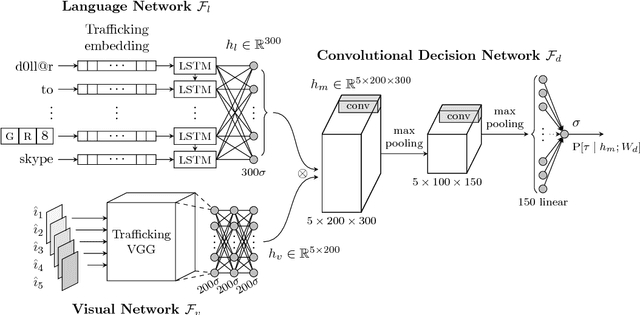
Human trafficking is a global epidemic affecting millions of people across the planet. Sex trafficking, the dominant form of human trafficking, has seen a significant rise mostly due to the abundance of escort websites, where human traffickers can openly advertise among at-will escort advertisements. In this paper, we take a major step in the automatic detection of advertisements suspected to pertain to human trafficking. We present a novel dataset called Trafficking-10k, with more than 10,000 advertisements annotated for this task. The dataset contains two sources of information per advertisement: text and images. For the accurate detection of trafficking advertisements, we designed and trained a deep multimodal model called the Human Trafficking Deep Network (HTDN).