 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuromorphic Keyword Spotting with Pulse Density Modulation MEMS Microphones
Aug 09, 2024The Keyword Spotting (KWS) task involves continuous audio stream monitoring to detect predefined words, requiring low energy devices for continuous processing. Neuromorphic devices effectively address this energy challenge. However, the general neuromorphic KWS pipeline, from microphone to Spiking Neural Network (SNN), entails multiple processing stages. Leveraging the popularity of Pulse Density Modulation (PDM) microphones in modern devices and their similarity to spiking neurons, we propose a direct microphone-to-SNN connection. This approach eliminates intermediate stages, notably reducing computational costs. The system achieved an accuracy of 91.54\% on the Google Speech Command (GSC) dataset, surpassing the state-of-the-art for the Spiking Speech Command (SSC) dataset which is a bio-inspired encoded GSC. Furthermore, the observed sparsity in network activity and connectivity indicates potential for remarkably low energy consumption in a neuromorphic device implementation.
Accelerating SNN Training with Stochastic Parallelizable Spiking Neurons
Jun 22, 2023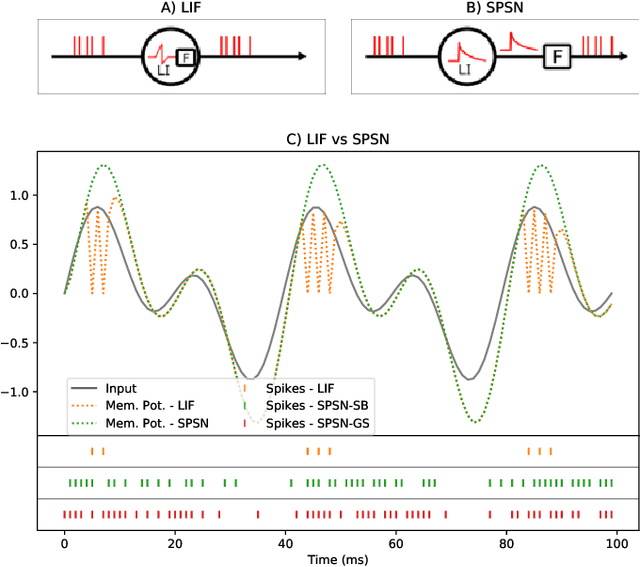
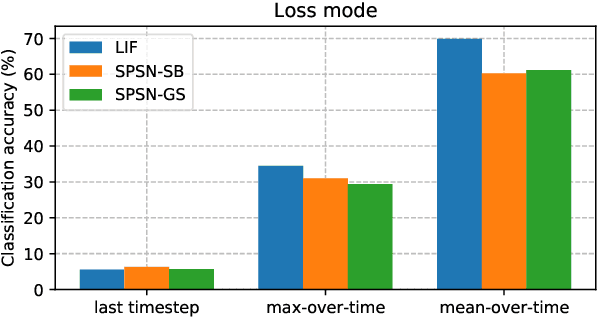
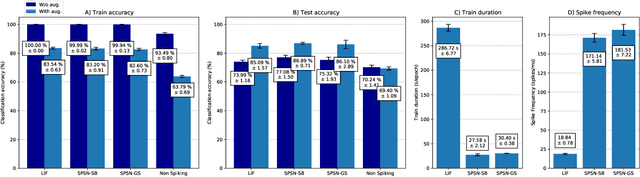
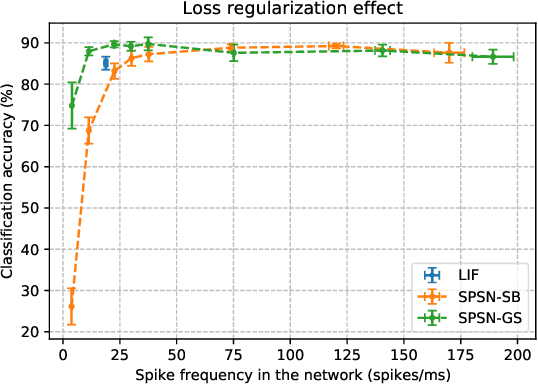
Spiking neural networks (SNN) are able to learn spatiotemporal features while using less energy, especially on neuromorphic hardware. The most widely used spiking neuron in deep learning is the Leaky Integrate and Fire (LIF) neuron. LIF neurons operate sequentially, however, since the computation of state at time t relies on the state at time t-1 being computed. This limitation is shared with Recurrent Neural Networks (RNN) and results in slow training on Graphics Processing Units (GPU). In this paper, we propose the Stochastic Parallelizable Spiking Neuron (SPSN) to overcome the sequential training limitation of LIF neurons. By separating the linear integration component from the non-linear spiking function, SPSN can be run in parallel over time. The proposed approach results in performance comparable with the state-of-the-art for feedforward neural networks on the Spiking Heidelberg Digits (SHD) dataset, outperforming LIF networks while training 10 times faster and outperforming non-spiking networks with the same network architecture. For longer input sequences of 10000 time-steps, we show that the proposed approach results in 4000 times faster training, thus demonstrating the potential of the proposed approach to accelerate SNN training for very large datasets.
Hardware-aware Training Techniques for Improving Robustness of Ex-Situ Neural Network Transfer onto Passive TiO2 ReRAM Crossbars
May 29, 2023



Passive resistive random access memory (ReRAM) crossbar arrays, a promising emerging technology used for analog matrix-vector multiplications, are far superior to their active (1T1R) counterparts in terms of the integration density. However, current transfers of neural network weights into the conductance state of the memory devices in the crossbar architecture are accompanied by significant losses in precision due to hardware variabilities such as sneak path currents, biasing scheme effects and conductance tuning imprecision. In this work, training approaches that adapt techniques such as dropout, the reparametrization trick and regularization to TiO2 crossbar variabilities are proposed in order to generate models that are better adapted to their hardware transfers. The viability of this approach is demonstrated by comparing the outputs and precision of the proposed hardware-aware network with those of a regular fully connected network over a few thousand weight transfers using the half moons dataset in a simulation based on experimental data. For the neural network trained using the proposed hardware-aware method, 79.5% of the test set's data points can be classified with an accuracy of 95% or higher, while only 18.5% of the test set's data points can be classified with this accuracy by the regularly trained neural network.
Efficient spike encoding algorithms for neuromorphic speech recognition
Jul 14, 2022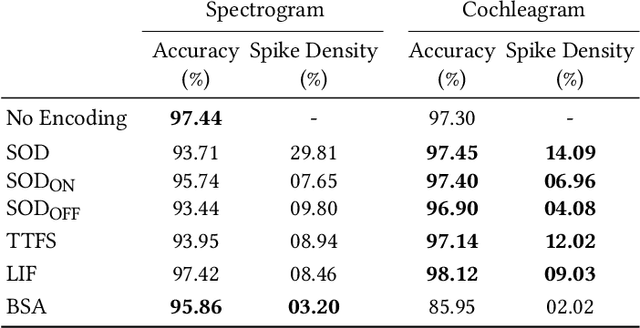
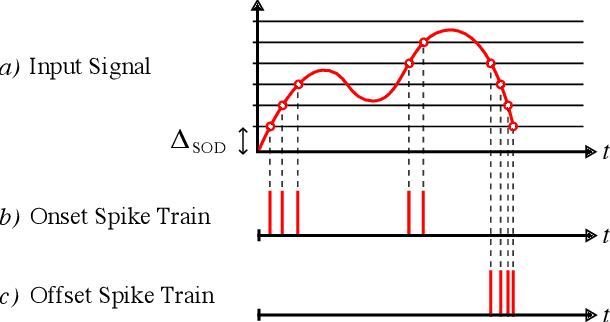

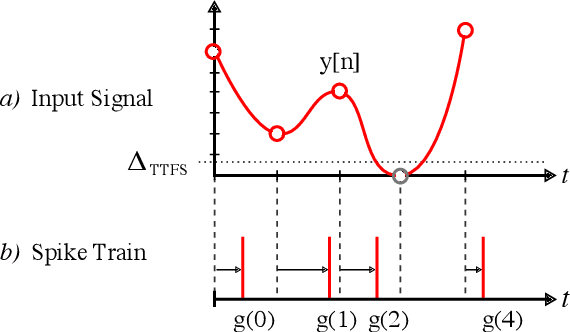
Spiking Neural Networks (SNN) are known to be very effective for neuromorphic processor implementations, achieving orders of magnitude improvements in energy efficiency and computational latency over traditional deep learning approaches. Comparable algorithmic performance was recently made possible as well with the adaptation of supervised training algorithms to the context of SNN. However, information including audio, video, and other sensor-derived data are typically encoded as real-valued signals that are not well-suited to SNN, preventing the network from leveraging spike timing information. Efficient encoding from real-valued signals to spikes is therefore critical and significantly impacts the performance of the overall system. To efficiently encode signals into spikes, both the preservation of information relevant to the task at hand as well as the density of the encoded spikes must be considered. In this paper, we study four spike encoding methods in the context of a speaker independent digit classification system: Send on Delta, Time to First Spike, Leaky Integrate and Fire Neuron and Bens Spiker Algorithm. We first show that all encoding methods yield higher classification accuracy using significantly fewer spikes when encoding a bio-inspired cochleagram as opposed to a traditional short-time Fourier transform. We then show that two Send On Delta variants result in classification results comparable with a state of the art deep convolutional neural network baseline, while simultaneously reducing the encoded bit rate. Finally, we show that several encoding methods result in improved performance over the conventional deep learning baseline in certain cases, further demonstrating the power of spike encoding algorithms in the encoding of real-valued signals and that neuromorphic implementation has the potential to outperform state of the art techniques.
Robust learning from corrupted EEG with dynamic spatial filtering
May 27, 2021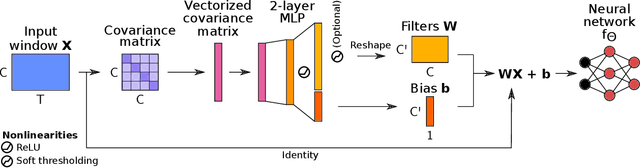
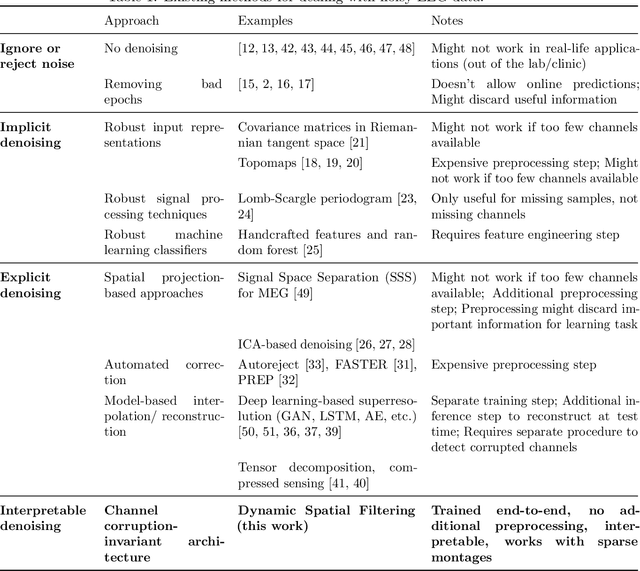
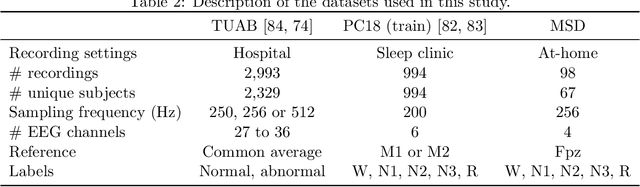
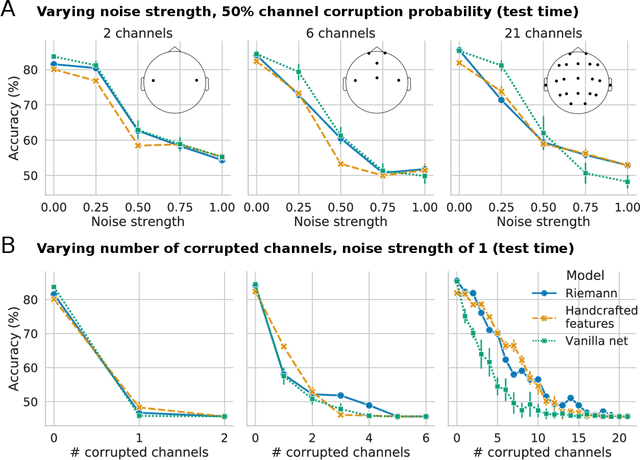
Building machine learning models using EEG recorded outside of the laboratory setting requires methods robust to noisy data and randomly missing channels. This need is particularly great when working with sparse EEG montages (1-6 channels), often encountered in consumer-grade or mobile EEG devices. Neither classical machine learning models nor deep neural networks trained end-to-end on EEG are typically designed or tested for robustness to corruption, and especially to randomly missing channels. While some studies have proposed strategies for using data with missing channels, these approaches are not practical when sparse montages are used and computing power is limited (e.g., wearables, cell phones). To tackle this problem, we propose dynamic spatial filtering (DSF), a multi-head attention module that can be plugged in before the first layer of a neural network to handle missing EEG channels by learning to focus on good channels and to ignore bad ones. We tested DSF on public EEG data encompassing ~4,000 recordings with simulated channel corruption and on a private dataset of ~100 at-home recordings of mobile EEG with natural corruption. Our proposed approach achieves the same performance as baseline models when no noise is applied, but outperforms baselines by as much as 29.4% accuracy when significant channel corruption is present. Moreover, DSF outputs are interpretable, making it possible to monitor channel importance in real-time. This approach has the potential to enable the analysis of EEG in challenging settings where channel corruption hampers the reading of brain signals.