 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust learning from corrupted EEG with dynamic spatial filtering
May 27, 2021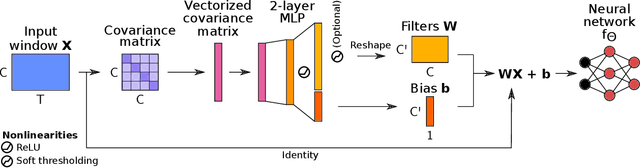
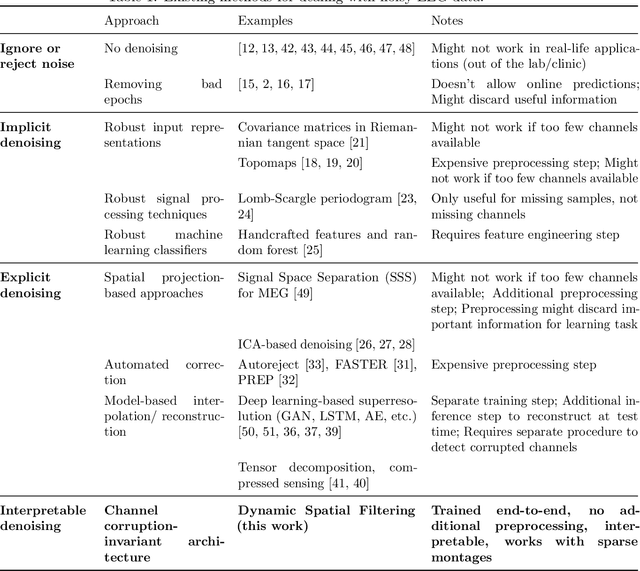
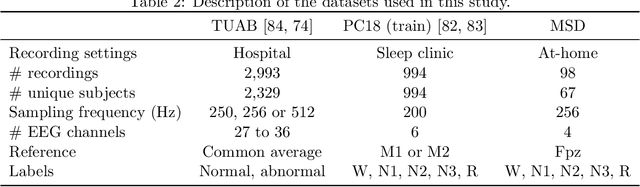
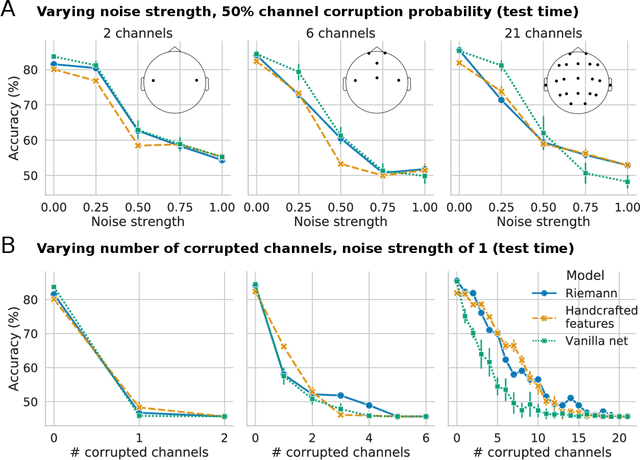
Building machine learning models using EEG recorded outside of the laboratory setting requires methods robust to noisy data and randomly missing channels. This need is particularly great when working with sparse EEG montages (1-6 channels), often encountered in consumer-grade or mobile EEG devices. Neither classical machine learning models nor deep neural networks trained end-to-end on EEG are typically designed or tested for robustness to corruption, and especially to randomly missing channels. While some studies have proposed strategies for using data with missing channels, these approaches are not practical when sparse montages are used and computing power is limited (e.g., wearables, cell phones). To tackle this problem, we propose dynamic spatial filtering (DSF), a multi-head attention module that can be plugged in before the first layer of a neural network to handle missing EEG channels by learning to focus on good channels and to ignore bad ones. We tested DSF on public EEG data encompassing ~4,000 recordings with simulated channel corruption and on a private dataset of ~100 at-home recordings of mobile EEG with natural corruption. Our proposed approach achieves the same performance as baseline models when no noise is applied, but outperforms baselines by as much as 29.4% accuracy when significant channel corruption is present. Moreover, DSF outputs are interpretable, making it possible to monitor channel importance in real-time. This approach has the potential to enable the analysis of EEG in challenging settings where channel corruption hampers the reading of brain signals.
Uncovering the structure of clinical EEG signals with self-supervised learning
Jul 31, 2020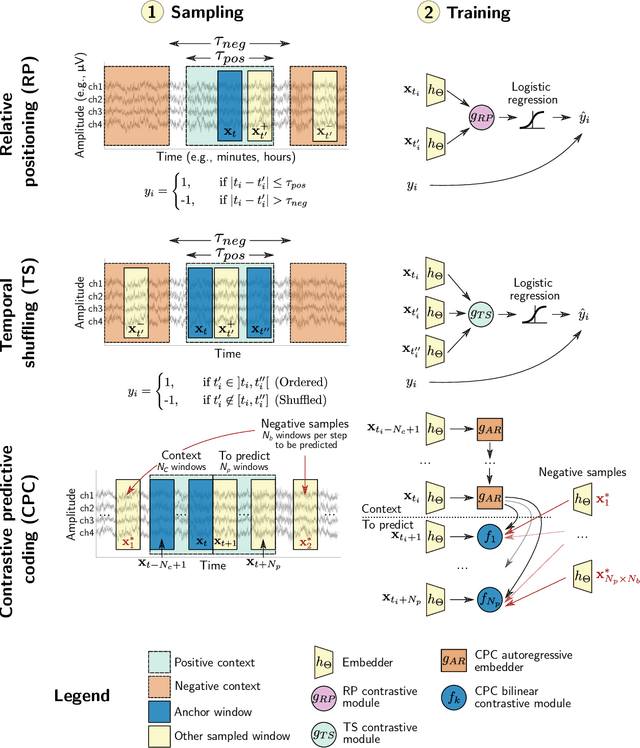
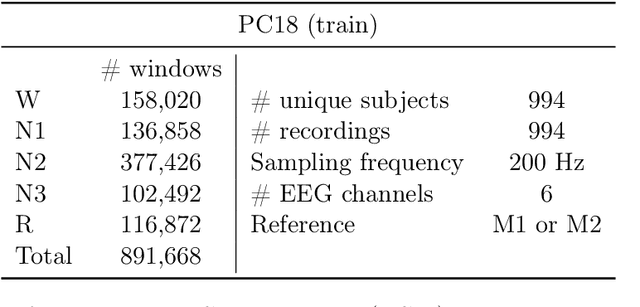


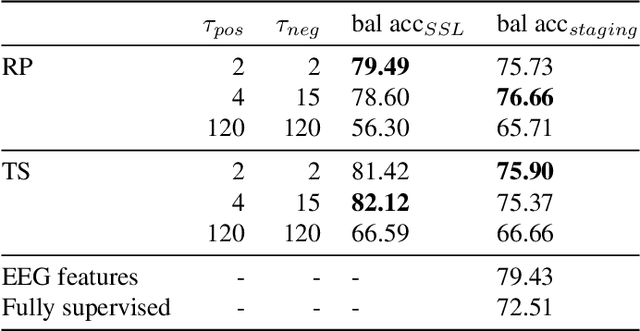
Objective. Supervised learning paradigms are often limited by the amount of labeled data that is available. This phenomenon is particularly problematic in clinically-relevant data, such as electroencephalography (EEG), where labeling can be costly in terms of specialized expertise and human processing time. Consequently, deep learning architectures designed to learn on EEG data have yielded relatively shallow models and performances at best similar to those of traditional feature-based approaches. However, in most situations, unlabeled data is available in abundance. By extracting information from this unlabeled data, it might be possible to reach competitive performance with deep neural networks despite limited access to labels. Approach. We investigated self-supervised learning (SSL), a promising technique for discovering structure in unlabeled data, to learn representations of EEG signals. Specifically, we explored two tasks based on temporal context prediction as well as contrastive predictive coding on two clinically-relevant problems: EEG-based sleep staging and pathology detection. We conducted experiments on two large public datasets with thousands of recordings and performed baseline comparisons with purely supervised and hand-engineered approaches. Main results. Linear classifiers trained on SSL-learned features consistently outperformed purely supervised deep neural networks in low-labeled data regimes while reaching competitive performance when all labels were available. Additionally, the embeddings learned with each method revealed clear latent structures related to physiological and clinical phenomena, such as age effects. Significance. We demonstrate the benefit of self-supervised learning approaches on EEG data. Our results suggest that SSL may pave the way to a wider use of deep learning models on EEG data.
Self-supervised representation learning from electroencephalography signals
Nov 13, 2019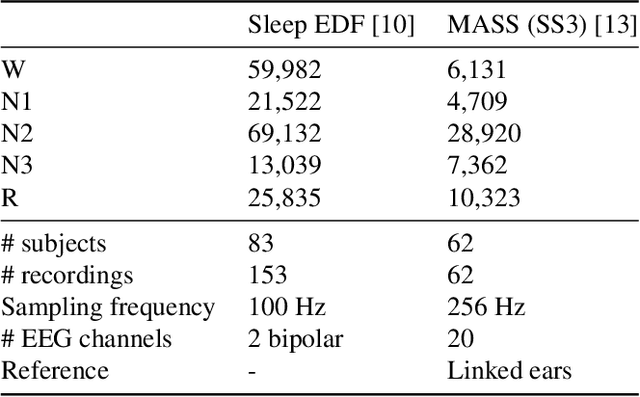


The supervised learning paradigm is limited by the cost - and sometimes the impracticality - of data collection and labeling in multiple domains. Self-supervised learning, a paradigm which exploits the structure of unlabeled data to create learning problems that can be solved with standard supervised approaches, has shown great promise as a pretraining or feature learning approach in fields like computer vision and time series processing. In this work, we present self-supervision strategies that can be used to learn informative representations from multivariate time series. One successful approach relies on predicting whether time windows are sampled from the same temporal context or not. As demonstrated on a clinically relevant task (sleep scoring) and with two electroencephalography datasets, our approach outperforms a purely supervised approach in low data regimes, while capturing important physiological information without any access to labels.