 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Central Frequencies Locally Competitive Algorithm for Speech
Feb 10, 2025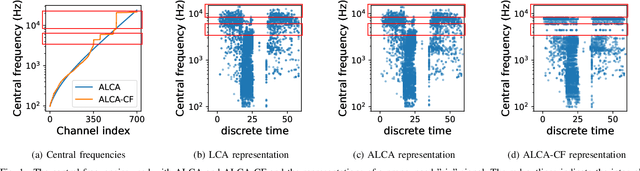
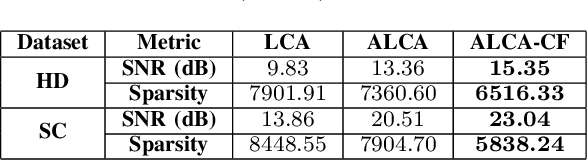
Neuromorphic computing, inspired by nervous systems, revolutionizes information processing with its focus on efficiency and low power consumption. Using sparse coding, this paradigm enhances processing efficiency, which is crucial for edge devices with power constraints. The Locally Competitive Algorithm (LCA), adapted for audio with Gammatone and Gammachirp filter banks, provides an efficient sparse coding method for neuromorphic speech processing. Adaptive LCA (ALCA) further refines this method by dynamically adjusting modulation parameters, thereby improving reconstruction quality and sparsity. This paper introduces an enhanced ALCA version, the ALCA Central Frequency (ALCA-CF), which dynamically adapts both modulation parameters and central frequencies, optimizing the speech representation. Evaluations show that this approach improves reconstruction quality and sparsity while significantly reducing the power consumption of speech classification, without compromising classification accuracy, particularly on Intel's Loihi 2 neuromorphic chip.
Maximizing Information in Neuron Populations for Neuromorphic Spike Encoding
Dec 11, 2024



Neuromorphic applications emulate the processing performed by the brain by using spikes as inputs instead of time-varying analog stimuli. Therefore, these time-varying stimuli have to be encoded into spikes, which can induce important information loss. To alleviate this loss, some studies use population coding strategies to encode more information using a population of neurons rather than just one neuron. However, configuring the encoding parameters of such a population is an open research question. This work proposes an approach based on maximizing the mutual information between the signal and the spikes in the population of neurons. The proposed algorithm is inspired by the information-theoretic framework of Partial Information Decomposition. Two applications are presented: blood pressure pulse wave classification, and neural action potential waveform classification. In both tasks, the data is encoded into spikes and the encoding parameters of the neuron populations are tuned to maximize the encoded information using the proposed algorithm. The spikes are then classified and the performance is measured using classification accuracy as a metric. Two key results are reported. Firstly, adding neurons to the population leads to an increase in both mutual information and classification accuracy beyond what could be accounted for by each neuron separately, showing the usefulness of population coding strategies. Secondly, the classification accuracy obtained with the tuned parameters is near-optimal and it closely follows the mutual information as more neurons are added to the population. Furthermore, the proposed approach significantly outperforms random parameter selection, showing the usefulness of the proposed approach. These results are reproduced in both applications.
Efficient Sparse Coding with the Adaptive Locally Competitive Algorithm for Speech Classification
Sep 12, 2024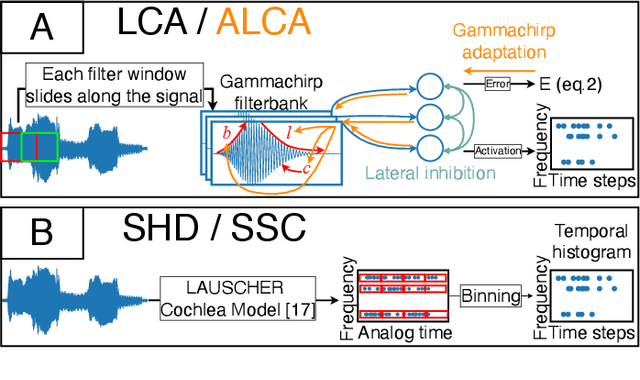
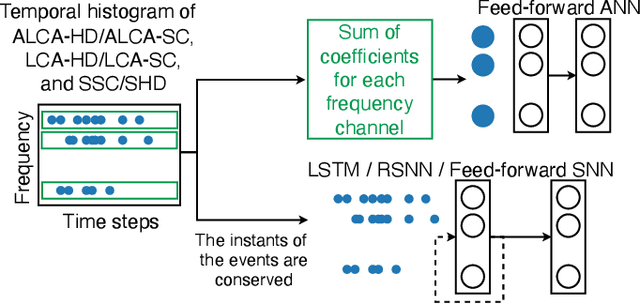
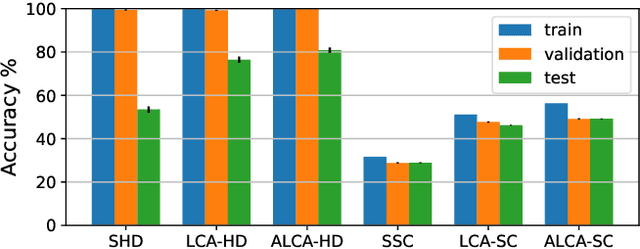
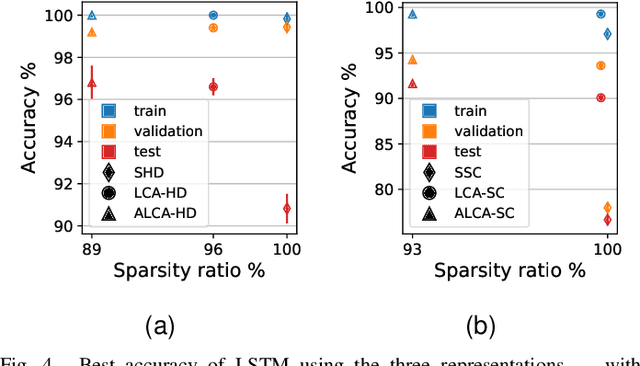
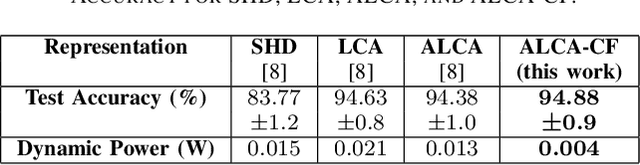
Researchers are exploring novel computational paradigms such as sparse coding and neuromorphic computing to bridge the efficiency gap between the human brain and conventional computers in complex tasks. A key area of focus is neuromorphic audio processing. While the Locally Competitive Algorithm has emerged as a promising solution for sparse coding, offering potential for real-time and low-power processing on neuromorphic hardware, its applications in neuromorphic speech classification have not been thoroughly studied. The Adaptive Locally Competitive Algorithm builds upon the Locally Competitive Algorithm by dynamically adjusting the modulation parameters of the filter bank to fine-tune the filters' sensitivity. This adaptability enhances lateral inhibition, improving reconstruction quality, sparsity, and convergence time, which is crucial for real-time applications. This paper demonstrates the potential of the Locally Competitive Algorithm and its adaptive variant as robust feature extractors for neuromorphic speech classification. Results show that the Locally Competitive Algorithm achieves better speech classification accuracy at the expense of higher power consumption compared to the LAUSCHER cochlea model used for benchmarking. On the other hand, the Adaptive Locally Competitive Algorithm mitigates this power consumption issue without compromising the accuracy. The dynamic power consumption is reduced to a range of 0.004 to 13 milliwatts on neuromorphic hardware, three orders of magnitude less than setups using Graphics Processing Units. These findings position the Adaptive Locally Competitive Algorithm as a compelling solution for efficient speech classification systems, promising substantial advancements in balancing speech classification accuracy and power efficiency.
Classification of auditory stimuli from EEG signals with a regulated recurrent neural network reservoir
Apr 27, 2018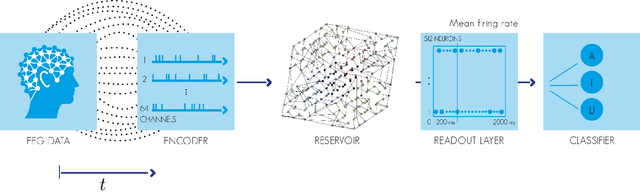
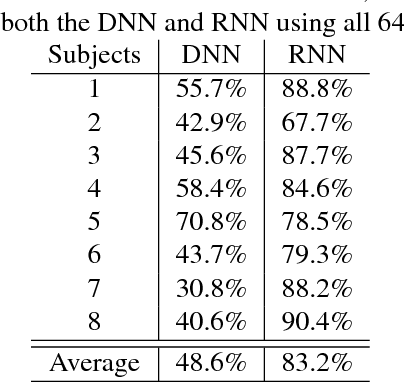
The use of electroencephalogram (EEG) as the main input signal in brain-machine interfaces has been widely proposed due to the non-invasive nature of the EEG. Here we are specifically interested in interfaces that extract information from the auditory system and more specifically in the task of classifying heard speech from EEGs. To do so, we propose to limit the preprocessing of the EEGs and use machine learning approaches to automatically extract their meaningful characteristics. More specifically, we use a regulated recurrent neural network (RNN) reservoir, which has been shown to outperform classic machine learning approaches when applied to several different bio-signals, and we compare it with a deep neural network approach. Moreover, we also investigate the classification performance as a function of the number of EEG electrodes. A set of 8 subjects were presented randomly with 3 different auditory stimuli (English vowels a, i and u). We obtained an excellent classification rate of 83.2% with the RNN when considering all 64 electrodes. A rate of 81.7% was achieved with only 10 electrodes.