 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Objective Algorithms for Learning Open-Ended Robotic Problems
Nov 11, 2024
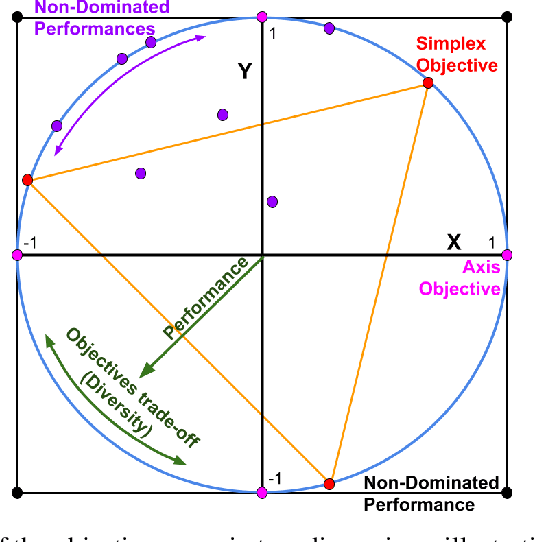
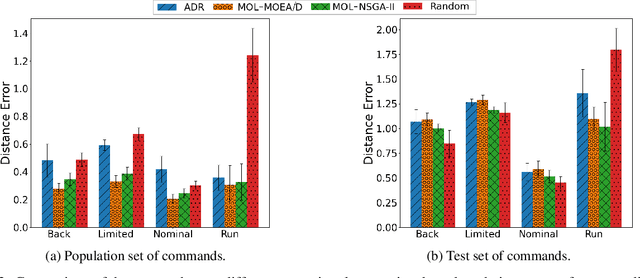
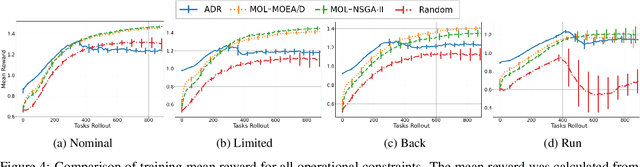
Quadrupedal locomotion is a complex, open-ended problem vital to expanding autonomous vehicle reach. Traditional reinforcement learning approaches often fall short due to training instability and sample inefficiency. We propose a novel method leveraging multi-objective evolutionary algorithms as an automatic curriculum learning mechanism, which we named Multi-Objective Learning (MOL). Our approach significantly enhances the learning process by projecting velocity commands into an objective space and optimizing for both performance and diversity. Tested within the MuJoCo physics simulator, our method demonstrates superior stability and adaptability compared to baseline approaches. As such, it achieved 19\% and 44\% fewer errors against our best baseline algorithm in difficult scenarios based on a uniform and tailored evaluation respectively. This work introduces a robust framework for training quadrupedal robots, promising significant advancements in robotic locomotion and open-ended robotic problems.
AriEL: volume coding for sentence generation
Apr 21, 2020



Mapping sequences of discrete data to a point in a continuous space makes it difficult to retrieve those sequences via random sampling. Mapping the input to a volume would make it easier to retrieve at test time, and that's the strategy followed by the family of approaches based on Variational Autoencoder. However the fact that they are at the same time optimizing for prediction and for smoothness of representation, forces them to trade-off between the two. We improve on the performance of some of the standard methods in deep learning to generate sentences by uniformly sampling a continuous space. We do it by proposing AriEL, that constructs volumes in a continuous space, without the need of encouraging the creation of volumes through the loss function. We first benchmark on a toy grammar, that allows to automatically evaluate the language learned and generated by the models. Then, we benchmark on a real dataset of human dialogues. Our results indicate that the random access to the stored information is dramatically improved, and our method AriEL is able to generate a wider variety of correct language by randomly sampling the latent space. VAE follows in performance for the toy dataset while, AE and Transformer follow for the real dataset. This partially supports to the hypothesis that encoding information into volumes instead of into points, can lead to improved retrieval of learned information with random sampling. This can lead to better generators and we also discuss potential disadvantages.
Language coverage and generalization in RNN-based continuous sentence embeddings for interacting agents
Nov 05, 2019


Continuous sentence embeddings using recurrent neural networks (RNNs), where variable-length sentences are encoded into fixed-dimensional vectors, are often the main building blocks of architectures applied to language tasks such as dialogue generation. While it is known that those embeddings are able to learn some structures of language (e.g. grammar) in a purely data-driven manner, there is very little work on the objective evaluation of their ability to cover the whole language space and to generalize to sentences outside the language bias of the training data. Using a manually designed context-free grammar (CFG) to generate a large-scale dataset of sentences related to the content of realistic 3D indoor scenes, we evaluate the language coverage and generalization abilities of the most common continuous sentence embeddings based on RNNs. We also propose a new embedding method based on arithmetic coding, AriEL, that is not data-driven and that efficiently encodes in continuous space any sentence from the CFG. We find that RNN-based embeddings underfit the training data and cover only a small subset of the language defined by the CFG. They also fail to learn the underlying CFG and generalize to unbiased sentences from that same CFG. We found that AriEL provides an insightful baseline.
Classification of auditory stimuli from EEG signals with a regulated recurrent neural network reservoir
Apr 27, 2018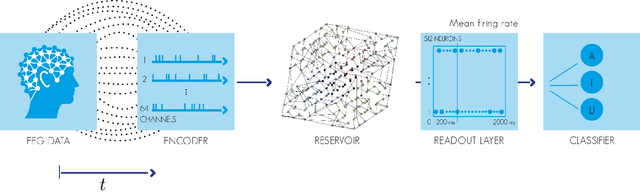
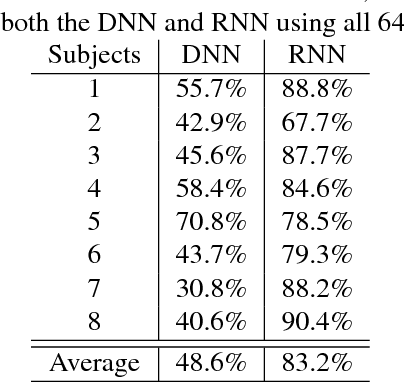
The use of electroencephalogram (EEG) as the main input signal in brain-machine interfaces has been widely proposed due to the non-invasive nature of the EEG. Here we are specifically interested in interfaces that extract information from the auditory system and more specifically in the task of classifying heard speech from EEGs. To do so, we propose to limit the preprocessing of the EEGs and use machine learning approaches to automatically extract their meaningful characteristics. More specifically, we use a regulated recurrent neural network (RNN) reservoir, which has been shown to outperform classic machine learning approaches when applied to several different bio-signals, and we compare it with a deep neural network approach. Moreover, we also investigate the classification performance as a function of the number of EEG electrodes. A set of 8 subjects were presented randomly with 3 different auditory stimuli (English vowels a, i and u). We obtained an excellent classification rate of 83.2% with the RNN when considering all 64 electrodes. A rate of 81.7% was achieved with only 10 electrodes.
CREATE: Multimodal Dataset for Unsupervised Learning, Generative Modeling and Prediction of Sensory Data from a Mobile Robot in Indoor Environments
Jan 30, 2018



The CREATE database is composed of 14 hours of multimodal recordings from a mobile robotic platform based on the iRobot Create. The various sensors cover vision, audition, motors and proprioception. The dataset has been designed in the context of a mobile robot that can learn multimodal representations of its environment, thanks to its ability to navigate the environment. This ability can also be used to learn the dependencies and relationships between the different modalities of the robot (e.g. vision, audition), as they reflect both the external environment and the internal state of the robot. The provided multimodal dataset is expected to have multiple usages, such as multimodal unsupervised object learning, multimodal prediction and egomotion/causality detection.
HoME: a Household Multimodal Environment
Nov 29, 2017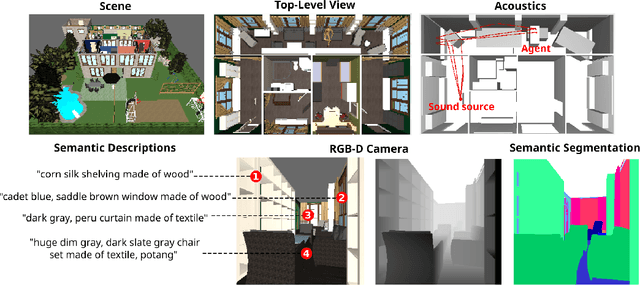


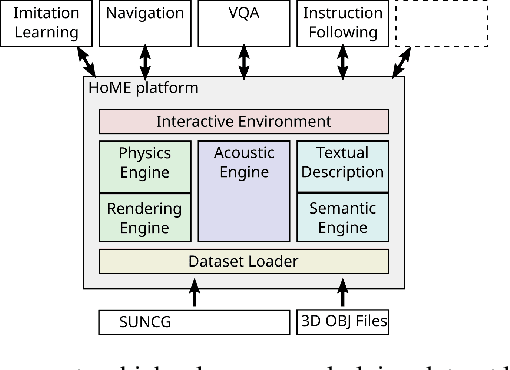
We introduce HoME: a Household Multimodal Environment for artificial agents to learn from vision, audio, semantics, physics, and interaction with objects and other agents, all within a realistic context. HoME integrates over 45,000 diverse 3D house layouts based on the SUNCG dataset, a scale which may facilitate learning, generalization, and transfer. HoME is an open-source, OpenAI Gym-compatible platform extensible to tasks in reinforcement learning, language grounding, sound-based navigation, robotics, multi-agent learning, and more. We hope HoME better enables artificial agents to learn as humans do: in an interactive, multimodal, and richly contextualized setting.