 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAriEL: volume coding for sentence generation
Apr 21, 2020



Mapping sequences of discrete data to a point in a continuous space makes it difficult to retrieve those sequences via random sampling. Mapping the input to a volume would make it easier to retrieve at test time, and that's the strategy followed by the family of approaches based on Variational Autoencoder. However the fact that they are at the same time optimizing for prediction and for smoothness of representation, forces them to trade-off between the two. We improve on the performance of some of the standard methods in deep learning to generate sentences by uniformly sampling a continuous space. We do it by proposing AriEL, that constructs volumes in a continuous space, without the need of encouraging the creation of volumes through the loss function. We first benchmark on a toy grammar, that allows to automatically evaluate the language learned and generated by the models. Then, we benchmark on a real dataset of human dialogues. Our results indicate that the random access to the stored information is dramatically improved, and our method AriEL is able to generate a wider variety of correct language by randomly sampling the latent space. VAE follows in performance for the toy dataset while, AE and Transformer follow for the real dataset. This partially supports to the hypothesis that encoding information into volumes instead of into points, can lead to improved retrieval of learned information with random sampling. This can lead to better generators and we also discuss potential disadvantages.
Language coverage and generalization in RNN-based continuous sentence embeddings for interacting agents
Nov 05, 2019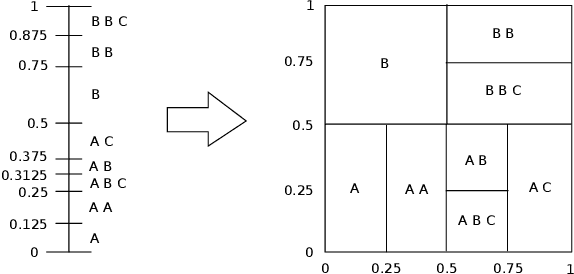


Continuous sentence embeddings using recurrent neural networks (RNNs), where variable-length sentences are encoded into fixed-dimensional vectors, are often the main building blocks of architectures applied to language tasks such as dialogue generation. While it is known that those embeddings are able to learn some structures of language (e.g. grammar) in a purely data-driven manner, there is very little work on the objective evaluation of their ability to cover the whole language space and to generalize to sentences outside the language bias of the training data. Using a manually designed context-free grammar (CFG) to generate a large-scale dataset of sentences related to the content of realistic 3D indoor scenes, we evaluate the language coverage and generalization abilities of the most common continuous sentence embeddings based on RNNs. We also propose a new embedding method based on arithmetic coding, AriEL, that is not data-driven and that efficiently encodes in continuous space any sentence from the CFG. We find that RNN-based embeddings underfit the training data and cover only a small subset of the language defined by the CFG. They also fail to learn the underlying CFG and generalize to unbiased sentences from that same CFG. We found that AriEL provides an insightful baseline.
HoME: a Household Multimodal Environment
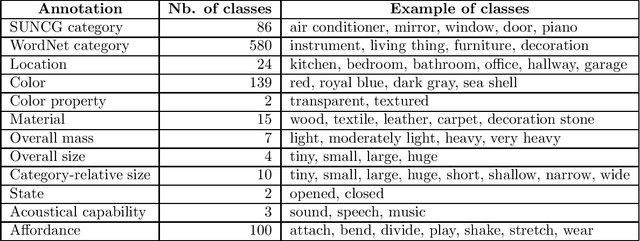
Nov 29, 2017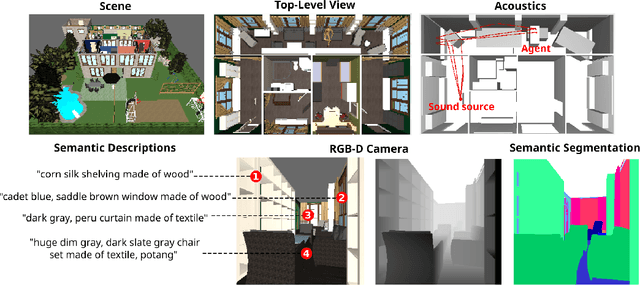


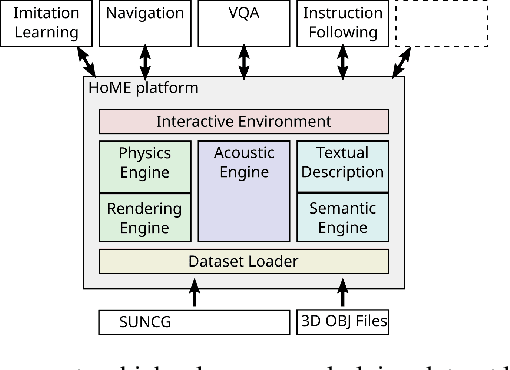
We introduce HoME: a Household Multimodal Environment for artificial agents to learn from vision, audio, semantics, physics, and interaction with objects and other agents, all within a realistic context. HoME integrates over 45,000 diverse 3D house layouts based on the SUNCG dataset, a scale which may facilitate learning, generalization, and transfer. HoME is an open-source, OpenAI Gym-compatible platform extensible to tasks in reinforcement learning, language grounding, sound-based navigation, robotics, multi-agent learning, and more. We hope HoME better enables artificial agents to learn as humans do: in an interactive, multimodal, and richly contextualized setting.