 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNAAQA: A Neural Architecture for Acoustic Question Answering
Jun 11, 2021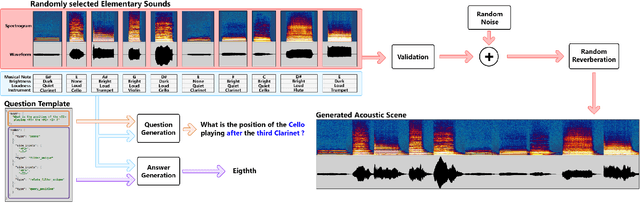

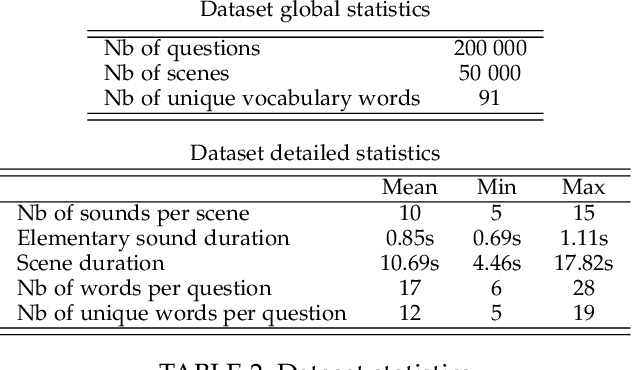
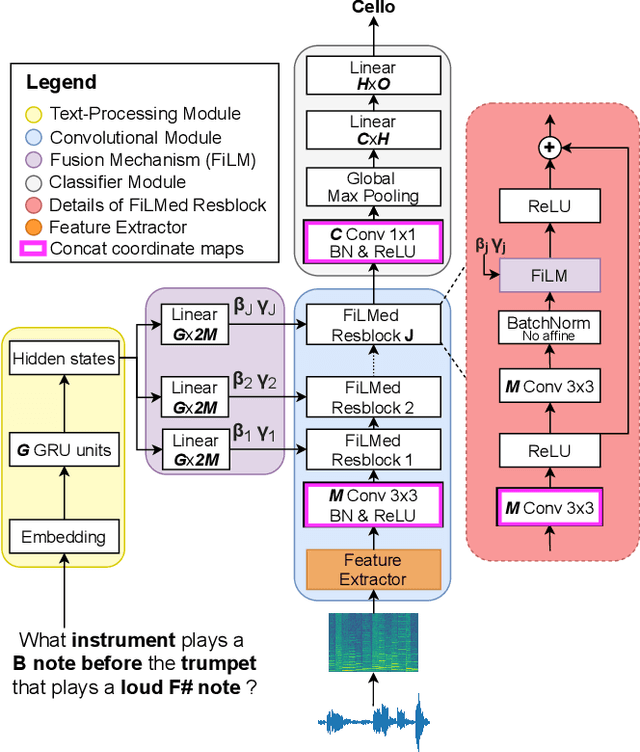
The goal of the Acoustic Question Answering (AQA) task is to answer a free-form text question about the content of an acoustic scene. It was inspired by the Visual Question Answering (VQA) task. In this paper, based on the previously introduced CLEAR dataset, we propose a new benchmark for AQA that emphasizes the specific challenges of acoustic inputs, e.g. variable duration scenes. We also introduce NAAQA, a neural architecture that leverages specific properties of acoustic inputs. The usage of time and frequency 1D convolutions to process 2D spectro-temporal representations of acoustic content shows promising results and enables reductions in model complexity. NAAQA achieves 91.6% of accuracy on the AQA task with about 7 times fewer parameters than the previously explored VQA model. We provide a detailed analysis of the results for the different question types. The effectiveness of coordinate maps in this acoustic context was also studied and we show that time coordinate maps augment temporal localization capabilities which enhance performance of the network by about 17 percentage points.
From Visual to Acoustic Question Answering
Feb 28, 2019

We introduce the new task of Acoustic Question Answering (AQA) to promote research in acoustic reasoning. The AQA task consists of analyzing an acoustic scene composed by a combination of elementary sounds and answering questions that relate the position and properties of these sounds. The kind of relational questions asked, require that the models perform non-trivial reasoning in order to answer correctly. Although similar problems have been extensively studied in the domain of visual reasoning, we are not aware of any previous studies addressing the problem in the acoustic domain. We propose a method for generating the acoustic scenes from elementary sounds and a number of relevant questions for each scene using templates. We also present preliminary results obtained with two models (FiLM and MAC) that have been shown to work for visual reasoning.
CLEAR: A Dataset for Compositional Language and Elementary Acoustic Reasoning
Nov 26, 2018
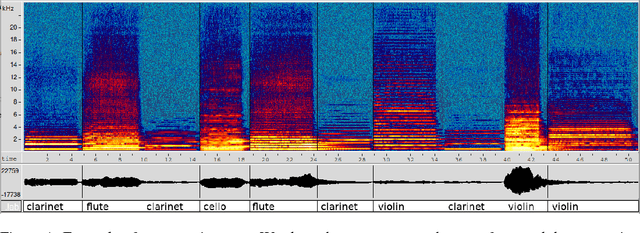


We introduce the task of acoustic question answering (AQA) in the area of acoustic reasoning. In this task an agent learns to answer questions on the basis of acoustic context. In order to promote research in this area, we propose a data generation paradigm adapted from CLEVR (Johnson et al. 2017). We generate acoustic scenes by leveraging a bank elementary sounds. We also provide a number of functional programs that can be used to compose questions and answers that exploit the relationships between the attributes of the elementary sounds in each scene. We provide AQA datasets of various sizes as well as the data generation code. As a preliminary experiment to validate our data, we report the accuracy of current state of the art visual question answering models when they are applied to the AQA task without modifications. Although there is a plethora of question answering tasks based on text, image or video data, to our knowledge, we are the first to propose answering questions directly on audio streams. We hope this contribution will facilitate the development of research in the area.