 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNAAQA: A Neural Architecture for Acoustic Question Answering
Paper and Code
Jun 11, 2021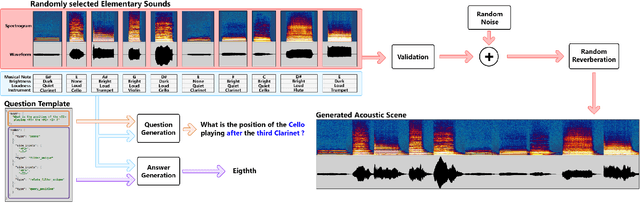

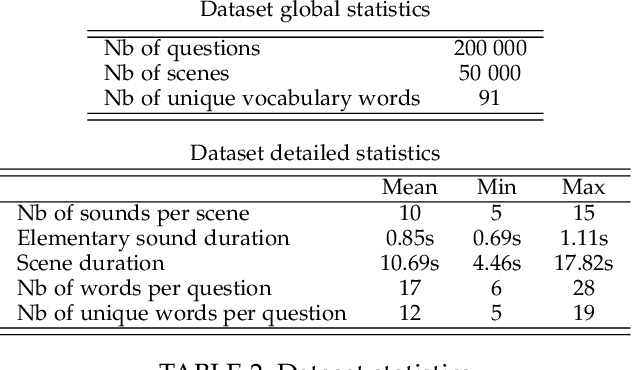
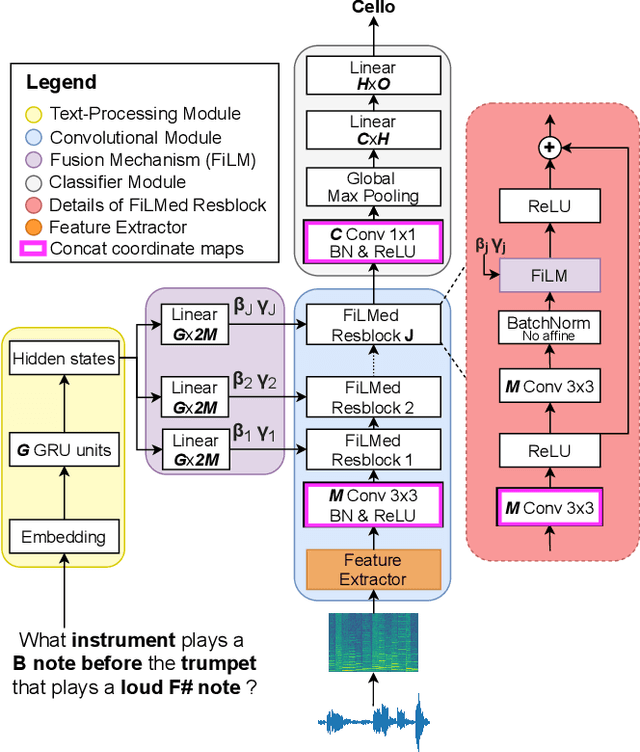
The goal of the Acoustic Question Answering (AQA) task is to answer a free-form text question about the content of an acoustic scene. It was inspired by the Visual Question Answering (VQA) task. In this paper, based on the previously introduced CLEAR dataset, we propose a new benchmark for AQA that emphasizes the specific challenges of acoustic inputs, e.g. variable duration scenes. We also introduce NAAQA, a neural architecture that leverages specific properties of acoustic inputs. The usage of time and frequency 1D convolutions to process 2D spectro-temporal representations of acoustic content shows promising results and enables reductions in model complexity. NAAQA achieves 91.6% of accuracy on the AQA task with about 7 times fewer parameters than the previously explored VQA model. We provide a detailed analysis of the results for the different question types. The effectiveness of coordinate maps in this acoustic context was also studied and we show that time coordinate maps augment temporal localization capabilities which enhance performance of the network by about 17 percentage points.